$χ_{0}$: Resource-Aware Robust Manipulation via Taming Distributional Inconsistencies
作者: Checheng Yu, Chonghao Sima, Gangcheng Jiang, Hai Zhang, Haoguang Mai, Hongyang Li, Huijie Wang, Jin Chen, Kaiyang Wu, Li Chen, Lirui Zhao, Modi Shi, Ping Luo, Qingwen Bu, Shijia Peng, Tianyu Li, Yibo Yuan
分类: cs.RO, cs.CV
发布日期: 2026-02-09
💡 一句话要点
提出$χ_{0}$框架,通过驯服分布不一致性实现资源高效的鲁棒操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 分布偏移 鲁棒性 模型算术 阶段优势 训练-部署对齐 服装操作
📋 核心要点
- 现有机器人操作方法依赖大规模数据和计算,但忽略了训练、演示和部署之间的分布不一致性,导致鲁棒性不足。
- $χ_{0}$框架通过模型算术、阶段优势估计和训练-部署对齐三个模块,缓解分布偏移,提升操作的鲁棒性和资源效率。
- 实验表明,$χ_{0}$在服装操作任务中,仅用少量数据和计算资源,成功率显著超越现有方法,并能连续运行24小时。
📝 摘要(中文)
高可靠性的长时程机器人操作传统上依赖于大规模数据和计算来理解复杂的真实世界动态。然而,我们发现,现实世界鲁棒性的主要瓶颈不仅仅是资源规模,而是人类演示分布、策略学习的归纳偏置和测试时执行分布之间的分布偏移——这种系统性的不一致性导致多阶段任务中出现复合误差。为了缓解这些不一致性,我们提出了$χ_{0}$,这是一个资源高效的框架,具有有效模块,旨在实现机器人操作中的生产级鲁棒性。我们的方法建立在三个技术支柱之上:(i)模型算术,一种权重空间合并策略,可以有效地吸收来自不同演示的不同分布,从对象外观到状态变化;(ii)阶段优势,一种阶段感知优势估计器,提供稳定、密集的进度信号,克服了先前非阶段方法的数值不稳定性;(iii)训练-部署对齐,通过时空增强、启发式DAgger校正和时间块状平滑来弥合分布差距。$χ_{0}$使两组双臂机器人能够协同编排长时程服装操作,涵盖从展平、折叠到悬挂不同衣服的任务。我们的方法表现出高可靠性的自主性;我们能够从任意初始状态连续运行系统24小时不停机。实验验证了$χ_{0}$在成功率方面超过了最先进的$π_{0.5}$近250%,仅使用20小时的数据和8个A100 GPU。代码、数据和模型将发布以方便社区。
🔬 方法详解
问题定义:现有机器人操作方法,特别是长时程操作,往往需要大量数据和计算资源。然而,即使拥有充足的资源,由于人类演示数据、策略学习的归纳偏置以及实际部署环境之间存在分布差异,导致模型在真实世界中的鲁棒性仍然不足。这种分布不一致性会在多阶段任务中累积误差,最终导致任务失败。现有方法难以有效解决这种系统性的分布偏移问题。
核心思路:$χ_{0}$的核心思路是通过一系列精心设计的模块,显式地解决训练、演示和部署环境之间的分布不一致性。具体来说,它通过模型算术来吸收不同演示的分布,通过阶段优势估计来提供稳定的训练信号,并通过训练-部署对齐来弥合训练和部署之间的差距。这种多管齐下的方法旨在使策略更加鲁棒,并能够在资源有限的情况下实现高性能。
