Dexterous Manipulation Policies from RGB Human Videos via 4D Hand-Object Trajectory Reconstruction
作者: Hongyi Chen, Tony Dong, Tiancheng Wu, Liquan Wang, Yash Jangir, Yaru Niu, Yufei Ye, Homanga Bharadhwaj, Zackory Erickson, Jeffrey Ichnowski
分类: cs.RO, cs.CV
发布日期: 2026-02-09
💡 一句话要点
VIDEOMANIP:通过RGB视频进行4D手-物轨迹重建,学习灵巧操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 灵巧操作 机器人学习 RGB视频 4D轨迹重建 手-物交互 接触优化 演示合成
📋 核心要点
- 现有方法依赖于可穿戴设备或专用传感设备进行人机遥操作,限制了灵巧操作学习的可扩展性。
- VIDEOMANIP通过RGB视频重建4D手-物轨迹,并结合接触优化和演示合成,实现从人类视频到机器人操作策略的迁移。
- 实验结果表明,该方法在模拟和真实环境中均取得了显著的成功率,优于现有的重定向方法。
📝 摘要(中文)
本文提出VIDEOMANIP,一个无需穿戴设备的框架,直接从RGB人类视频中学习灵巧操作。该框架利用计算机视觉的最新进展,通过估计人类手部姿势和物体网格,从单目视频中重建显式的4D机器人-物体轨迹,并将重建的人类动作重新映射到机器人手上,用于操作学习。为了使重建的机器人数据适用于灵巧操作训练,本文引入了以交互为中心的手-物接触优化抓取建模,以及一种演示合成策略,该策略从单个视频生成多样化的训练轨迹,从而实现无需额外机器人演示的通用策略学习。在模拟中,使用Inspire Hand的学习抓取模型在20个不同的物体上实现了70.25%的成功率。在现实世界中,使用LEAP Hand,从RGB视频训练的操作策略在七个任务上的平均成功率为62.86%,优于基于重定向的方法15.87%。
🔬 方法详解
问题定义:现有灵巧操作学习方法依赖于昂贵且难以扩展的人工遥操作数据采集,例如使用可穿戴设备或专用传感器。这限制了训练数据的规模和多样性,阻碍了通用操作策略的学习。因此,如何利用更易获取的人类视频数据来学习灵巧操作策略是一个关键问题。
核心思路:VIDEOMANIP的核心思路是从RGB人类视频中提取手部和物体的运动轨迹,并将这些轨迹重新映射到机器人手上。通过计算机视觉技术重建人类的手部姿势和物体网格,然后将这些信息转化为机器人可以执行的动作。为了提高训练数据的质量和多样性,该方法还引入了手-物接触优化和演示合成策略。
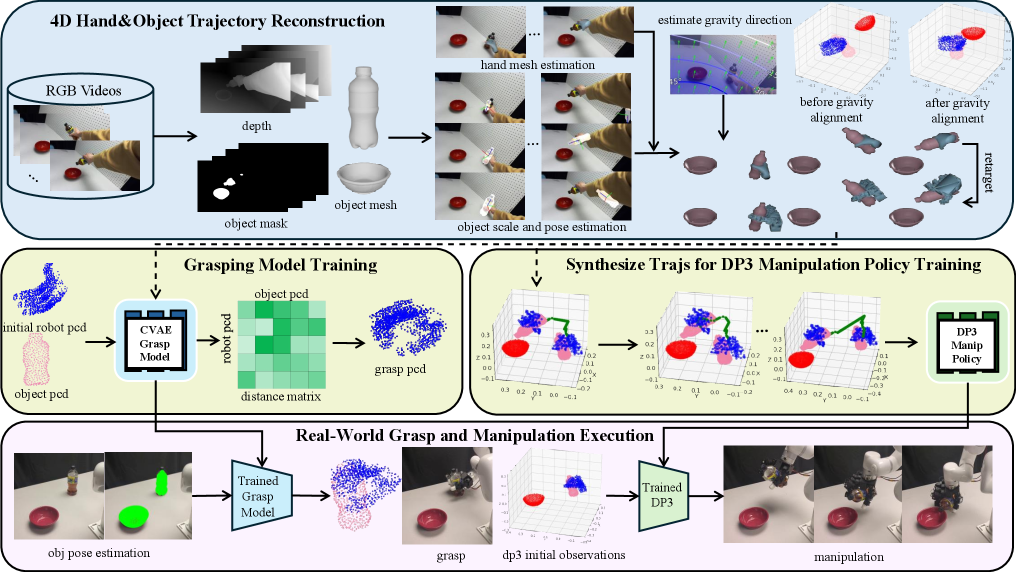
技术框架:VIDEOMANIP框架主要包含以下几个阶段:1) 4D轨迹重建:从单目RGB视频中估计人类手部姿势和物体网格,重建手-物交互的4D轨迹。2) 运动重定向:将重建的人类运动轨迹映射到机器人手上,生成机器人操作的初步轨迹。3) 接触优化:优化机器人手与物体之间的接触点,确保抓取的稳定性和可靠性。4) 演示合成:从单个视频生成多样化的训练轨迹,增加训练数据的多样性。5) 策略学习:使用合成的机器人操作数据训练灵巧操作策略。
关键创新:VIDEOMANIP的关键创新在于:1) 无需穿戴设备:直接从RGB视频中学习操作策略,避免了对昂贵且不方便的穿戴设备的依赖。2) 手-物接触优化:通过优化手与物体之间的接触点,提高了抓取的稳定性和可靠性。3) 演示合成:从单个视频生成多样化的训练轨迹,增加了训练数据的多样性,提高了策略的泛化能力。
关键设计:在4D轨迹重建阶段,使用了先进的手部姿势估计和物体网格重建算法。在接触优化阶段,设计了一个基于交互的抓取模型,并使用优化算法来寻找最佳的接触点。在演示合成阶段,使用了数据增强技术来生成多样化的训练轨迹。损失函数包括手部姿势重建损失、物体网格重建损失、接触优化损失和策略学习损失。
🖼️ 关键图片
📊 实验亮点
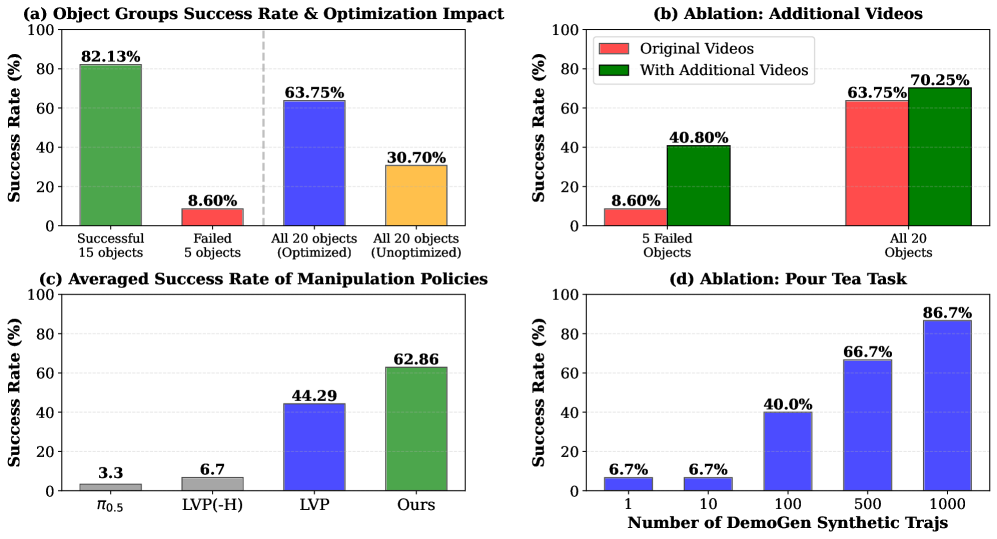
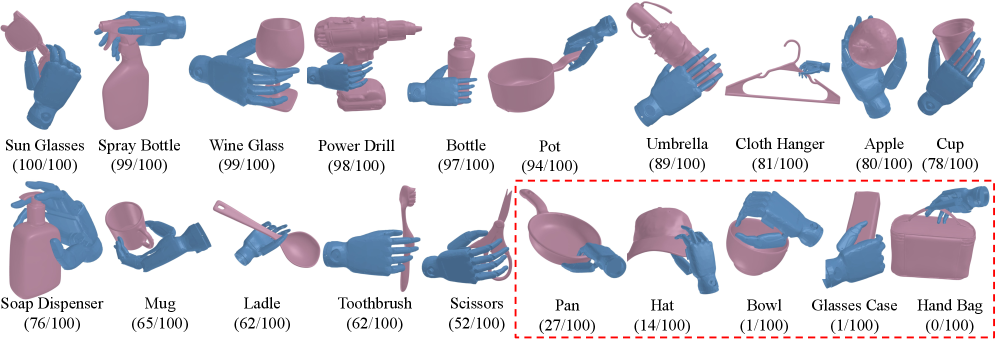
