CoLF: Learning Consistent Leader-Follower Policies for Vision-Language-Guided Multi-Robot Cooperative Transport
作者: Joachim Yann Despature, Kazuki Shibata, Takamitsu Matsubara
分类: cs.RO
发布日期: 2026-02-08
备注: 9 pages, 5 figures
💡 一句话要点
提出CoLF框架,解决视觉-语言引导下多机器人协同搬运中的角色一致性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多机器人协同 强化学习 视觉语言导航 领导者跟随者 互信息 机器人控制
📋 核心要点
- 多机器人协同搬运面临感知不对齐问题,源于视点差异和语言歧义导致理解不一致。
- CoLF框架通过非对称策略设计和互信息最大化,实现稳定的领导者-跟随者角色区分。
- 仿真和真实机器人实验验证了CoLF的有效性,提升了多机器人协同搬运的性能。
📝 摘要(中文)
本研究致力于解决视觉-语言引导的多机器人协同搬运问题,其中每个机器人基于自身相机观测到的图像理解自然语言指令。去中心化环境下的一个关键挑战是机器人之间的感知不对齐,视点差异和语言歧义会导致不一致的理解,从而降低协同搬运的性能。为了缓解这个问题,我们采用了一种依赖型的领导者-跟随者设计,其中一个机器人作为领导者,另一个作为跟随者。虽然这种结构看起来很简单,但使用独立和对称的智能体进行学习通常会产生对称或不稳定的行为,而没有明确的归纳偏置。为了解决这个挑战,我们提出了Consistent Leader-Follower (CoLF),这是一个多智能体强化学习(MARL)框架,用于稳定的领导者-跟随者角色区分。CoLF包含两个关键组件:(1)一种非对称策略设计,可以诱导领导者-跟随者角色区分;(2)一种基于互信息的训练目标,可以最大化变分下界,鼓励跟随者从其局部观察中预测领导者的动作。领导者和跟随者策略在集中式训练和分散式执行(CTDE)框架下共同优化,以平衡任务执行和一致的协同行为。我们使用两个四足机器人在仿真和真实机器人实验中验证了CoLF。
🔬 方法详解
问题定义:论文旨在解决视觉-语言引导下多机器人协同搬运任务中,由于机器人之间感知不对齐导致的协同效率低下的问题。现有方法在去中心化环境中,难以保证各个机器人对语言指令和环境信息的理解一致,尤其是在视角差异和语言歧义存在的情况下,容易出现角色混淆和行为冲突。
核心思路:论文的核心思路是引入领导者-跟随者(Leader-Follower)的角色设定,并设计一种能够学习到稳定角色区分的强化学习框架。通过明确的角色划分,降低了机器人之间行为的不确定性,从而提升协同效率。同时,通过互信息最大化,鼓励跟随者学习领导者的行为模式,进一步增强协同一致性。
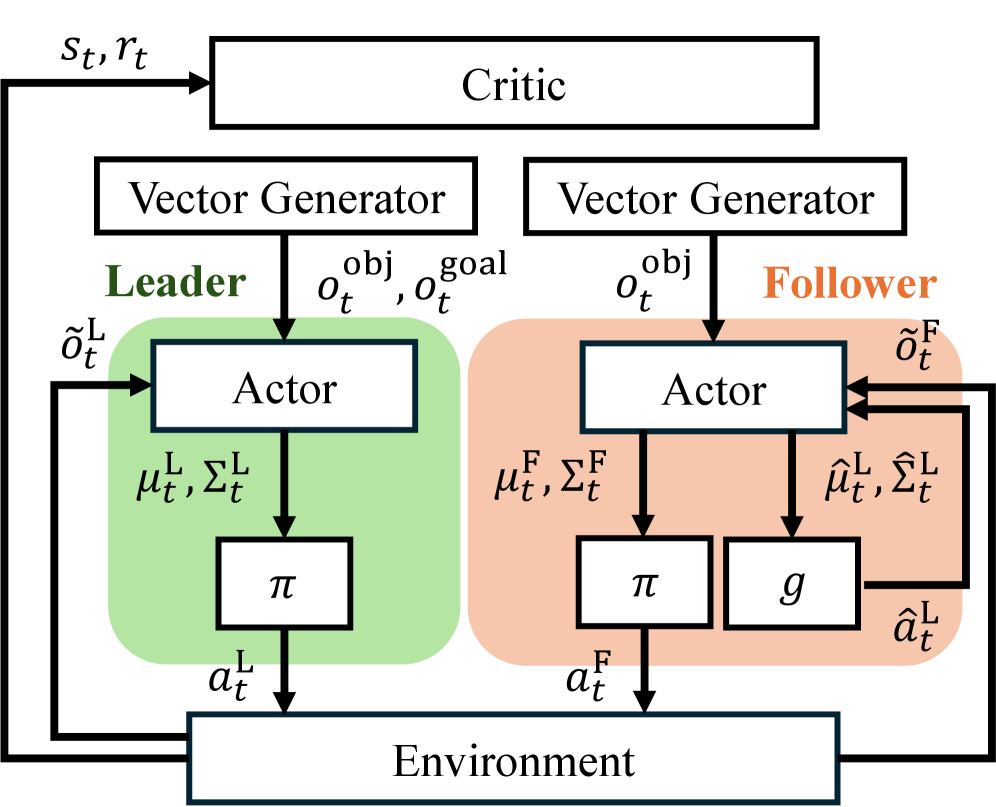
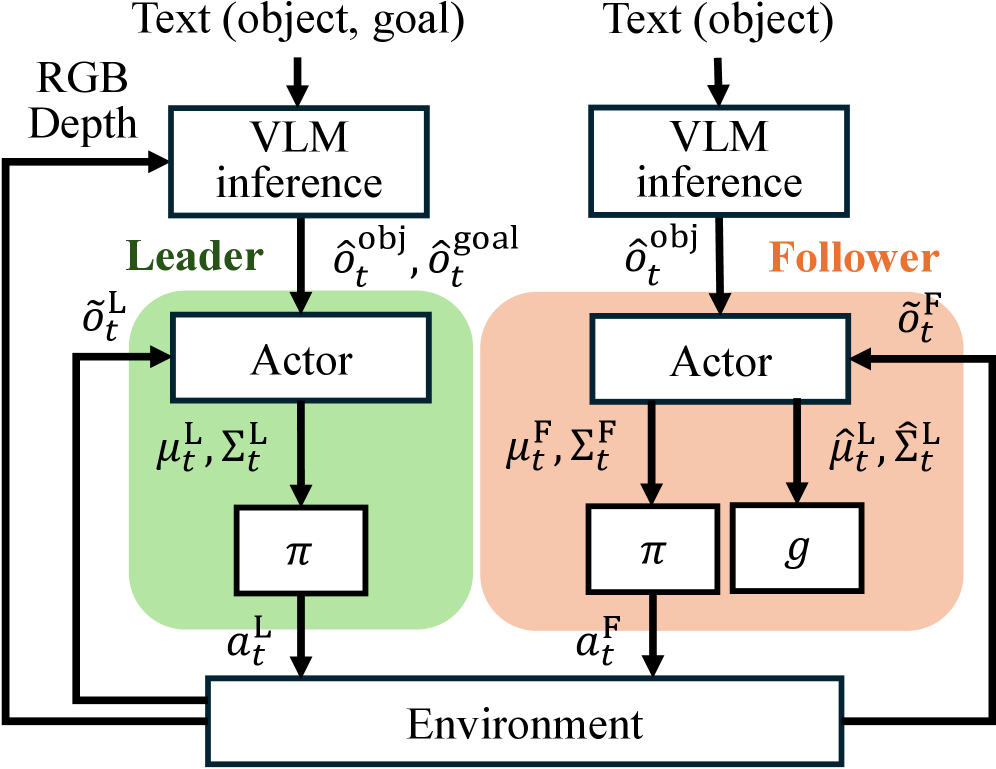
技术框架:CoLF框架采用集中式训练、分散式执行(CTDE)的MARL范式。整体流程如下:1. 定义领导者和跟随者两个角色,并分别设计对应的策略网络。2. 使用非对称策略设计,为领导者和跟随者赋予不同的网络结构或输入信息,以诱导角色区分。3. 设计基于互信息的训练目标,鼓励跟随者从自身观测中预测领导者的动作,从而学习领导者的行为模式。4. 在集中式训练阶段,利用全局信息优化领导者和跟随者的策略。5. 在分散式执行阶段,每个机器人根据自身策略和局部观测独立行动。
关键创新:论文的关键创新在于提出了Consistent Leader-Follower (CoLF) 框架,该框架通过以下两点实现了稳定的领导者-跟随者角色区分:1. 非对称策略设计:通过差异化的网络结构或输入信息,为领导者和跟随者赋予不同的角色特征,从而避免对称或不稳定的行为。2. 基于互信息的训练目标:通过最大化跟随者预测领导者动作的互信息,鼓励跟随者学习领导者的行为模式,从而增强协同一致性。与现有方法相比,CoLF能够更有效地解决感知不对齐问题,提升多机器人协同搬运的性能。
