Preference Aligned Visuomotor Diffusion Policies for Deformable Object Manipulation
作者: Marco Moletta, Michael C. Welle, Danica Kragic
分类: cs.RO
发布日期: 2026-02-10
💡 一句话要点
提出RKO方法,利用少量演示对预训练扩散策略进行偏好对齐,提升机器人对可变形物体操作的个性化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 偏好学习 视觉运动策略 扩散模型 可变形物体操作 机器人操作 人机协作 策略优化
📋 核心要点
- 现有机器人操作方法难以捕捉人类微妙且个性化的操作偏好,尤其是在处理可变形物体时。
- 论文提出RKO方法,结合RPO和KTO的优势,通过少量演示对预训练的视觉运动扩散策略进行偏好对齐。
- 实验表明,RKO在真实世界的叠布任务中,相比于其他偏好学习框架和基线方法,实现了更好的性能和样本效率。
📝 摘要(中文)
人类在操作任务中会自然而然地形成偏好,这些偏好通常是微妙的、个性化的且难以表达的。虽然机器人考虑这些偏好对于提高个性化和用户满意度非常重要,但它们在机器人操作中,特别是在服装和织物等可变形物体的操作中,仍然很大程度上未被探索。本文研究了如何使用有限的演示来调整预训练的视觉运动扩散策略,以反映偏好的行为。我们引入了RKO,一种新颖的偏好对齐方法,它结合了RPO和KTO这两个最新框架的优点。我们在跨越多个服装和偏好设置的真实世界叠布任务中,针对包括这两个框架以及基线 vanilla 扩散策略在内的常见偏好学习框架评估了RKO。结果表明,与标准扩散策略微调相比,偏好对齐的策略(特别是RKO)实现了卓越的性能和样本效率。这些结果突出了结构化偏好学习在复杂可变形物体操作任务中扩展个性化机器人行为的重要性和可行性。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,特别是可变形物体操作中,如何让机器人学习并适应人类的个性化操作偏好这一问题。现有方法通常难以捕捉这些微妙的偏好,导致机器人操作缺乏灵活性和个性化,用户体验不佳。此外,直接从头训练策略成本高昂,且难以泛化到新的任务和物体上。
核心思路:论文的核心思路是利用预训练的视觉运动扩散策略作为基础,然后通过少量的人类演示数据,对策略进行微调,使其能够反映人类的偏好。RKO方法的核心在于结合了RPO(Reward-Prior Optimization)和KTO(Kullback-Leibler Trust Region Optimization)的优点,从而在保证策略性能的同时,避免过度拟合和策略崩溃。
技术框架:整体框架包含以下几个主要步骤:1) 使用扩散模型预训练一个通用的视觉运动策略,使其能够完成基本的物体操作任务。2) 收集少量的人类演示数据,这些数据反映了人类对特定任务的偏好。3) 使用RKO方法,基于预训练的策略和人类演示数据,对策略进行微调,使其能够生成符合人类偏好的动作。RKO方法本身包含两个主要部分:RPO用于学习一个奖励函数,该奖励函数能够区分符合人类偏好的动作和不符合人类偏好的动作;KTO用于约束策略的更新,避免策略偏离预训练的策略太远。
关键创新:RKO的关键创新在于其结合了RPO和KTO的优点。RPO能够有效地学习奖励函数,从而区分不同的偏好,而KTO能够保证策略的稳定性和泛化能力。与单独使用RPO或KTO相比,RKO能够更好地平衡性能和稳定性,从而实现更好的偏好对齐效果。此外,RKO方法只需要少量的演示数据,这使得其在实际应用中更加可行。
