Sample-Efficient Real-World Dexterous Policy Fine-Tuning via Action-Chunked Critics and Normalizing Flows
作者: Chenyu Yang, Denis Tarasov, Davide Liconti, Hehui Zheng, Robert K. Katzschmann
分类: cs.RO, cs.LG
发布日期: 2026-02-10
💡 一句话要点
SOFT-FLOW:基于Normalizing Flow和分块Critic的真实世界灵巧策略高效微调
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧操作 策略微调 Normalizing Flow 动作分块 离线学习
📋 核心要点
- 真实世界灵巧操作策略微调面临样本效率低和动作分布多模态的挑战,现有方法难以兼顾。
- SOFT-FLOW利用Normalizing Flow对动作块建模,实现精确似然计算,并结合分块Critic进行价值评估。
- 实验表明,SOFT-FLOW在真实机器人任务中实现了稳定且高效的策略自适应,优于标准方法。
📝 摘要(中文)
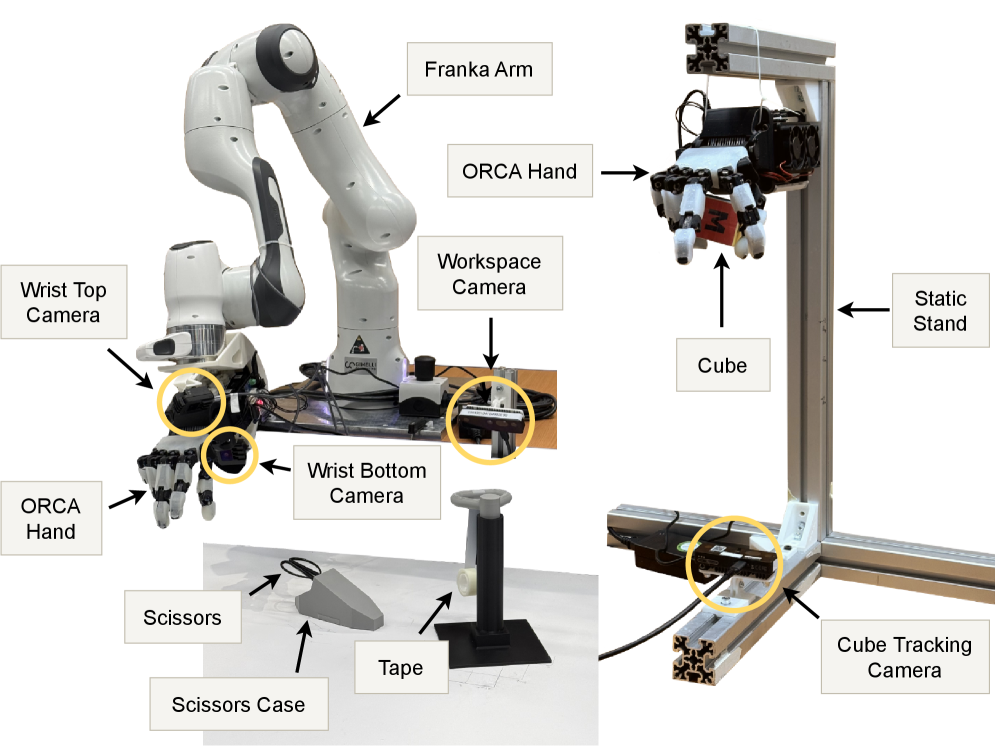
由于真实世界交互预算有限以及高度多模态的动作分布,灵巧操作策略的真实世界微调仍然具有挑战性。基于扩散的策略虽然具有表达性,但由于动作概率难以处理,因此不允许在微调期间进行保守的基于似然的更新。相比之下,传统的Gaussian策略在多模态下会崩溃,尤其是在动作分块执行时,并且标准的分步critic无法与分块执行对齐,导致不良的信用分配。我们提出了SOFT-FLOW,一个具有Normalizing Flow (NF) 的高效离线微调框架,以应对这些挑战。Normalizing Flow策略为多模态动作块产生精确的似然,允许通过似然正则化进行保守、稳定的策略更新,从而提高样本效率。动作分块critic评估整个动作序列,使价值估计与策略的时间结构对齐,并改善长时程信用分配。据我们所知,这是首次在真实机器人硬件上演示基于似然的多模态生成策略与块级别价值学习的结合。我们在两个具有挑战性的真实世界灵巧操作任务上评估了SOFT-FLOW:用从盒子中取出的剪刀剪胶带,以及用手掌向下的抓握方式进行手中立方体旋转——这两者都需要在很长的时间范围内进行精确、灵巧的控制。在这些任务中,SOFT-FLOW实现了稳定、高效的自适应,而标准方法则难以实现。
🔬 方法详解
问题定义:论文旨在解决真实世界灵巧操作策略微调中样本效率低下的问题。现有方法,如基于扩散模型的策略,难以进行保守的似然更新;而高斯策略在处理多模态动作分布时容易崩溃,尤其是在动作分块执行的情况下。此外,传统的分步critic无法有效评估分块动作序列,导致信用分配不准确。