关键设计:1. 非对称策略设计:领导者策略网络可以接收全局状态信息或更丰富的环境特征,而跟随者策略网络则只接收局部观测。2. 互信息损失函数:使用变分下界来近似互信息,并将其作为额外的奖励信号,引导跟随者学习领导者的行为模式。具体而言,可以使用一个独立的网络来预测领导者的动作,并将其预测结果与领导者的真实动作进行比较,计算交叉熵损失。3. 集中式训练:使用Actor-Critic算法,利用全局状态信息训练领导者和跟随者的策略网络。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoLF框架在仿真和真实机器人实验中均取得了显著的性能提升。与基线方法相比,CoLF能够更有效地学习到稳定的领导者-跟随者角色,从而提升协同搬运的成功率和效率。具体数据指标(例如成功率、完成时间等)在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于物流仓储、灾难救援、智能制造等领域,实现多机器人高效协同完成复杂任务。例如,在物流仓储中,多个机器人可以协同搬运大型货物;在灾难救援中,多个机器人可以协同搜索和救援幸存者;在智能制造中,多个机器人可以协同完成装配任务。该研究有助于提升机器人系统的智能化水平和应用范围。
📄 摘要(原文)
In this study, we address vision-language-guided multi-robot cooperative transport, where each robot grounds natural-language instructions from onboard camera observations. A key challenge in this decentralized setting is perceptual misalignment across robots, where viewpoint differences and language ambiguity can yield inconsistent interpretations and degrade cooperative transport. To mitigate this problem, we adopt a dependent leader-follower design, where one robot serves as the leader and the other as the follower. Although such a leader-follower structure appears straightforward, learning with independent and symmetric agents often yields symmetric or unstable behaviors without explicit inductive biases. To address this challenge, we propose Consistent Leader-Follower (CoLF), a multi-agent reinforcement learning (MARL) framework for stable leader-follower role differentiation. CoLF consists of two key components: (1) an asymmetric policy design that induces leader-follower role differentiation, and (2) a mutual-information-based training objective that maximizes a variational lower bound, encouraging the follower to predict the leader's action from its local observation. The leader and follower policies are jointly optimized under the centralized training and decentralized execution (CTDE) framework to balance task execution and consistent cooperative behaviors. We validate CoLF in both simulation and real-robot experiments using two quadruped robots. The demonstration video is available at https://sites.google.com/view/colf/.