STEP: Warm-Started Visuomotor Policies with Spatiotemporal Consistency Prediction
作者: Jinhao Li, Yuxuan Cong, Yingqiao Wang, Hao Xia, Shan Huang, Yijia Zhang, Ningyi Xu, Guohao Dai
分类: cs.RO, cs.AI
发布日期: 2026-02-09
备注: 13 pages, 9 figures
💡 一句话要点
STEP:基于时空一致性预测的扩散模型视觉运动策略加速方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉运动控制 扩散模型 机器人操作 实时控制 时空一致性
📋 核心要点
- 扩散策略在视觉运动控制中表现出色,但推理延迟高,限制了其在实时系统中的应用。
- STEP通过时空一致性预测生成高质量的warm-start动作,加速扩散过程,同时保持生成能力。
- 实验表明,STEP在模拟和真实世界任务中均优于现有方法,显著提高了成功率并降低了延迟。
📝 摘要(中文)
扩散策略因其能够对动作序列的分布进行建模并捕获多模态特性,已成为机器人操作中视觉运动控制的强大范例。然而,迭代去噪导致显著的推理延迟,限制了实时闭环系统中的控制频率。现有的加速方法要么减少采样步骤,要么通过直接预测绕过扩散,要么重用过去的动作,但通常难以兼顾动作质量和持续的低延迟。本文提出了STEP,一种轻量级的时空一致性预测机制,用于构建高质量的warm-start动作,这些动作在分布上接近目标动作且在时间上一致,同时不影响原始扩散策略的生成能力。然后,我们提出了一种速度感知的扰动注入机制,该机制基于时间动作变化自适应地调节驱动激励,以防止执行停滞,尤其是在真实世界的任务中。我们进一步提供了理论分析,表明所提出的预测诱导了局部收缩映射,确保了扩散细化期间动作误差的收敛。我们在九个模拟基准测试和两个真实世界任务上进行了广泛的评估。值得注意的是,在RoboMimic基准测试和真实世界任务中,具有2个步骤的STEP分别比BRIDGER和DDIM实现了平均21.6%和27.5%的更高成功率。这些结果表明,与现有方法相比,STEP始终在推理延迟和成功率的帕累托前沿上取得了进展。
🔬 方法详解
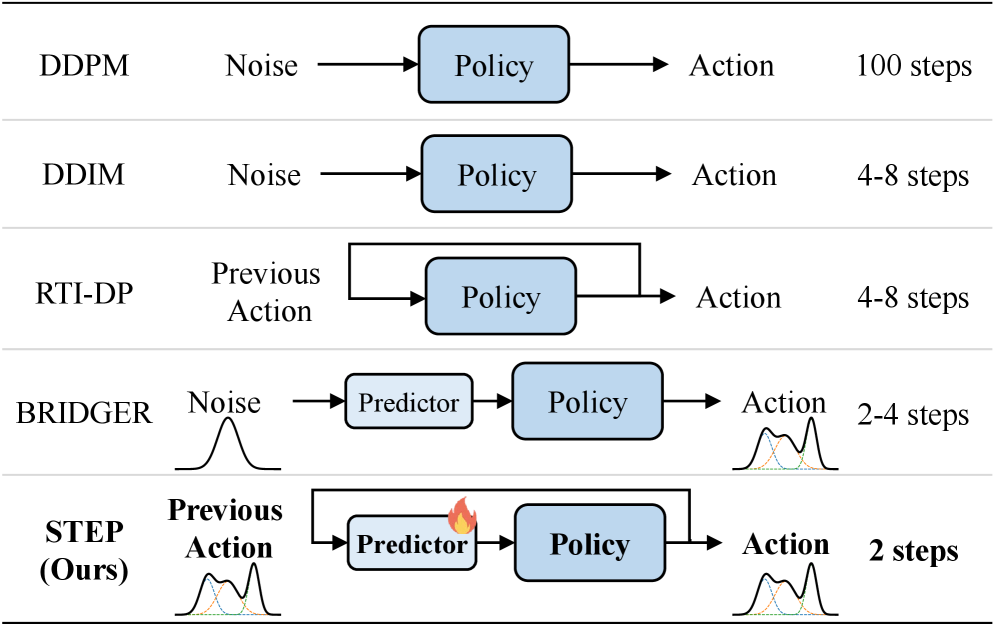
问题定义:现有基于扩散模型的视觉运动控制方法,虽然能够处理动作序列的多模态特性,但由于迭代去噪过程,推理速度慢,难以满足实时控制的需求。现有的加速方法,如减少采样步骤或直接预测,往往会牺牲动作质量或时间一致性。
核心思路:STEP的核心思路是利用一个轻量级的时空一致性预测机制,为扩散过程提供一个高质量的初始动作(warm-start)。这个初始动作不仅在分布上接近目标动作,而且在时间上保持一致,从而减少了后续扩散过程所需的迭代次数,加速了推理过程。
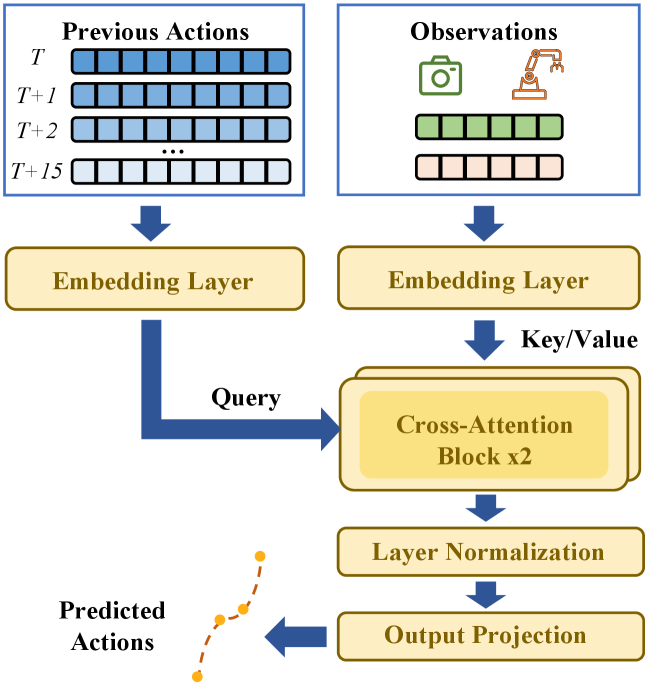
技术框架:STEP的整体框架包括以下几个主要模块:1) 时空一致性预测模块:该模块基于历史观测和动作,预测一个高质量的初始动作。2) 扩散模型:使用预训练的扩散模型对初始动作进行细化。3) 速度感知的扰动注入模块:该模块根据动作的时间变化,自适应地调节驱动激励,防止执行停滞。整个流程是先通过时空一致性预测得到初始动作,然后通过扩散模型进行迭代优化,最后通过扰动注入机制保证执行的稳定性。
关键创新:STEP的关键创新在于其时空一致性预测机制。该机制能够生成高质量的warm-start动作,显著减少了扩散过程所需的迭代次数,从而加速了推理过程。与现有方法相比,STEP在保证动作质量和时间一致性的同时,实现了更低的延迟。此外,速度感知的扰动注入机制也提高了在真实世界任务中的鲁棒性。
关键设计:时空一致性预测模块的具体实现细节未知,但可以推测其可能使用了循环神经网络(RNN)或Transformer等序列模型来建模动作的时间依赖性。速度感知的扰动注入机制可能使用了PID控制或类似的反馈控制策略,根据动作的变化率来调节驱动激励。论文中提到了一种理论分析,表明所提出的预测诱导了局部收缩映射,确保了扩散细化期间动作误差的收敛,但具体的数学公式和证明过程未知。
🖼️ 关键图片

📊 实验亮点