核心思路:SOFT-FLOW的核心思路是利用Normalizing Flow (NF) 对动作块的概率分布进行建模,从而能够精确计算动作序列的似然。这使得可以进行基于似然正则化的保守策略更新,提高样本效率。同时,采用动作分块critic来评估整个动作序列,从而更好地进行信用分配。
技术框架:SOFT-FLOW框架包含以下主要模块:1) Normalizing Flow策略:用于生成动作序列,并提供精确的似然计算;2) 动作分块Critic:用于评估整个动作序列的价值,提供更准确的信用分配;3) 离线策略优化算法:利用离线数据进行策略微调,通过似然正则化保证策略更新的稳定性。整体流程是,首先利用离线数据训练NF策略和分块Critic,然后利用策略梯度方法进行策略微调,并使用似然正则化防止策略崩溃。
关键创新:SOFT-FLOW的关键创新在于将Normalizing Flow策略与动作分块Critic相结合,实现了真实世界灵巧操作策略的高效微调。这是首次在真实机器人硬件上演示基于似然的多模态生成策略与块级别价值学习的结合。与现有方法相比,SOFT-FLOW能够更好地处理多模态动作分布,并提供更准确的信用分配。
关键设计:Normalizing Flow策略使用一系列可逆变换将一个简单的分布(如高斯分布)转换为复杂的动作分布。动作分块Critic的网络结构需要能够处理变长的动作序列,可以使用循环神经网络(RNN)或Transformer等结构。损失函数包括策略梯度损失和似然正则化损失,其中似然正则化损失用于约束策略的更新幅度,防止策略崩溃。具体参数设置需要根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
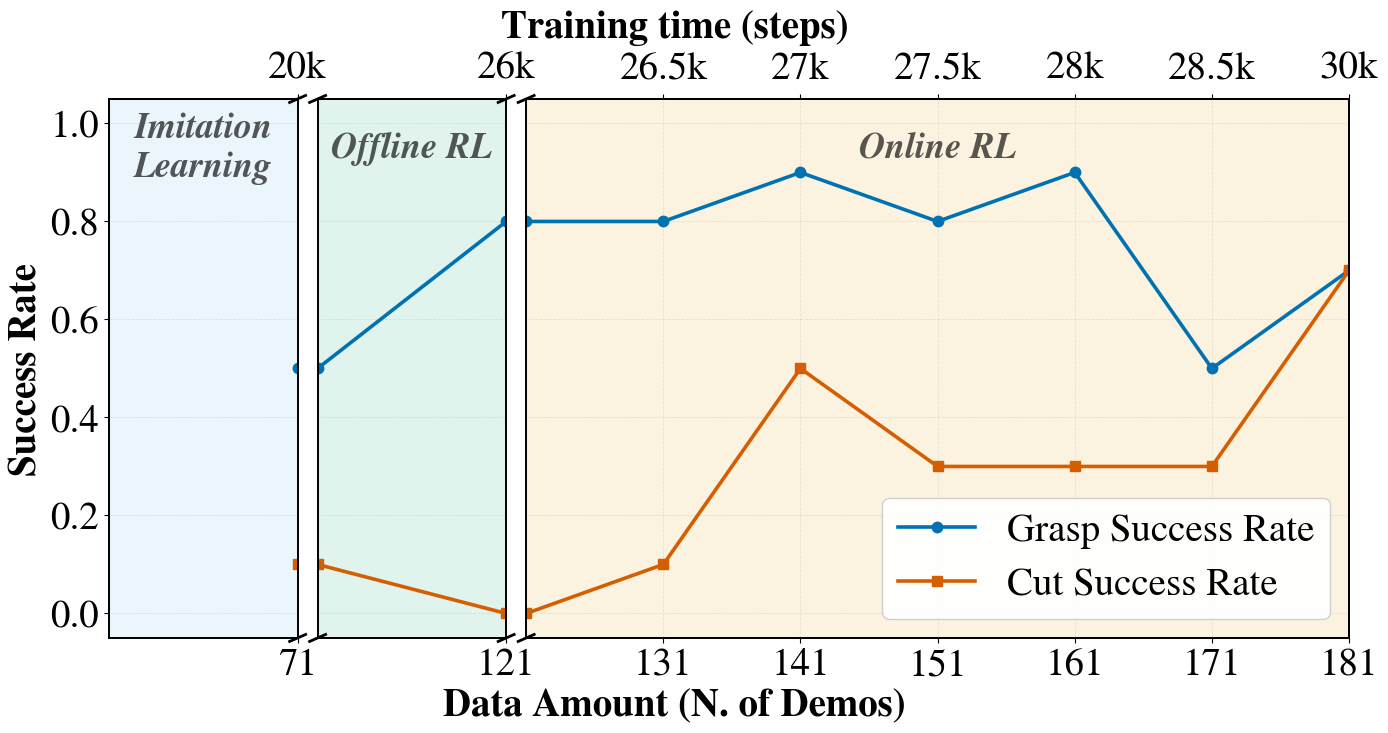
SOFT-FLOW在真实世界的剪胶带和立方体旋转任务上进行了评估,实验结果表明,SOFT-FLOW能够实现稳定且高效的策略自适应,优于标准方法。具体性能数据未知,但论文强调了SOFT-FLOW在样本效率和稳定性方面的优势。
🎯 应用场景
SOFT-FLOW具有广泛的应用前景,可用于各种需要灵巧操作的机器人任务,例如工业自动化、医疗手术、家庭服务等。通过高效的策略微调,可以降低机器人部署成本,提高机器人的适应性和鲁棒性。该研究对于推动机器人技术在实际场景中的应用具有重要意义。
📄 摘要(原文)
Real-world fine-tuning of dexterous manipulation policies remains challenging due to limited real-world interaction budgets and highly multimodal action distributions. Diffusion-based policies, while expressive, do not permit conservative likelihood-based updates during fine-tuning because action probabilities are intractable. In contrast, conventional Gaussian policies collapse under multimodality, particularly when actions are executed in chunks, and standard per-step critics fail to align with chunked execution, leading to poor credit assignment. We present SOFT-FLOW, a sample-efficient off-policy fine-tuning framework with normalizing flow (NF) to address these challenges. The normalizing flow policy yields exact likelihoods for multimodal action chunks, allowing conservative, stable policy updates through likelihood regularization and thereby improving sample efficiency. An action-chunked critic evaluates entire action sequences, aligning value estimation with the policy's temporal structure and improving long-horizon credit assignment. To our knowledge, this is the first demonstration of a likelihood-based, multimodal generative policy combined with chunk-level value learning on real robotic hardware. We evaluate SOFT-FLOW on two challenging dexterous manipulation tasks in the real world: cutting tape with scissors retrieved from a case, and in-hand cube rotation with a palm-down grasp -- both of which require precise, dexterous control over long horizons. On these tasks, SOFT-FLOW achieves stable, sample-efficient adaptation where standard methods struggle.