Recurrent-Depth VLA: Implicit Test-Time Compute Scaling of Vision-Language-Action Models via Latent Iterative Reasoning
作者: Yalcin Tur, Jalal Naghiyev, Haoquan Fang, Wei-Chuan Tsai, Jiafei Duan, Dieter Fox, Ranjay Krishna
分类: cs.RO
发布日期: 2026-02-08
备注: 11 Pages, Project page:https://rd-vla.github.io/
💡 一句话要点
提出Recurrent-Depth VLA,通过隐式迭代推理实现VLA模型测试时计算量自适应调整。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 迭代推理 计算自适应 机器人操作 循环神经网络
📋 核心要点
- 现有VLA模型计算量固定,无法根据任务复杂度自适应调整,CoT提示虽可变计算,但内存占用线性增长。
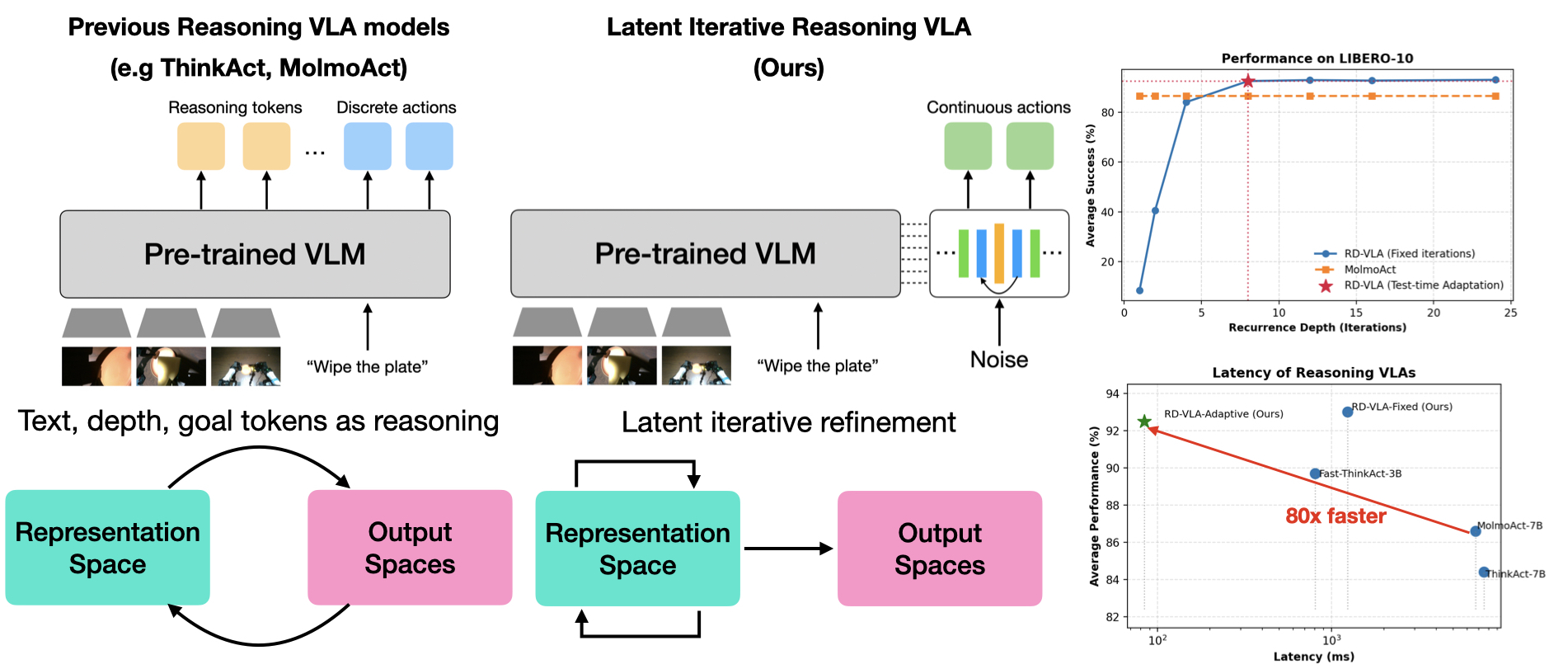
- RD-VLA通过循环迭代细化潜在空间表征,实现计算自适应,避免显式token生成,保持内存占用恒定。
- 实验表明,RD-VLA在复杂操作任务上显著提升性能,单次迭代失败的任务,多次迭代后成功率超过90%。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型依赖于固定的计算深度,无论任务的难易程度都消耗相同的计算量。虽然思维链(CoT)提示可以实现可变的计算量,但它会线性地扩展内存,并且不适合连续的动作空间。我们引入了Recurrent-Depth VLA(RD-VLA),这是一种通过潜在的迭代细化而不是显式的token生成来实现计算自适应的架构。RD-VLA采用循环的、权重绑定的动作头,支持任意的推理深度,同时保持恒定的内存占用。该模型使用截断的反向传播(TBPTT)进行训练,以有效地监督细化过程。