Self-Supervised Bootstrapping of Action-Predictive Embodied Reasoning
作者: Milan Ganai, Katie Luo, Jonas Frey, Clark Barrett, Marco Pavone
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2026-02-09
💡 一句话要点
提出R&B-EnCoRe,通过自监督方式引导具身推理,提升VLA模型性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 自监督学习 视觉-语言-动作模型 推理 变分推理 机器人 强化学习
📋 核心要点
- 现有具身推理方法依赖固定模板,易受无关信息干扰,阻碍策略学习和推理质量提升。
- R&B-EnCoRe通过自监督学习,从互联网知识中提炼具身策略,无需人工标注或外部奖励。
- 实验表明,R&B-EnCoRe在操作、导航和自动驾驶任务中显著提升了VLA模型的性能。
📝 摘要(中文)
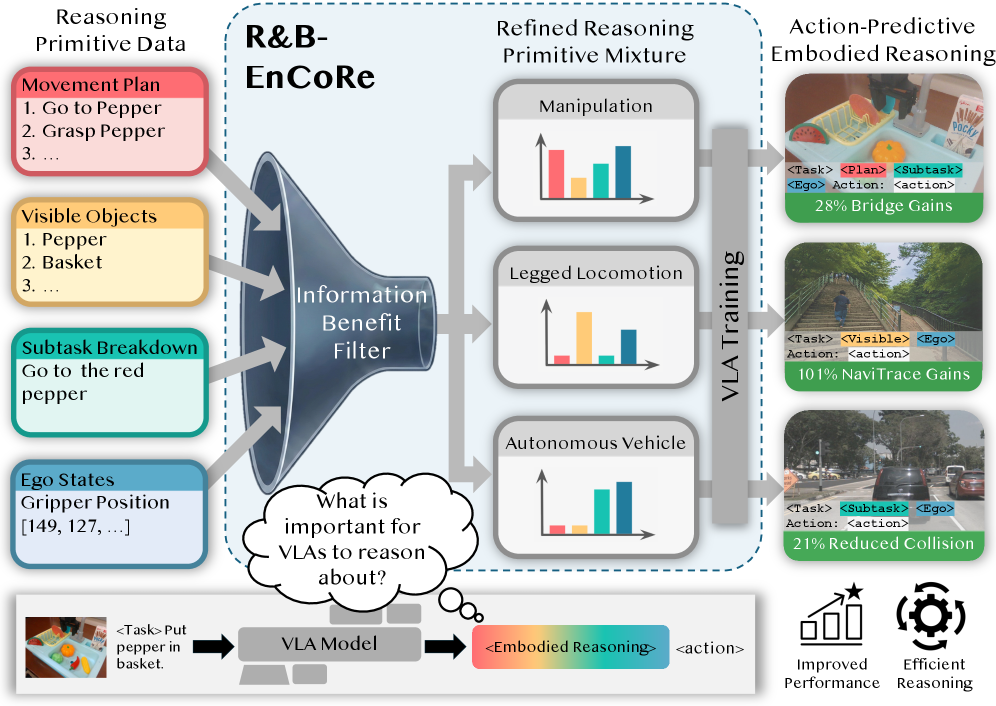
具身Chain-of-Thought (CoT)推理显著提升了视觉-语言-动作(VLA)模型的能力,但现有方法依赖于固定的模板来指定推理原语(例如,场景中的对象、高层计划、结构化可供性)。这些模板可能迫使策略处理不相关的信息,从而分散了对关键动作预测信号的注意力。这造成了一个瓶颈:没有成功的策略,我们无法验证推理质量;没有高质量的推理,我们无法构建鲁棒的策略。我们引入了R&B-EnCoRe,它使模型能够通过自监督细化从互联网规模的知识中引导具身推理。通过将推理视为重要性加权变分推理中的潜在变量,模型可以生成和提炼一个精细的、特定于具身策略的推理训练数据集,而无需外部奖励、验证器或人工标注。我们在操作(模拟中的Franka Panda,硬件中的WidowX)、腿式导航(双足、轮式、自行车、四足)和自动驾驶等多种具身任务上,使用具有10亿、40亿、70亿和300亿参数的各种VLA架构验证了R&B-EnCoRe。我们的方法在操作成功率方面实现了28%的提升,在导航分数方面实现了101%的改进,并且与不加区分地推理所有可用原语的模型相比,碰撞率降低了21%。R&B-EnCoRe使模型能够提炼出可预测成功控制的推理,绕过了手动标注工程,同时将互联网规模的知识扎根于物理执行。
🔬 方法详解
问题定义:现有具身视觉-语言-动作(VLA)模型依赖于预定义的推理模板,这些模板指定了推理的基本元素,如场景中的对象、高层计划和结构化的可供性。然而,这些模板往往包含大量与当前任务无关的信息,导致模型在推理过程中受到干扰,无法有效提取关键的动作预测信号。这导致策略学习和推理质量之间存在恶性循环:没有成功的策略,就无法评估推理的质量;而没有高质量的推理,就难以构建鲁棒的策略。
核心思路:R&B-EnCoRe的核心思想是通过自监督学习的方式,从互联网规模的知识中提炼出适用于特定具身任务的推理策略。该方法将推理过程视为一个潜在变量,并利用重要性加权变分推理(Importance-Weighted Variational Inference)来学习该变量的分布。通过这种方式,模型能够自动发现并学习与成功控制相关的推理模式,而无需人工标注或外部奖励信号。
技术框架:R&B-EnCoRe的整体框架包含以下几个主要阶段:1) 数据生成:利用VLA模型生成大量的动作序列及其对应的推理过程。2) 重要性加权:根据动作序列的成功程度,对推理过程进行重要性加权。成功的动作序列对应的推理过程具有更高的权重。3) 变分推理:利用重要性加权后的数据,通过变分推理学习推理过程的潜在变量分布。4) 策略优化:利用学习到的推理过程,优化VLA模型的策略,使其能够更好地预测动作。
关键创新:R&B-EnCoRe最重要的创新在于其自监督学习的方式。与传统的监督学习方法不同,R&B-EnCoRe不需要人工标注的推理数据,而是通过自我生成和评估的方式来学习推理策略。这使得该方法能够利用互联网上大量的无标注数据,从而提高模型的泛化能力和鲁棒性。此外,R&B-EnCoRe通过重要性加权的方式,能够有效地过滤掉与成功控制无关的推理信息,从而提高模型的效率和准确性。
关键设计:R&B-EnCoRe的关键设计包括:1) 重要性权重的计算:使用动作序列的成功率作为重要性权重。2) 变分推理模型的选择:可以使用各种变分自编码器(VAE)或生成对抗网络(GAN)作为变分推理模型。3) 策略优化算法的选择:可以使用各种强化学习算法,如PPO或SAC,来优化VLA模型的策略。论文中使用了多种不同参数规模的VLA模型(1B, 4B, 7B, 30B)进行实验,以验证R&B-EnCoRe的有效性。
