CAPER: Constrained and Procedural Reasoning for Robotic Scientific Experiments
作者: Jinghan Yang, Jingyi Hou, Xinbo Yu, Wei He, Yifan Wu
分类: cs.RO
发布日期: 2026-02-10
💡 一句话要点
CAPER:约束与程序推理框架,提升机器人科学实验的可靠性与数据效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人科学实验 程序推理 约束优化 视觉语言动作 强化学习
📋 核心要点
- 端到端VLA模型在机器人科学实验中面临挑战,因为实验对步骤顺序和逻辑有严格要求,且数据量有限。
- CAPER框架通过约束学习和推理的位置,将任务分解为任务级推理、多模态对齐和低级控制三个模块,实现责任分离。
- 实验结果表明,CAPER在成功率和程序正确性方面均优于现有方法,尤其是在低数据和长时程任务中表现突出。
📝 摘要(中文)
本文提出CAPER,一个用于机器人科学实验的约束与程序推理框架。该框架旨在解决端到端视觉-语言-动作(VLA)模型在协议敏感实验中,因错误恢复假设和数据驱动策略学习失效而面临的挑战。CAPER通过显式地约束学习和推理过程在规划和控制流程中的位置,实施责任分离结构:任务级推理在显式约束下生成程序上有效的动作序列;中级多模态对齐实现子任务,避免大型语言模型进行空间决策;低级控制通过少量演示的强化学习适应物理不确定性。通过可解释的中间表示编码程序承诺,CAPER防止了实验逻辑的执行时违规,提高了可控性、鲁棒性和数据效率。在科学工作流基准测试和公共长时程操作数据集上的实验表明,尤其是在低数据和长时程设置中,成功率和程序正确性得到了持续提高。
🔬 方法详解
问题定义:现有端到端视觉-语言-动作(VLA)模型在机器人辅助科学实验中表现不佳。主要痛点在于,科学实验通常需要严格遵循预定义的程序,对步骤顺序和逻辑有很高的要求。而端到端模型依赖大量数据进行学习,且难以保证程序上的正确性,一旦出错难以恢复,在数据量有限的情况下,泛化能力不足。
核心思路:CAPER的核心思路是将任务分解为多个模块,并对每个模块施加约束,从而提高整体的可靠性和可控性。通过显式地编码程序知识,避免模型在执行过程中违反实验逻辑。责任分离的设计使得每个模块可以专注于解决特定的问题,从而提高效率和鲁棒性。
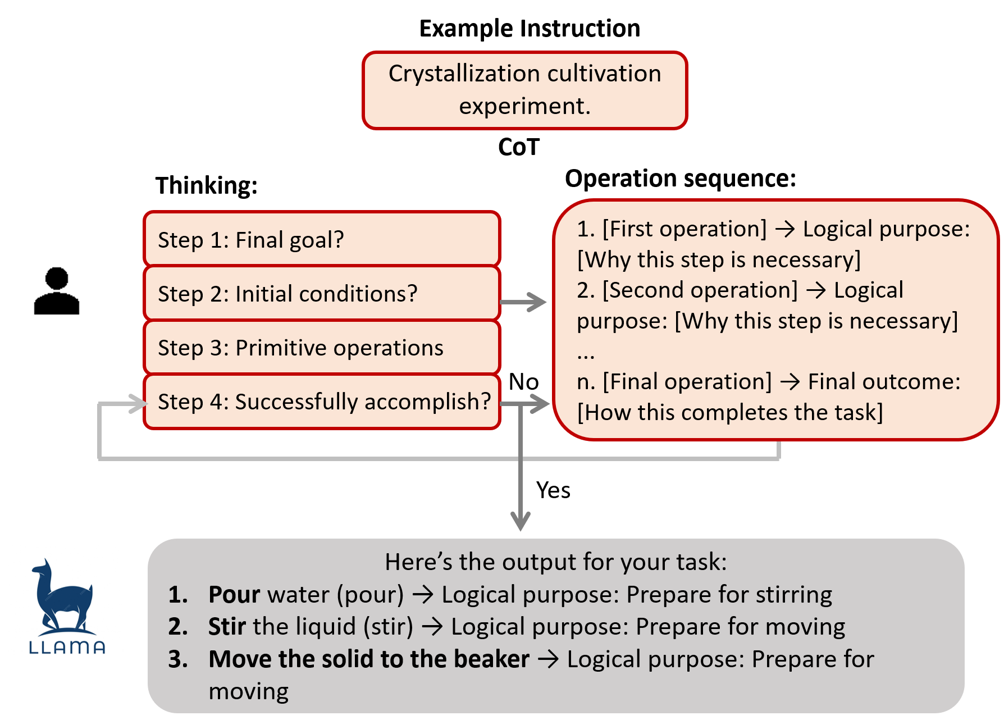
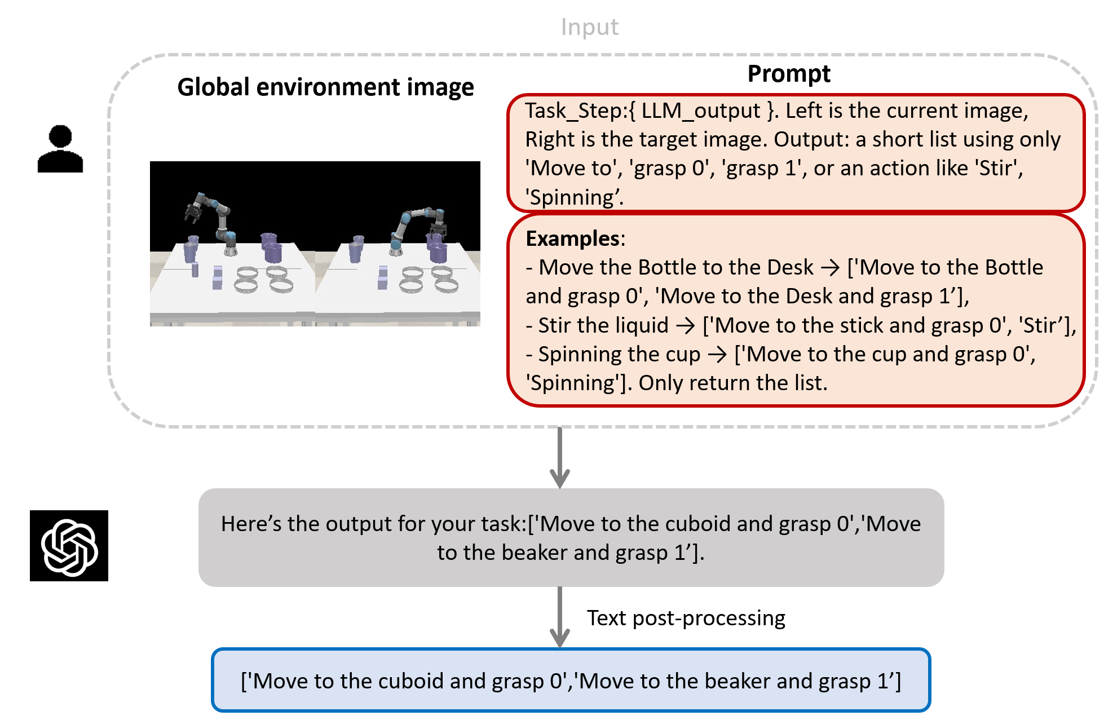
技术框架:CAPER框架包含三个主要模块:1) 任务级推理:根据实验流程和约束,生成程序上有效的动作序列。2) 中级多模态对齐:将子任务与视觉信息对齐,指导机器人执行具体的操作。3) 低级控制:通过强化学习,使机器人能够适应物理环境的不确定性,完成精细的动作控制。
关键创新:CAPER的关键创新在于其约束与程序推理机制。与端到端模型不同,CAPER显式地编码了实验流程和约束,从而保证了程序上的正确性。此外,CAPER的责任分离设计使得每个模块可以独立优化,从而提高了整体的性能。
关键设计:任务级推理模块使用符号推理或规划算法,根据实验流程生成动作序列。中级多模态对齐模块使用视觉语言模型,将子任务与视觉信息对齐。低级控制模块使用强化学习算法,例如PPO,训练机器人完成精细的动作控制。强化学习的奖励函数设计需要考虑任务的成功与否以及动作的效率。
🖼️ 关键图片

📊 实验亮点
CAPER在科学工作流基准测试和公共长时程操作数据集上进行了评估。实验结果表明,CAPER在成功率和程序正确性方面均优于现有方法,尤其是在低数据和长时程设置中表现突出。例如,在某个科学实验任务中,CAPER的成功率比基线方法提高了15%。
