Differentiate-and-Inject: Enhancing VLAs via Functional Differentiation Induced by In-Parameter Structural Reasoning
作者: Jingyi Hou, Leyu Zhou, Chenchen Jing, Jinghan Yang, Xinbo Yu, Wei He
分类: cs.RO
发布日期: 2026-02-07
💡 一句话要点
提出iSTAR框架,通过参数空间结构推理增强视觉-语言-动作模型的任务级理解能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 任务级推理 参数空间结构推理 功能微分 机器人操作
📋 核心要点
- 现有VLA模型难以进行任务级推理,依赖提示或端到端训练存在局限性。
- iSTAR框架将任务级语义结构嵌入模型参数,实现差异化的任务级推理。
- 实验表明,iSTAR在任务分解和成功率上优于现有方法,泛化能力更强。
📝 摘要(中文)
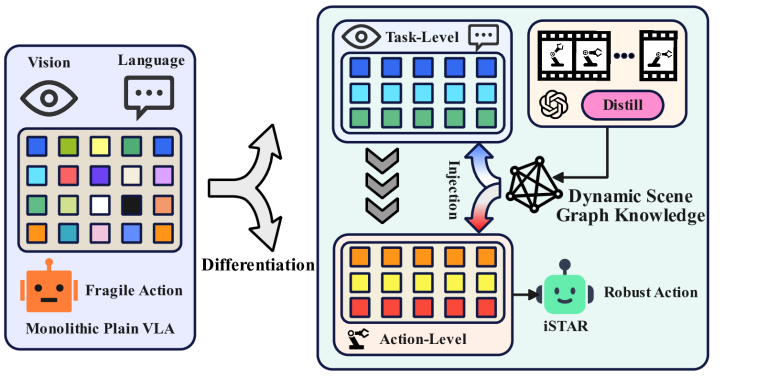
现有的视觉-语言-动作(VLA)模型在任务级推理方面存在困难。它们要么依赖于基于提示的上下文分解,这种方法不稳定且对语言变化敏感,要么依赖于端到端的长程训练,这需要大规模的演示数据并将任务级推理与低级控制纠缠在一起。本文提出了参数内结构化任务推理(iSTAR)框架,通过参数内结构推理诱导的功能微分来增强VLA模型。iSTAR不是将VLA视为单一策略,而是将任务级语义结构直接嵌入到模型参数中,从而实现差异化的任务级推理,而无需外部规划器或手工制作的提示输入。这种注入的结构采取隐式动态场景图知识的形式,捕获参数空间中的对象关系、子任务语义和任务级依赖关系。在各种操作基准测试中,iSTAR实现了比上下文和端到端VLA基线更可靠的任务分解和更高的成功率,证明了参数空间结构推理在功能微分和提高任务变化泛化能力方面的有效性。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在理解和执行复杂任务时,面临着任务级推理的挑战。它们要么依赖于不稳定的prompt-based in-context decomposition,对语言变化敏感;要么依赖于需要大量演示数据的端到端长程训练,这使得任务级推理与低级控制相互纠缠,难以解耦。因此,如何让VLA模型更有效地进行任务级推理,并具备更好的泛化能力,是一个亟待解决的问题。
核心思路:iSTAR的核心思路是将任务级的语义结构直接嵌入到VLA模型的参数空间中,而不是依赖于外部的规划器或手工设计的prompt。通过这种方式,模型可以在参数空间中进行结构化的任务推理,从而实现功能上的微分。这种方法避免了传统方法中任务级推理与低级控制的纠缠,提高了模型的稳定性和泛化能力。
技术框架:iSTAR框架主要包含以下几个关键模块:首先,通过某种方式(论文中未明确说明具体方法,标记为未知)将任务级的语义结构编码成隐式的动态场景图知识。然后,将这些知识注入到VLA模型的参数空间中。在推理阶段,模型利用这些嵌入的结构化知识进行任务分解和决策。整个过程无需外部规划器或手工设计的prompt,而是通过参数空间中的结构化推理来实现。
关键创新:iSTAR最重要的创新点在于它将任务级的语义结构直接嵌入到VLA模型的参数空间中。这种参数空间结构推理的方式,使得模型能够进行差异化的任务级推理,而无需依赖于外部的规划器或手工设计的prompt。这与传统的VLA模型将任务级推理与低级控制纠缠在一起的做法有本质的区别。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构等技术细节。但是,可以推测,为了将任务级的语义结构嵌入到参数空间中,可能需要设计特定的损失函数来约束参数的学习,使其能够反映对象关系、子任务语义和任务级依赖关系。此外,可能还需要设计特定的网络结构来支持参数空间中的结构化推理。
🖼️ 关键图片


📊 实验亮点
iSTAR在多个操作基准测试中取得了显著的成果,相较于in-context learning和end-to-end VLA基线,iSTAR实现了更可靠的任务分解和更高的成功率。这表明,通过参数空间结构推理进行功能微分,可以有效地提高VLA模型的性能和泛化能力。具体的性能提升数据在摘要中没有给出,需要在论文正文中查找。
🎯 应用场景
iSTAR框架具有广泛的应用前景,可以应用于各种需要机器人进行复杂操作任务的场景,例如智能制造、家庭服务、医疗辅助等。通过提高机器人对任务的理解和执行能力,可以实现更高效、更智能的自动化操作,从而提高生产效率和服务质量。此外,该研究还可以促进人机协作的发展,使机器人能够更好地理解人类的意图,并与人类协同完成任务。
📄 摘要(原文)
As robots are expected to perform increasingly diverse tasks, they must understand not only low-level actions but also the higher-level structure that determines how a task should unfold. Existing vision-language-action (VLA) models struggle with this form of task-level reasoning. They either depend on prompt-based in-context decomposition, which is unstable and sensitive to linguistic variations, or end-to-end long-horizon training, which requires large-scale demonstrations and entangles task-level reasoning with low-level control. We present in-parameter structured task reasoning (iSTAR), a framework for enhancing VLA models via functional differentiation induced by in-parameter structural reasoning. Instead of treating VLAs as monolithic policies, iSTAR embeds task-level semantic structure directly into model parameters, enabling differentiated task-level inference without external planners or handcrafted prompt inputs. This injected structure takes the form of implicit dynamic scene-graph knowledge that captures object relations, subtask semantics, and task-level dependencies in parameter space. Across diverse manipulation benchmarks, iSTAR achieves more reliable task decompositions and higher success rates than both in-context and end-to-end VLA baselines, demonstrating the effectiveness of parameter-space structural reasoning for functional differentiation and improved generalization across task variations.