🖼️ 关键图片


📊 实验亮点
R&B-EnCoRe在多个具身任务上取得了显著的性能提升。在操作任务中,成功率提高了28%;在导航任务中,导航分数提高了101%;在自动驾驶任务中,碰撞率降低了21%。这些结果表明,R&B-EnCoRe能够有效地提高VLA模型的性能,使其能够更好地完成复杂的具身任务。该方法在不同参数规模的模型上均表现出良好的性能,验证了其泛化能力。
🎯 应用场景
R&B-EnCoRe具有广泛的应用前景,可应用于机器人操作、自动驾驶、智能导航等领域。通过自监督学习,该方法能够使机器人更好地理解环境,进行推理和决策,从而完成复杂的任务。该研究有望推动具身智能的发展,使机器人能够更好地与人类协作,服务于社会。
📄 摘要(原文)
Embodied Chain-of-Thought (CoT) reasoning has significantly enhanced Vision-Language-Action (VLA) models, yet current methods rely on rigid templates to specify reasoning primitives (e.g., objects in the scene, high-level plans, structural affordances). These templates can force policies to process irrelevant information that distracts from critical action-prediction signals. This creates a bottleneck: without successful policies, we cannot verify reasoning quality; without quality reasoning, we cannot build robust policies. We introduce R&B-EnCoRe, which enables models to bootstrap embodied reasoning from internet-scale knowledge through self-supervised refinement. By treating reasoning as a latent variable within importance-weighted variational inference, models can generate and distill a refined reasoning training dataset of embodiment-specific strategies without external rewards, verifiers, or human annotation. We validate R&B-EnCoRe across manipulation (Franka Panda in simulation, WidowX in hardware), legged navigation (bipedal, wheeled, bicycle, quadruped), and autonomous driving embodiments using various VLA architectures with 1B, 4B, 7B, and 30B parameters. Our approach achieves 28% gains in manipulation success, 101% improvement in navigation scores, and 21% reduction in collision-rate metric over models that indiscriminately reason about all available primitives. R&B-EnCoRe enables models to distill reasoning that is predictive of successful control, bypassing manual annotation engineering while grounding internet-scale knowledge in physical execution.