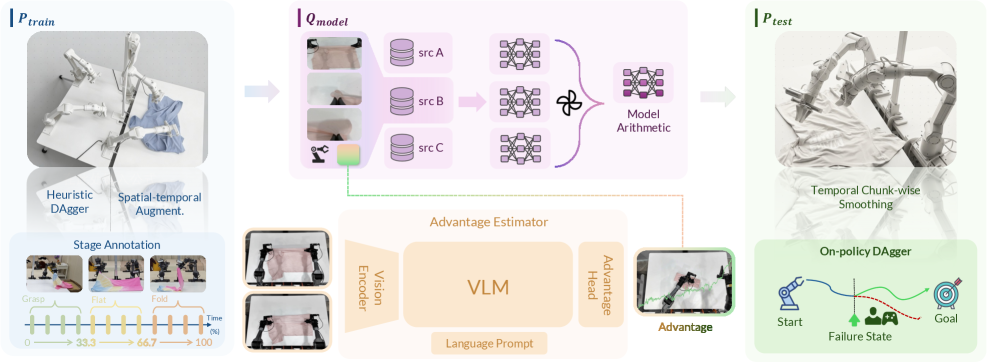
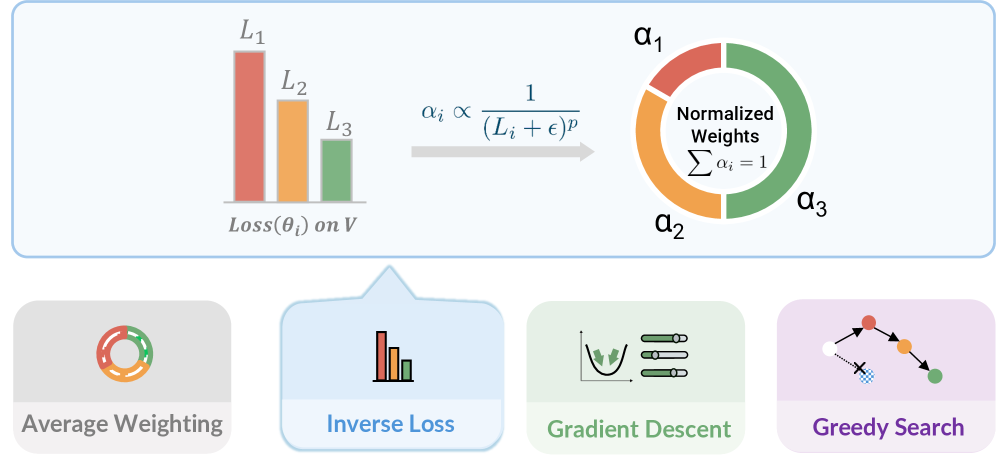
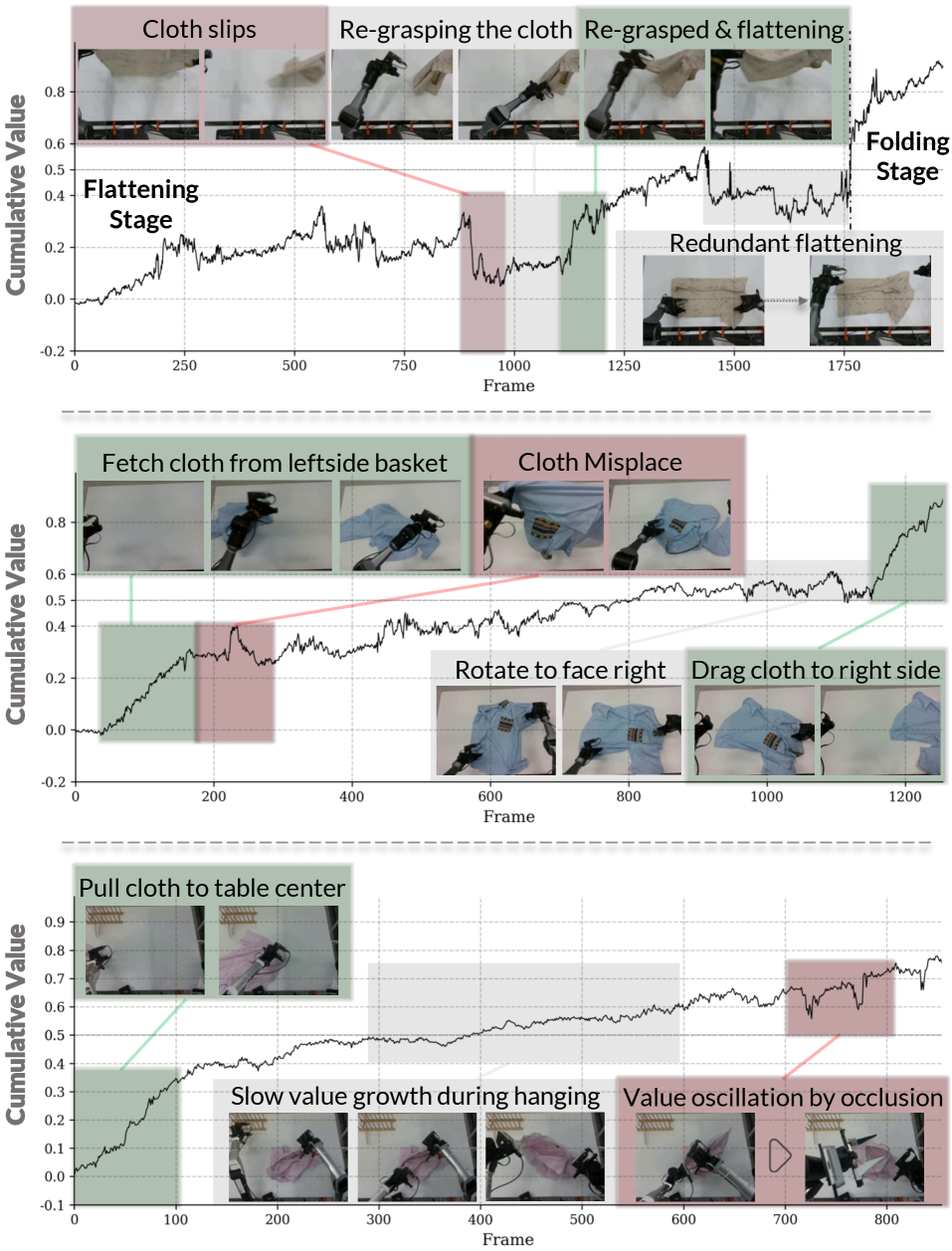
技术框架:$χ_{0}$框架包含三个主要模块: 1. 模型算术 (Model Arithmetic):通过权重空间合并策略,将来自不同演示的分布信息融合到单个模型中,从而提高模型的泛化能力。 2. 阶段优势 (Stage Advantage):使用阶段感知的优势估计器,为策略提供稳定且密集的进度信号,克服了传统优势估计方法在数值上的不稳定性。 3. 训练-部署对齐 (Train-Deploy Alignment):通过时空增强、启发式DAgger校正和时间块状平滑等技术,缩小训练和部署环境之间的分布差距。
关键创新:$χ_{0}$的关键创新在于其系统性地解决了机器人操作中的分布不一致性问题。与以往专注于扩大数据规模或改进模型架构的方法不同,$χ_{0}$直接针对分布偏移进行优化,从而在资源有限的情况下实现了更高的鲁棒性和性能。模型算术、阶段优势和训练-部署对齐三个模块的协同作用是其成功的关键。
关键设计: * 模型算术:具体实现方式未知,但推测可能涉及对不同模型权重进行加权平均或其他形式的组合。 * 阶段优势:优势函数的具体形式未知,但强调了阶段感知的重要性,可能根据当前所处的阶段动态调整奖励函数。 * 训练-部署对齐:时空增强的具体方法未知,启发式DAgger校正可能涉及人工干预纠正策略的错误行为,时间块状平滑可能用于减少策略输出的抖动。
🖼️ 关键图片
📊 实验亮点
实验结果表明,$χ_{0}$在服装操作任务中,仅使用20小时的数据和8个A100 GPU,成功率就比最先进的$π_{0.5}$提高了近250%。此外,$χ_{0}$能够从任意初始状态连续运行24小时不停机,展示了其卓越的鲁棒性和可靠性。
🎯 应用场景
$χ_{0}$框架在服装操作、工业装配、家庭服务等领域具有广泛的应用前景。通过提高机器人操作的鲁棒性和资源效率,可以降低自动化成本,并使机器人能够更好地适应复杂多变的真实世界环境。该研究有望推动机器人技术在更多实际场景中的应用。
📄 摘要(原文)
High-reliability long-horizon robotic manipulation has traditionally relied on large-scale data and compute to understand complex real-world dynamics. However, we identify that the primary bottleneck to real-world robustness is not resource scale alone, but the distributional shift among the human demonstration distribution, the inductive bias learned by the policy, and the test-time execution distribution -- a systematic inconsistency that causes compounding errors in multi-stage tasks. To mitigate these inconsistencies, we propose $χ_{0}$, a resource-efficient framework with effective modules designated to achieve production-level robustness in robotic manipulation. Our approach builds off three technical pillars: (i) Model Arithmetic, a weight-space merging strategy that efficiently soaks up diverse distributions of different demonstrations, varying from object appearance to state variations; (ii) Stage Advantage, a stage-aware advantage estimator that provides stable, dense progress signals, overcoming the numerical instability of prior non-stage approaches; and (iii) Train-Deploy Alignment, which bridges the distribution gap via spatio-temporal augmentation, heuristic DAgger corrections, and temporal chunk-wise smoothing. $χ_{0}$ enables two sets of dual-arm robots to collaboratively orchestrate long-horizon garment manipulation, spanning tasks from flattening, folding, to hanging different clothes. Our method exhibits high-reliability autonomy; we are able to run the system from arbitrary initial state for consecutive 24 hours non-stop. Experiments validate that $χ_{0}$ surpasses the state-of-the-art $π_{0.5}$ in success rate by nearly 250%, with only 20-hour data and 8 A100 GPUs. Code, data and models will be released to facilitate the community.