在推理时,RD-VLA使用基于潜在收敛的自适应停止标准动态地分配计算量。在具有挑战性的操作任务上的实验表明,循环深度至关重要:单次迭代推理完全失败(成功率为0%)的任务,在四次迭代后成功率超过90%,而简单的任务则迅速饱和。RD-VLA为机器人技术中的测试时计算量提供了一种可扩展的途径,用潜在推理代替基于token的推理,从而实现恒定的内存使用,并比先前的基于推理的VLA模型快80倍。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在推理时使用固定的计算量,无法根据任务的复杂程度进行调整。对于简单的任务,这造成了计算资源的浪费;而对于复杂的任务,固定的计算量可能不足以完成任务。此外,基于Chain-of-Thought (CoT) 的方法虽然可以动态调整计算量,但是其内存占用会随着推理步骤的增加而线性增长,不适用于需要连续动作输出的任务。
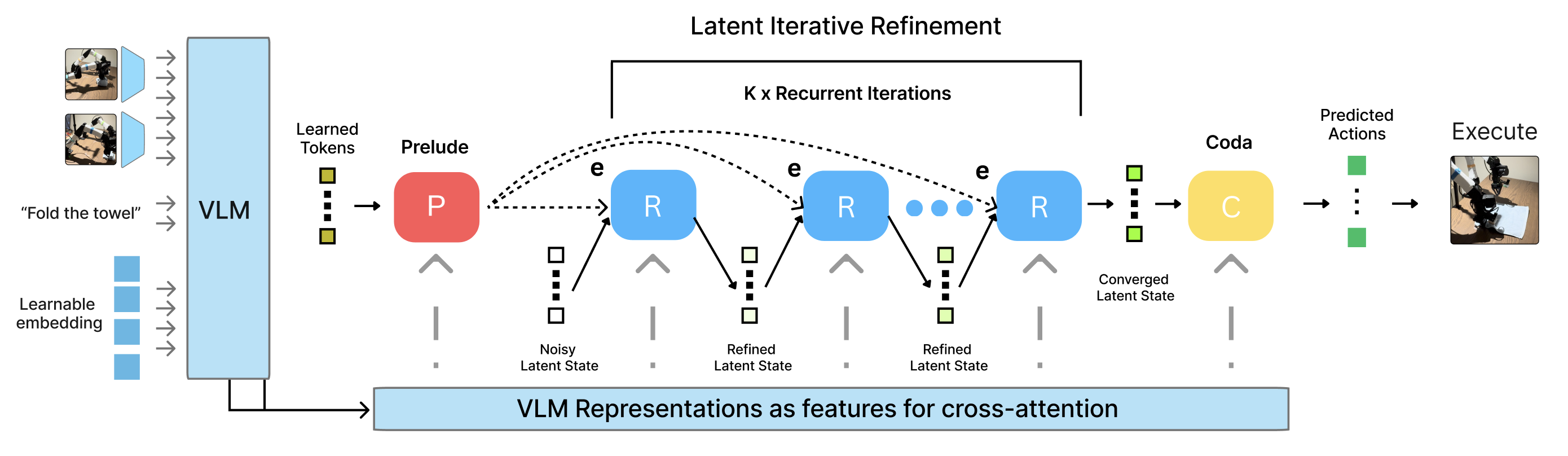
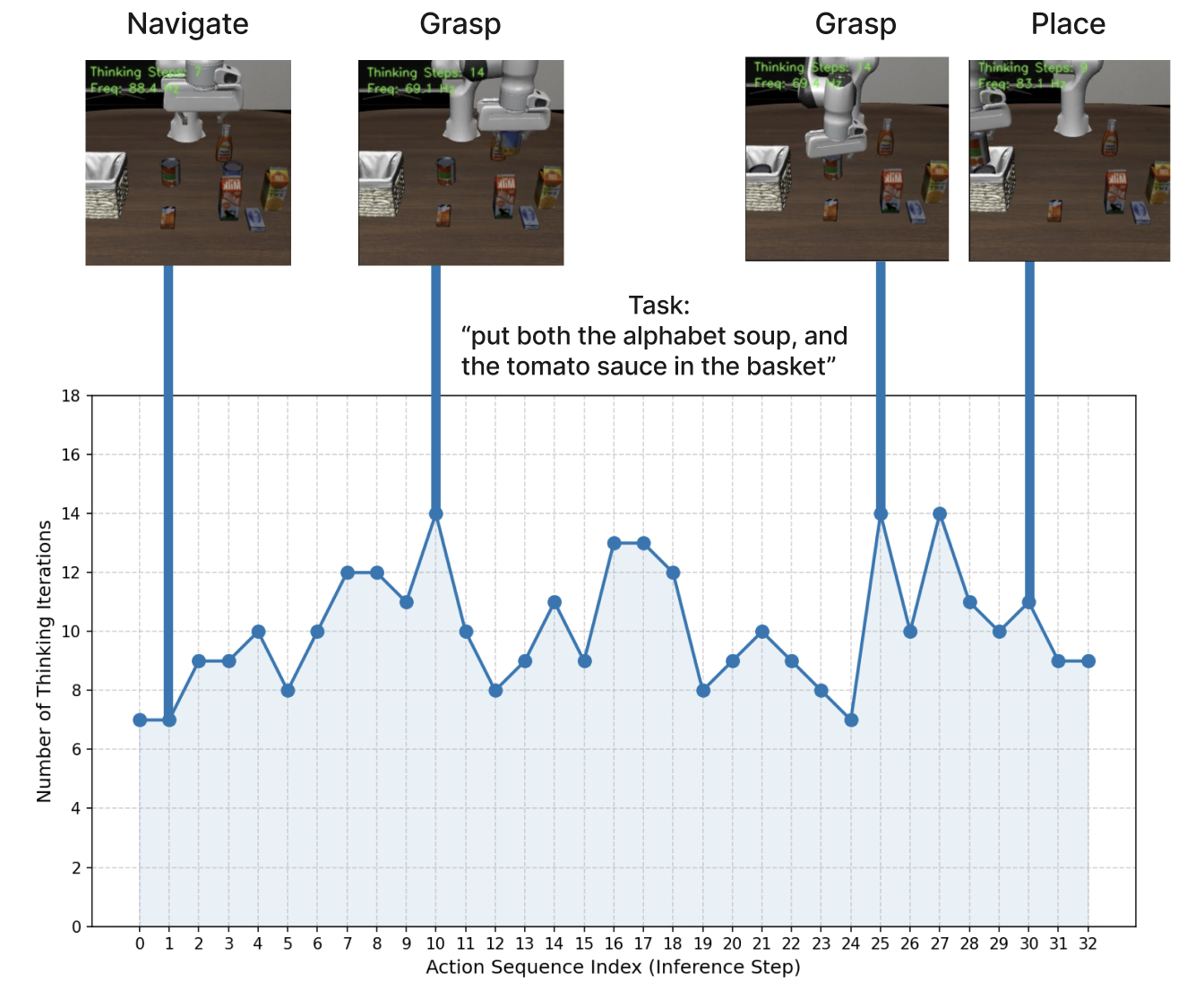
核心思路:RD-VLA的核心思路是通过循环迭代的方式,在潜在空间中逐步细化动作的预测,从而实现计算量的自适应调整。模型通过一个循环的动作头,在每一步迭代中对动作进行预测和更新。通过监控潜在空间的收敛情况,模型可以自适应地决定何时停止迭代,从而在保证性能的同时,减少计算资源的消耗。这种方法避免了显式的token生成,从而保持了内存占用的恒定。
技术框架:RD-VLA的整体架构包含视觉编码器、语言编码器、动作解码器以及循环动作头。视觉编码器和语言编码器分别将输入的图像和文本指令编码成潜在向量表示。动作解码器将视觉和语言的潜在向量融合,并初始化动作的预测。循环动作头接收动作解码器的输出,并在每一步迭代中对动作进行细化。模型使用截断的反向传播(TBPTT)进行训练,以有效地监督循环动作头的训练。
关键创新:RD-VLA的关键创新在于使用循环动作头进行潜在空间的迭代推理,从而实现计算量的自适应调整。与传统的VLA模型相比,RD-VLA可以根据任务的复杂程度动态地分配计算资源,从而提高计算效率。与基于CoT的方法相比,RD-VLA避免了显式的token生成,从而保持了内存占用的恒定,更适合于连续动作空间的任务。
