LCLA: Language-Conditioned Latent Alignment for Vision-Language Navigation
作者: Nitesh Subedi, Adam Haroon, Samuel Tetteh, Prajwal Koirala, Cody Fleming, Soumik Sarkar
分类: cs.RO
发布日期: 2026-02-07 (更新: 2026-02-10)
💡 一句话要点
提出LCLA框架以解决视觉语言导航中的感知与控制问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 潜在对齐 模块化学习 感知与控制 零-shot泛化
📋 核心要点
- 现有的视觉语言导航方法在感知与控制之间缺乏有效的对齐,导致性能不稳定。
- LCLA框架通过将感官观察与专家策略的潜在表示对齐,简化了视觉运动学习过程。
- 实验结果显示,LCLA在室内导航任务中实现了强大的性能,并在未见环境中表现出色。
📝 摘要(中文)
我们提出了LCLA(语言条件下的潜在对齐)框架,用于视觉语言导航,通过将感官观察与专家策略的潜在表示对齐,学习模块化的感知-行动接口。首先,专家在特权状态信息下进行训练,形成足够的控制潜在空间,然后冻结其潜在接口和动作头。接着,训练一个轻量级适配器,通过冻结的视觉-语言模型将原始视觉-语言观察映射到专家的潜在空间,从而将视觉运动学习问题简化为监督潜在对齐,而非端到端策略优化。这种解耦强化了感知与控制之间的稳定契约,使得专家行为能够在不同感知模态和环境变化中重用。我们在视觉语言室内导航任务中实例化LCLA,结果表明对齐的潜在空间在分布内表现良好,并在未见环境、光照条件和视角下实现了强大的零-shot泛化,同时在推理时保持轻量级。
🔬 方法详解
问题定义:本论文旨在解决视觉语言导航中感知与控制之间的对齐问题。现有方法往往依赖于端到端的策略优化,导致在不同环境下的性能不稳定和泛化能力不足。
核心思路:LCLA框架的核心思想是通过对齐感官观察与专家策略的潜在表示,来实现模块化的感知-行动接口。这种设计使得感知与控制的学习过程可以分离,从而提高了系统的稳定性和重用性。
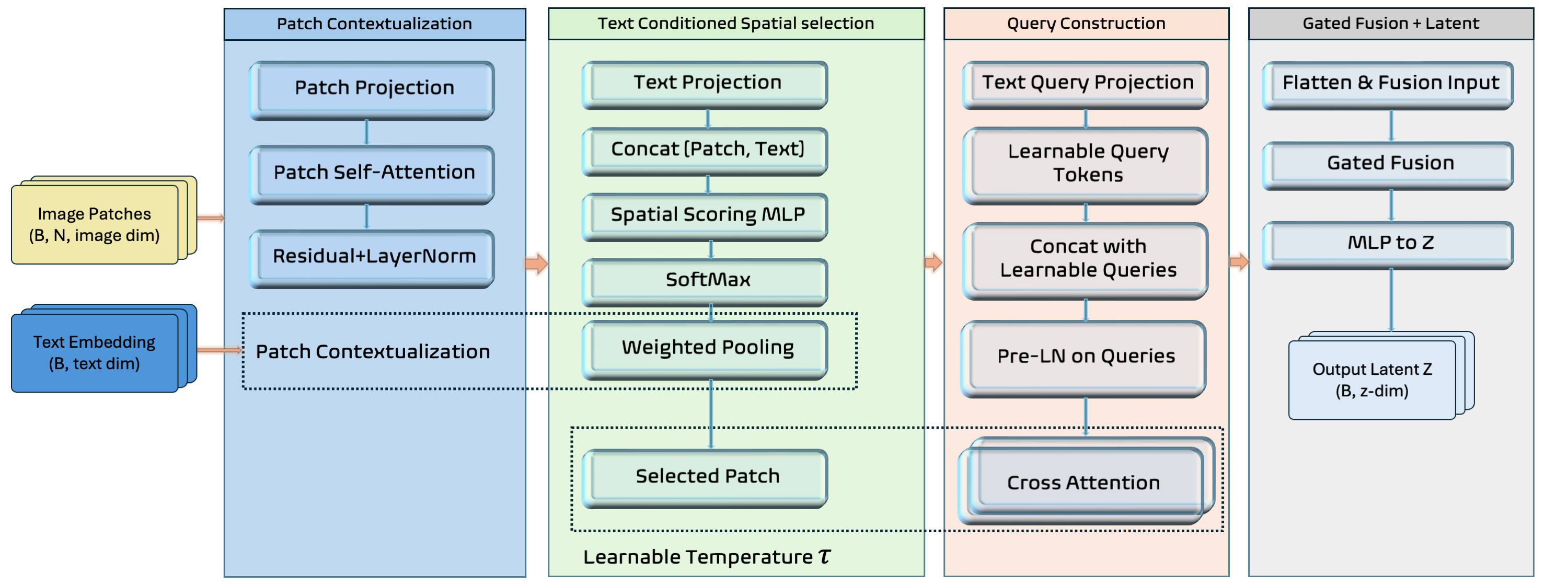
技术框架:LCLA的整体架构包括三个主要模块:首先是专家策略的训练,利用特权状态信息形成潜在空间;其次是冻结专家的潜在接口和动作头;最后是训练轻量级适配器,将原始视觉-语言观察映射到潜在空间。
关键创新:LCLA的主要创新在于将视觉运动学习问题转化为监督潜在对齐,而非传统的端到端策略优化。这种方法有效地解耦了感知与控制,增强了系统的灵活性和适应性。
关键设计:在设计中,使用了冻结的视觉-语言模型作为适配器的基础,确保了在推理时的轻量级和高效性。同时,损失函数的选择也强调了潜在对齐的重要性,以确保模型在不同环境下的鲁棒性。
🖼️ 关键图片

📊 实验亮点
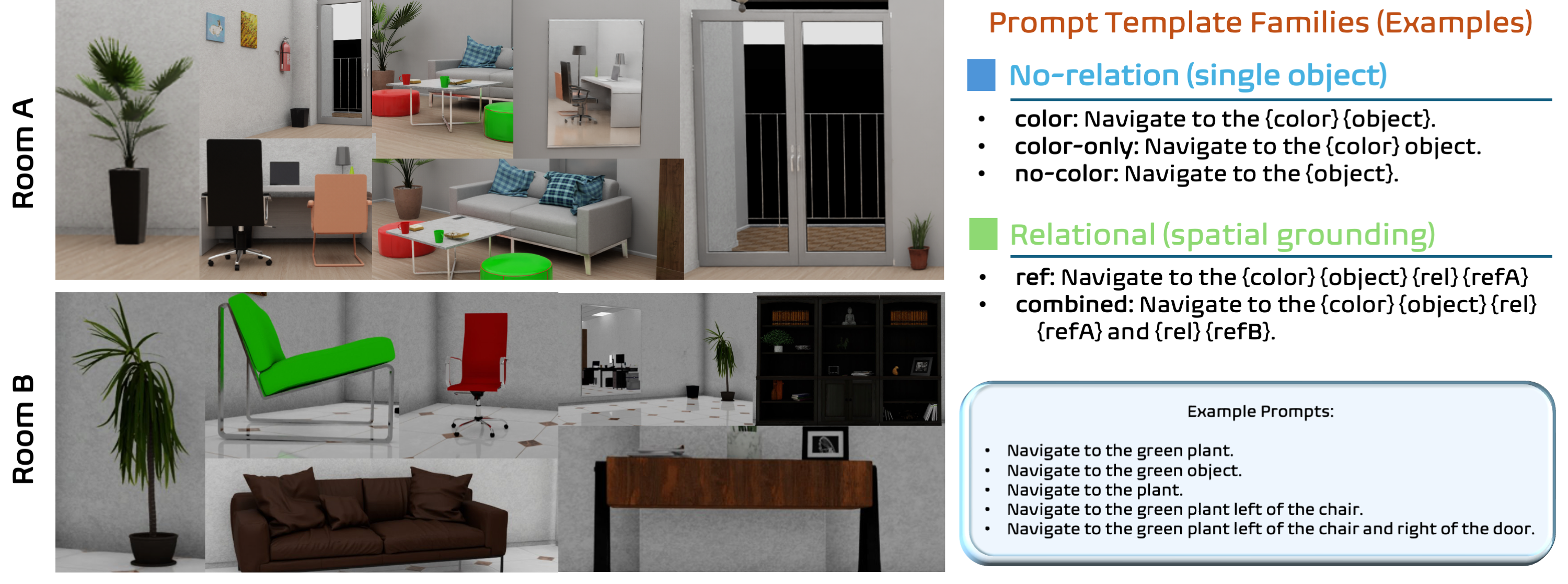