STEP在RoboMimic基准测试和真实世界任务中表现出色。在RoboMimic上,使用2步STEP比BRIDGER提高了平均21.6%的成功率。在真实世界任务中,使用2步STEP比DDIM提高了平均27.5%的成功率。这些结果表明,STEP能够在显著降低推理延迟的同时,保持甚至提高动作的质量和成功率。
🎯 应用场景
STEP具有广泛的应用前景,可用于各种需要实时视觉运动控制的机器人任务,例如:工业自动化中的快速装配、医疗机器人中的精准手术、以及服务机器人中的复杂操作。通过降低推理延迟,STEP使得扩散策略能够应用于对实时性要求更高的场景,提升了机器人的智能化水平和应用范围。
📄 摘要(原文)
Diffusion policies have recently emerged as a powerful paradigm for visuomotor control in robotic manipulation due to their ability to model the distribution of action sequences and capture multimodality. However, iterative denoising leads to substantial inference latency, limiting control frequency in real-time closed-loop systems. Existing acceleration methods either reduce sampling steps, bypass diffusion through direct prediction, or reuse past actions, but often struggle to jointly preserve action quality and achieve consistently low latency. In this work, we propose STEP, a lightweight spatiotemporal consistency prediction mechanism to construct high-quality warm-start actions that are both distributionally close to the target action and temporally consistent, without compromising the generative capability of the original diffusion policy. Then, we propose a velocity-aware perturbation injection mechanism that adaptively modulates actuation excitation based on temporal action variation to prevent execution stall especially for real-world tasks. We further provide a theoretical analysis showing that the proposed prediction induces a locally contractive mapping, ensuring convergence of action errors during diffusion refinement. We conduct extensive evaluations on nine simulated benchmarks and two real-world tasks. Notably, STEP with 2 steps can achieve an average 21.6% and 27.5% higher success rate than BRIDGER and DDIM on the RoboMimic benchmark and real-world tasks, respectively. These results demonstrate that STEP consistently advances the Pareto frontier of inference latency and success rate over existing methods.