TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
作者: Qinwen Xu, Jiaming Liu, Rui Zhou, Shaojun Shi, Nuowei Han, Zhuoyang Liu, Chenyang Gu, Shuo Gu, Yang Yue, Gao Huang, Wenzhao Zheng, Sirui Han, Peng Jia, Shanghang Zhang
分类: cs.RO
发布日期: 2026-02-09
💡 一句话要点
TwinRL-VLA:基于数字孪生的强化学习,用于真实世界机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 强化学习 数字孪生 视觉-语言-动作模型 模拟到真实 探索空间扩展
📋 核心要点
- 现有VLA模型依赖专家演示,成本高昂且与真实世界交互不足,限制了其在机器人操作中的应用。
- TwinRL利用数字孪生技术,扩展探索空间,并设计模拟到真实的引导探索策略,加速在线强化学习。
- 实验表明,TwinRL在真实和模拟环境中均表现出色,显著提升了VLA模型在机器人操作任务中的成功率和效率。
📝 摘要(中文)
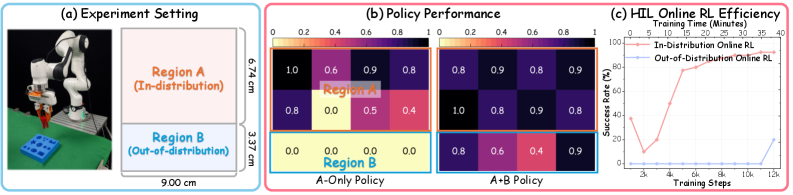
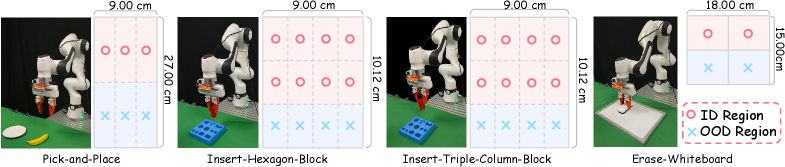
尽管视觉-语言-动作(VLA)模型具有强大的泛化能力,但仍受到专家演示的高成本和现实世界交互不足的限制。在线强化学习(RL)在改进通用基础模型方面显示出潜力,但将其应用于现实世界中的VLA操作仍然受到探索效率低和探索空间受限的阻碍。通过系统的真实世界实验,我们观察到在线RL的有效探索空间与监督微调(SFT)的数据分布密切相关。受此启发,我们提出了TwinRL,一种数字孪生-真实世界协同RL框架,旨在扩展和指导VLA模型的探索。首先,通过智能手机捕获的场景高效地重建高保真数字孪生,从而实现真实环境和模拟环境之间逼真的双向转移。在SFT预热阶段,我们引入了使用数字孪生的探索空间扩展策略,以扩大数据轨迹分布的支持。在此增强的初始化基础上,我们提出了一种模拟到真实引导的探索策略,以进一步加速在线RL。具体来说,TwinRL在部署之前在数字孪生中执行高效且并行的在线RL,从而有效地弥合了离线和在线训练阶段之间的差距。随后,我们利用高效的数字孪生采样来识别容易出错但信息丰富的配置,这些配置用于指导真实机器人上以人为中心的有针对性的rollout。在我们的实验中,TwinRL在真实世界演示覆盖的同分布区域和异分布区域都接近100%的成功率,与先前的真实世界RL方法相比,至少提高了30%的速度,并且在四个任务中平均仅需约20分钟。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在真实世界机器人操作中,由于专家演示成本高昂和真实世界交互不足而导致的探索效率低下的问题。现有方法难以在有限的探索空间内有效地学习策略,限制了VLA模型在实际场景中的应用。
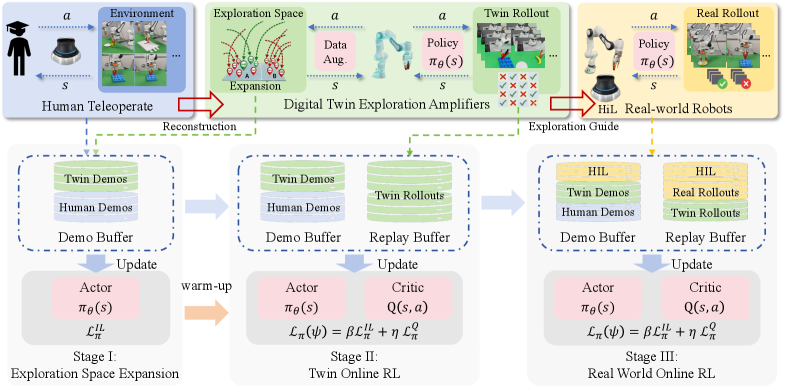
核心思路:论文的核心思路是利用数字孪生技术构建高保真模拟环境,从而扩展VLA模型的探索空间,并加速在线强化学习过程。通过在数字孪生中进行预训练和引导探索,可以有效地弥合离线训练和在线部署之间的差距,提高VLA模型在真实世界中的性能。
技术框架:TwinRL框架包含以下几个主要阶段:1) 数字孪生重建:利用智能手机捕获的场景数据,高效地重建高保真数字孪生环境。2) 探索空间扩展:在监督微调(SFT)预热阶段,利用数字孪生扩展数据轨迹分布,为后续强化学习提供更好的初始化。3) 模拟到真实引导探索:在数字孪生中进行高效的在线强化学习,并利用数字孪生采样识别易错配置,指导真实机器人上的人工rollout。
关键创新:TwinRL的关键创新在于其数字孪生-真实世界协同强化学习框架,该框架能够有效地利用数字孪生环境扩展探索空间,并指导真实世界中的强化学习过程。与传统的强化学习方法相比,TwinRL能够显著提高探索效率,并降低对专家演示的依赖。
关键设计:在数字孪生重建方面,论文采用了基于智能手机图像的高效重建方法,保证了数字孪生的逼真度和可用性。在探索空间扩展方面,论文设计了一种基于数字孪生的数据增强策略,扩大了SFT的数据分布。在模拟到真实引导探索方面,论文利用数字孪生采样识别易错配置,并结合人工干预,提高了强化学习的效率和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TwinRL在同分布和异分布区域均接近100%的成功率,与现有真实世界强化学习方法相比,速度提高了至少30%,并且在四个任务中平均仅需约20分钟。这些结果验证了TwinRL在提高VLA模型在真实世界机器人操作中的性能和效率方面的有效性。
🎯 应用场景
TwinRL-VLA框架可应用于各种机器人操作任务,例如工业自动化、家庭服务机器人和医疗机器人等。通过降低对专家演示的依赖和提高探索效率,该方法有望加速VLA模型在真实世界中的部署和应用,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.