在实验中,LCLA在视觉语言室内导航任务中表现出色,达到了强大的分布内性能,并在未见环境、光照条件和视角下实现了零-shot泛化。与基线方法相比,LCLA在多个测试条件下均显示出显著的性能提升,验证了其在实际应用中的有效性和可靠性。
🎯 应用场景
LCLA框架具有广泛的应用潜力,尤其是在机器人导航、智能家居和增强现实等领域。通过提高视觉语言导航的稳定性和泛化能力,该研究能够推动多模态交互系统的发展,提升用户体验和系统效率。未来,LCLA可能在更复杂的环境中实现更高水平的自主导航和决策支持。
📄 摘要(原文)
We propose LCLA (Language-Conditioned Latent Alignment), a framework for vision-language navigation that learns modular perception-action interfaces by aligning sensory observations to a latent representation of an expert policy. The expert is first trained with privileged state information, inducing a latent space sufficient for control, after which its latent interface and action head are frozen. A lightweight adapter is then trained to map raw visual-language observations, via a frozen vision-language model, into the expert's latent space, reducing the problem of visuomotor learning to supervised latent alignment rather than end-to-end policy optimization. This decoupling enforces a stable contract between perception and control, enabling expert behavior to be reused across sensing modalities and environmental variations. We instantiate LCLA and evaluate it on a vision-language indoor navigation task, where aligned latent spaces yield strong in-distribution performance and robust zero-shot generalization to unseen environments, lighting conditions, and viewpoints while remaining lightweight at inference time.