关键设计:RKO方法中的RPO部分使用了一个神经网络来学习奖励函数,该神经网络的输入是机器人的状态和动作,输出是一个标量值,表示该动作的奖励。KTO部分使用KL散度来衡量策略的差异,并使用Trust Region方法来约束策略的更新。具体的参数设置包括奖励函数的网络结构、KL散度的系数、Trust Region的大小等。这些参数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
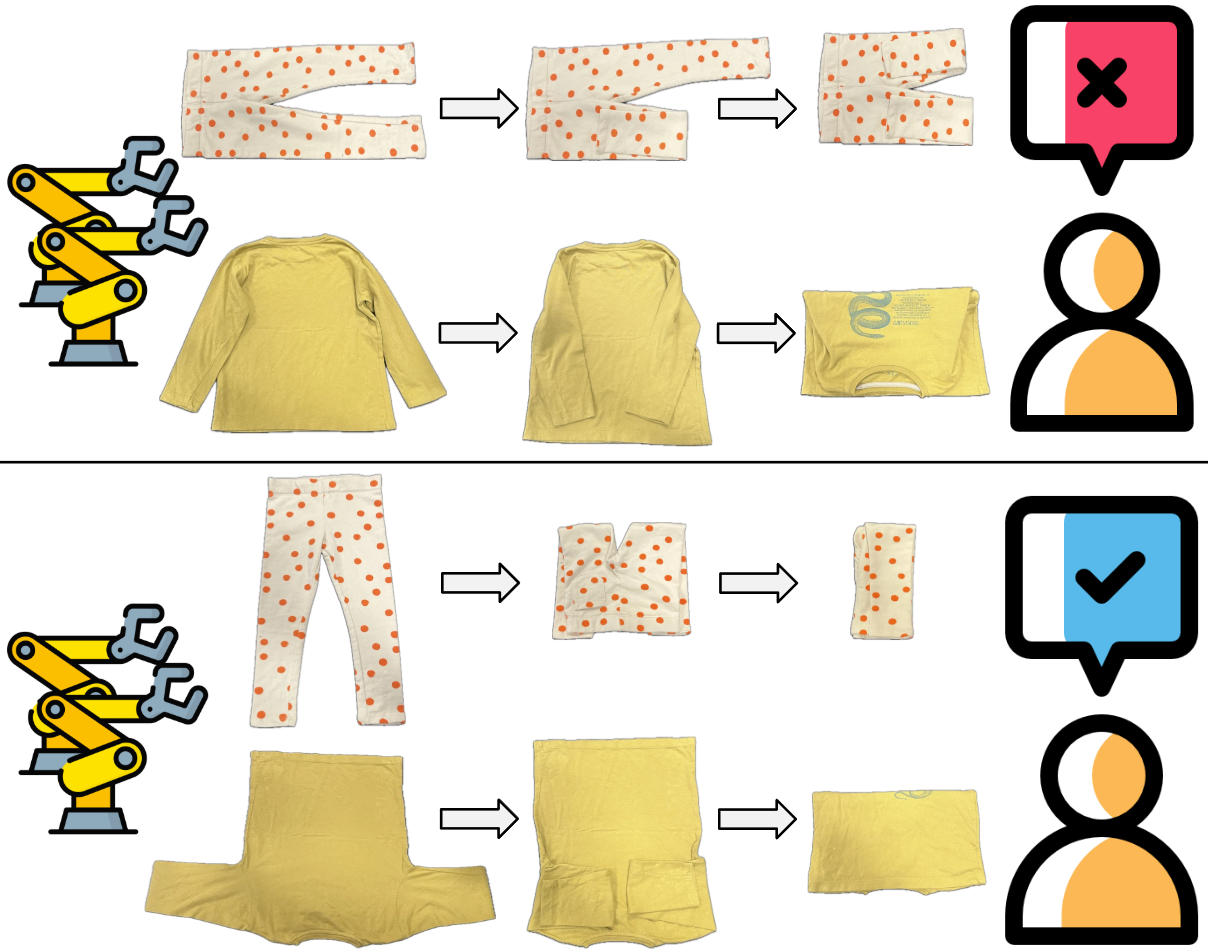


📊 实验亮点
实验结果表明,RKO方法在真实世界的叠布任务中,相比于基线方法(vanilla diffusion policy)和其他偏好学习框架(RPO、KTO),实现了显著的性能提升和样本效率提升。具体而言,RKO方法能够更快地学习到符合人类偏好的策略,并且能够更好地泛化到新的服装和偏好设置上。量化指标显示,RKO在成功率和操作效率上均优于其他方法。
🎯 应用场景
该研究成果可应用于各种需要个性化机器人操作的场景,例如:服装定制、家居整理、医疗康复等。通过学习用户的操作偏好,机器人可以更好地完成任务,提高用户满意度,并最终实现人机协作的智能化和个性化。
📄 摘要(原文)
Humans naturally develop preferences for how manipulation tasks should be performed, which are often subtle, personal, and difficult to articulate. Although it is important for robots to account for these preferences to increase personalization and user satisfaction, they remain largely underexplored in robotic manipulation, particularly in the context of deformable objects like garments and fabrics. In this work, we study how to adapt pretrained visuomotor diffusion policies to reflect preferred behaviors using limited demonstrations. We introduce RKO, a novel preference-alignment method that combines the benefits of two recent frameworks: RPO and KTO. We evaluate RKO against common preference learning frameworks, including these two, as well as a baseline vanilla diffusion policy, on real-world cloth-folding tasks spanning multiple garments and preference settings. We show that preference-aligned policies (particularly RKO) achieve superior performance and sample efficiency compared to standard diffusion policy fine-tuning. These results highlight the importance and feasibility of structured preference learning for scaling personalized robot behavior in complex deformable object manipulation tasks.