关键设计:RD-VLA的关键设计包括循环动作头的结构、自适应停止标准以及训练方法。循环动作头采用权重绑定的设计,以减少参数量。自适应停止标准基于潜在空间的收敛情况,当潜在向量的变化小于一个阈值时,停止迭代。模型使用截断的反向传播(TBPTT)进行训练,以避免梯度消失或爆炸的问题。损失函数包括动作预测的损失和潜在空间收敛的损失。
🖼️ 关键图片
📊 实验亮点
RD-VLA在具有挑战性的操作任务上表现出色。在单次迭代推理完全失败(成功率为0%)的任务中,使用四次迭代后,RD-VLA的成功率超过90%。与先前的基于推理的VLA模型相比,RD-VLA实现了高达80倍的推理速度提升,同时保持了恒定的内存占用。
🎯 应用场景
RD-VLA具有广泛的应用前景,特别是在机器人操作、自动驾驶等领域。它可以应用于复杂的机器人操作任务,例如装配、抓取等,使机器人能够根据任务的难度自适应地调整计算量,提高操作效率和成功率。在自动驾驶领域,RD-VLA可以用于车辆的决策和控制,使车辆能够根据路况和交通状况动态地调整计算量,提高驾驶的安全性和舒适性。
📄 摘要(原文)
Current Vision-Language-Action (VLA) models rely on fixed computational depth, expending the same amount of compute on simple adjustments and complex multi-step manipulation. While Chain-of-Thought (CoT) prompting enables variable computation, it scales memory linearly and is ill-suited for continuous action spaces. We introduce Recurrent-Depth VLA (RD-VLA), an architecture that achieves computational adaptivity via latent iterative refinement rather than explicit token generation. RD-VLA employs a recurrent, weight-tied action head that supports arbitrary inference depth with a constant memory footprint. The model is trained using truncated backpropagation through time (TBPTT) to efficiently supervise the refinement process. At inference, RD-VLA dynamically allocates compute using an adaptive stopping criterion based on latent convergence. Experiments on challenging manipulation tasks show that recurrent depth is critical: tasks that fail entirely (0 percent success) with single-iteration inference exceed 90 percent success with four iterations, while simpler tasks saturate rapidly. RD-VLA provides a scalable path to test-time compute in robotics, replacing token-based reasoning with latent reasoning to achieve constant memory usage and up to 80x inference speedup over prior reasoning-based VLA models. Project page: https://rd-vla.github.io/