RLinf-USER: A Unified and Extensible System for Real-World Online Policy Learning in Embodied AI
作者: Hongzhi Zang, Shu'ang Yu, Hao Lin, Tianxing Zhou, Zefang Huang, Zhen Guo, Xin Xu, Jiakai Zhou, Yuze Sheng, Shizhe Zhang, Feng Gao, Wenhao Tang, Yufeng Yue, Quanlu Zhang, Xinlei Chen, Chao Yu, Yu Wang
分类: cs.RO
发布日期: 2026-02-08 (更新: 2026-02-12)
💡 一句话要点
提出RLinf-USER,用于具身智能中真实世界在线策略学习的统一可扩展系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 在线策略学习 强化学习 机器人系统 云边协同
📋 核心要点
- 真实世界在线策略学习面临数据收集难、异构部署复杂和长时程训练困难等挑战,现有方法难以有效解决。
- RLinf-USER通过统一硬件抽象、自适应通信平面和异步学习框架,实现了对异构机器人资源的高效管理和利用。
- 实验结果表明,RLinf-USER支持多机器人协调、边缘-云协作和长时间异步训练,为真实世界策略学习提供了有效方案。
📝 摘要(中文)
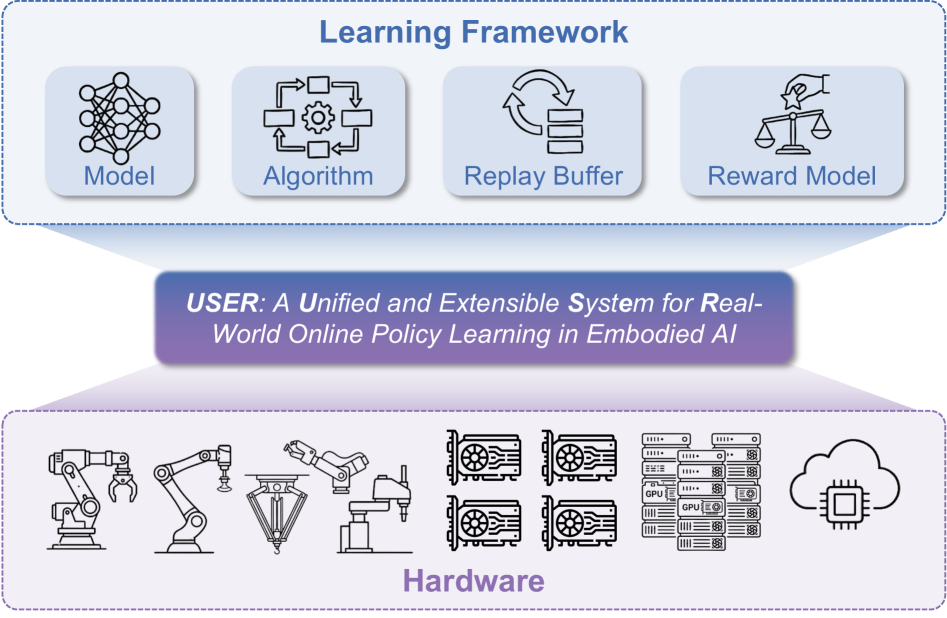
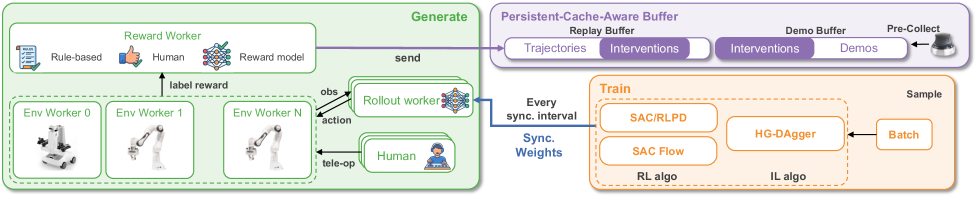
本文提出RLinf-USER,一个用于真实世界在线策略学习的统一且可扩展的系统。与模拟环境不同,真实世界系统无法随意加速、低成本重置或大规模复制,这使得可扩展的数据收集、异构部署和长时程有效训练变得困难。USER将物理机器人视为与GPU同等重要的硬件资源,通过统一的硬件抽象层实现异构机器人的自动发现、管理和调度。为了解决云边通信问题,USER引入了具有隧道网络、用于流量本地化的分布式数据通道和流式多处理器感知权重同步的自适应通信平面,以调节GPU侧的开销。在此基础设施之上,USER将学习组织为一个完全异步的框架,具有持久的、缓存感知的缓冲区,从而能够进行高效的长时程实验,并具有强大的崩溃恢复和历史数据重用能力。此外,USER为奖励、算法和策略提供了可扩展的抽象,支持在统一的pipeline中进行CNN/MLP、生成策略和大型视觉-语言-动作(VLA)模型的在线模仿或强化学习。在模拟和真实世界中的结果表明,USER能够实现多机器人协调、异构机械臂、边缘-云协作与大型模型以及长时间运行的异步训练,为真实世界在线策略学习提供了一个统一且可扩展的系统基础。
🔬 方法详解
问题定义:真实世界在线策略学习面临着数据收集、异构部署和长时程训练三大挑战。现有方法难以在真实机器人上进行大规模、高效的策略学习,主要痛点在于系统层面的支持不足,无法有效管理和利用异构机器人资源,以及解决云边通信和数据同步问题。
核心思路:RLinf-USER的核心思路是将物理机器人视为与GPU同等重要的硬件资源,通过统一的系统架构来管理和调度这些资源。通过构建统一的硬件抽象层、自适应通信平面和异步学习框架,实现对异构机器人的高效利用,并解决云边通信和数据同步问题,从而支持大规模、长时程的在线策略学习。
技术框架:RLinf-USER的整体架构包含以下几个主要模块:1) 统一硬件抽象层:实现对异构机器人的自动发现、管理和调度。2) 自适应通信平面:通过隧道网络、分布式数据通道和流式多处理器感知权重同步,解决云边通信问题。3) 异步学习框架:利用持久的、缓存感知的缓冲区,实现高效的长时程实验,并支持崩溃恢复和历史数据重用。4) 可扩展的抽象:为奖励、算法和策略提供可扩展的抽象,支持多种模型的在线学习。
关键创新:RLinf-USER最重要的技术创新在于其系统层面的统一设计,将物理机器人视为一等公民,并提供了一套完整的解决方案来管理和利用这些资源。与现有方法相比,RLinf-USER不仅关注算法层面,更注重系统层面的支持,从而能够更好地应对真实世界在线策略学习的挑战。
关键设计:RLinf-USER的关键设计包括:1) 统一硬件抽象层的具体实现,如何实现对不同类型机器人的统一管理。2) 自适应通信平面的具体实现,如何根据网络状况动态调整通信策略。3) 异步学习框架中缓存感知缓冲区的具体实现,如何提高数据访问效率。4) 奖励、算法和策略的可扩展抽象的具体实现,如何支持多种模型的在线学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RLinf-USER能够有效支持多机器人协调、异构机械臂操作和边缘-云协作。该系统在真实机器人上的实验验证了其可行性和有效性,为真实世界在线策略学习提供了一个有力的工具。