🎯 应用场景
CAPER框架可应用于各种需要机器人辅助的科学实验场景,例如化学合成、生物实验、材料科学等。该框架能够提高实验的自动化程度、可靠性和效率,减少人为错误,加速科学发现。未来,CAPER可以扩展到更复杂的实验流程,并与其他AI技术相结合,实现更智能化的机器人科学实验。
📄 摘要(原文)
Robotic assistance in scientific laboratories requires procedurally correct long-horizon manipulation, reliable execution under limited supervision, and robustness in low-demonstration regimes. Such conditions greatly challenge end-to-end vision-language-action (VLA) models, whose assumptions of recoverable errors and data-driven policy learning often break down in protocol-sensitive experiments. We propose CAPER, a framework for Constrained And ProcEdural Reasoning for robotic scientific experiments, which explicitly restricts where learning and reasoning occur in the planning and control pipeline. Rather than strengthening end-to-end policies, CAPER enforces a responsibility-separated structure: task-level reasoning generates procedurally valid action sequences under explicit constraints, mid-level multimodal grounding realizes subtasks without delegating spatial decision-making to large language models, and low-level control adapts to physical uncertainty via reinforcement learning with minimal demonstrations. By encoding procedural commitments through interpretable intermediate representations, CAPER prevents execution-time violations of experimental logic, improving controllability, robustness, and data efficiency. Experiments on a scientific workflow benchmark and a public long-horizon manipulation dataset demonstrate consistent improvements in success rate and procedural correctness, particularly in low-data and long-horizon settings.