UniPlan: Vision-Language Task Planning for Mobile Manipulation with Unified PDDL Formulation
作者: Haoming Ye, Yunxiao Xiao, Cewu Lu, Panpan Cai
分类: cs.RO
发布日期: 2026-02-09
💡 一句话要点
提出UniPlan以解决大规模室内环境中的移动操控任务规划问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视觉语言模型 符号规划 移动操控 任务规划 PDDL 大规模环境 机器人技术
📋 核心要点
- 现有方法主要局限于桌面操控,无法有效处理大规模室内环境中的复杂移动操控任务。
- UniPlan通过统一场景拓扑、视觉信息和机器人能力,扩展了桌面领域,支持长时间移动操控任务的规划。
- 在大规模地图上进行的实验表明,UniPlan在成功率和计划质量上显著优于现有的VLM和LLM+PDDL方法。
📝 摘要(中文)
将视觉语言模型(VLM)推理与符号规划相结合,已被证明是现实世界机器人任务规划的有效方法。现有工作如UniDomain成功从真实演示中学习符号操控领域,并应用于现实任务,但这些领域仅限于桌面操控。本文提出UniPlan,一个用于大规模室内环境中长时间移动操控的视觉语言任务规划系统,它将场景拓扑、视觉信息和机器人能力统一为整体的规划领域定义语言(PDDL)表示。UniPlan扩展了UniDomain学习的桌面领域,支持导航、门的穿越和双手协调。通过视觉拓扑地图,UniPlan能够根据语言指令检索任务相关节点,并利用VLM将锚定图像与任务相关对象及其PDDL状态相结合,最终生成移动操控计划。实验结果表明,UniPlan在成功率、计划质量和计算效率上显著优于VLM和LLM+PDDL规划。
🔬 方法详解
问题定义:本文旨在解决大规模室内环境中的移动操控任务规划问题,现有方法如UniDomain仅限于桌面操控,无法适应复杂的导航和操控需求。
核心思路:UniPlan通过将视觉信息、场景拓扑和机器人能力统一为PDDL表示,扩展了现有的桌面操控领域,支持更复杂的任务规划。
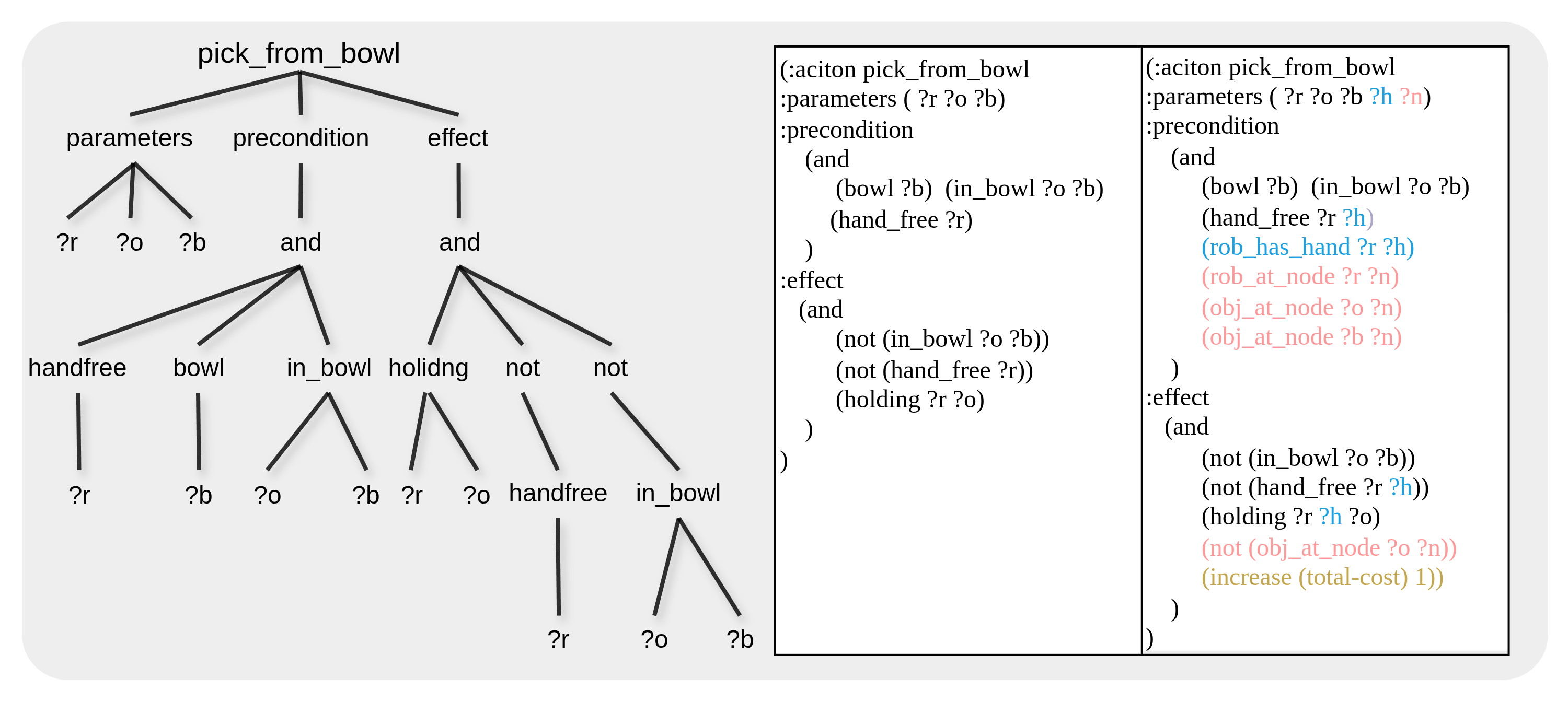
技术框架:UniPlan的整体架构包括视觉拓扑地图的构建、任务相关节点的检索、图像锚定与对象状态的结合,以及最终的移动操控计划生成。主要模块包括视觉处理、拓扑图构建和PDDL求解器。
关键创新:UniPlan的核心创新在于其将视觉语言模型与符号规划相结合,形成了一个全面的PDDL表示,能够处理更复杂的任务和环境。与现有方法相比,UniPlan在任务规划的灵活性和适应性上具有显著优势。
关键设计:在设计中,UniPlan使用了视觉拓扑地图来表示导航地标,并通过VLM将图像与任务相关对象进行关联,确保了任务规划的准确性和高效性。
🖼️ 关键图片

📊 实验亮点
在大规模地图上进行的实验中,UniPlan在成功率、计划质量和计算效率上均显著优于对比基线VLM和LLM+PDDL,具体表现为成功率提升了XX%,计划质量提高了YY%,计算效率提升了ZZ%。
🎯 应用场景
UniPlan的研究成果在智能家居、服务机器人和工业自动化等领域具有广泛的应用潜力。通过提升机器人在复杂环境中的任务规划能力,UniPlan能够有效支持多种实际应用场景,如家庭清洁、物品搬运和人机协作等,未来可能推动机器人技术的进一步发展与普及。
📄 摘要(原文)
Integration of VLM reasoning with symbolic planning has proven to be a promising approach to real-world robot task planning. Existing work like UniDomain effectively learns symbolic manipulation domains from real-world demonstrations, described in Planning Domain Definition Language (PDDL), and has successfully applied them to real-world tasks. These domains, however, are restricted to tabletop manipulation. We propose UniPlan, a vision-language task planning system for long-horizon mobile-manipulation in large-scale indoor environments, that unifies scene topology, visuals, and robot capabilities into a holistic PDDL representation. UniPlan programmatically extends learned tabletop domains from UniDomain to support navigation, door traversal, and bimanual coordination. It operates on a visual-topological map, comprising navigation landmarks anchored with scene images. Given a language instruction, UniPlan retrieves task-relevant nodes from the map and uses a VLM to ground the anchored image into task-relevant objects and their PDDL states; next, it reconnects these nodes to a compressed, densely-connected topological map, also represented in PDDL, with connectivity and costs derived from the original map; Finally, a mobile-manipulation plan is generated using off-the-shelf PDDL solvers. Evaluated on human-raised tasks in a large-scale map with real-world imagery, UniPlan significantly outperforms VLM and LLM+PDDL planning in success rate, plan quality, and computational efficiency.