🎯 应用场景
RLinf-USER可广泛应用于机器人自动化、智能制造、物流仓储等领域。通过在线策略学习,机器人能够不断适应新的环境和任务,提高工作效率和智能化水平。该系统为大规模机器人集群的部署和管理提供了基础,有望推动机器人技术在各行业的广泛应用。
📄 摘要(原文)
Online policy learning directly in the physical world is a promising yet challenging direction for embodied intelligence. Unlike simulation, real-world systems cannot be arbitrarily accelerated, cheaply reset, or massively replicated, which makes scalable data collection, heterogeneous deployment, and long-horizon effective training difficult. These challenges suggest that real-world policy learning is not only an algorithmic issue but fundamentally a systems problem. We present USER, a Unified and extensible SystEm for Real-world online policy learning. USER treats physical robots as first-class hardware resources alongside GPUs through a unified hardware abstraction layer, enabling automatic discovery, management, and scheduling of heterogeneous robots. To address cloud-edge communication, USER introduces an adaptive communication plane with tunneling-based networking, distributed data channels for traffic localization, and streaming-multiprocessor-aware weight synchronization to regulate GPU-side overhead. On top of this infrastructure, USER organizes learning as a fully asynchronous framework with a persistent, cache-aware buffer, enabling efficient long-horizon experiments with robust crash recovery and reuse of historical data. In addition, USER provides extensible abstractions for rewards, algorithms, and policies, supporting online imitation or reinforcement learning of CNN/MLP, generative policies, and large vision-language-action (VLA) models within a unified pipeline. Results in both simulation and the real world show that USER enables multi-robot coordination, heterogeneous manipulators, edge-cloud collaboration with large models, and long-running asynchronous training, offering a unified and extensible systems foundation for real-world online policy learning.