该方法在模拟环境中使用Inspire Hand实现了70.25%的抓取成功率,在真实环境中使用LEAP Hand在七个任务上实现了62.86%的平均成功率,相比于基于重定向的方法提升了15.87%。这些结果表明,VIDEOMANIP能够有效地从RGB视频中学习灵巧操作策略,并在真实环境中取得良好的性能。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的机器人应用场景,例如:工业自动化、家庭服务机器人、医疗机器人等。通过利用现有的海量人类操作视频数据,可以快速训练出适用于不同任务的灵巧操作策略,降低了机器人部署的成本和难度。未来,该方法有望进一步扩展到更复杂的任务和环境,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Multi-finger robotic hand manipulation and grasping are challenging due to the high-dimensional action space and the difficulty of acquiring large-scale training data. Existing approaches largely rely on human teleoperation with wearable devices or specialized sensing equipment to capture hand-object interactions, which limits scalability. In this work, we propose VIDEOMANIP, a device-free framework that learns dexterous manipulation directly from RGB human videos. Leveraging recent advances in computer vision, VIDEOMANIP reconstructs explicit 4D robot-object trajectories from monocular videos by estimating human hand poses, object meshes, and retargets the reconstructed human motions to robotic hands for manipulation learning. To make the reconstructed robot data suitable for dexterous manipulation training, we introduce hand-object contact optimization with interaction-centric grasp modeling, as well as a demonstration synthesis strategy that generates diverse training trajectories from a single video, enabling generalizable policy learning without additional robot demonstrations. In simulation, the learned grasping model achieves a 70.25% success rate across 20 diverse objects using the Inspire Hand. In the real world, manipulation policies trained from RGB videos achieve an average 62.86% success rate across seven tasks using the LEAP Hand, outperforming retargeting-based methods by 15.87%. Project videos are available at videomanip.github.io.