Bridging Speech, Emotion, and Motion: a VLM-based Multimodal Edge-deployable Framework for Humanoid Robots
作者: Songhua Yang, Xuetao Li, Xuanye Fei, Mengde Li, Miao Li
分类: cs.RO, cs.AI
发布日期: 2026-02-07
💡 一句话要点
提出SeM²框架,利用VLM驱动人形机器人实现情感丰富的多模态交互,并支持边缘部署。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 人形机器人 多模态融合 视觉语言模型 边缘计算
📋 核心要点
- 现有的人形机器人缺乏协调的语音、面部表情和手势,难以实现情感丰富的多模态交互。
- SeM²框架利用视觉语言模型,通过多模态感知、思维链推理和语义序列对齐,实现情感连贯的多模态交互。
- 实验结果表明,该方法在自然度、情感清晰度和模态一致性方面显著优于单模态基线,边缘部署版本保持了95%的性能。
📝 摘要(中文)
为了弥合语音、情感和动作之间的鸿沟,本文提出了SeM²框架,这是一个基于视觉语言模型(VLM)的框架,旨在协调情感连贯的多模态交互。该框架包含三个关键组件:一个用于捕获用户上下文线索的多模态感知模块;一个用于响应规划的思维链推理模块;以及一个新颖的语义序列对齐机制(SSAM),用于确保口头内容和物理表达之间的精确时间协调。我们实现了云端版本和边缘部署版本(SeM²_e),后者通过知识蒸馏在边缘硬件上高效运行,同时保持了95%的相对性能。综合评估表明,我们的方法在自然度、情感清晰度和模态一致性方面显著优于单模态基线,从而推动了社交表达型人形机器人在各种现实环境中的应用。
🔬 方法详解
问题定义:论文旨在解决人形机器人缺乏情感丰富且协调的多模态交互能力的问题。现有方法通常依赖于单模态输入或简单的规则驱动,难以捕捉用户的情感状态和意图,也难以生成自然流畅的语音、表情和动作。此外,实际部署中对设备端自主运行的需求也难以满足。
核心思路:论文的核心思路是利用视觉语言模型(VLM)的强大能力,将语音、视觉和文本信息融合,并通过思维链推理进行响应规划,最后通过语义序列对齐机制确保不同模态输出之间的时间同步和情感一致性。这种设计旨在使机器人能够更自然、更有效地与人类进行交互。
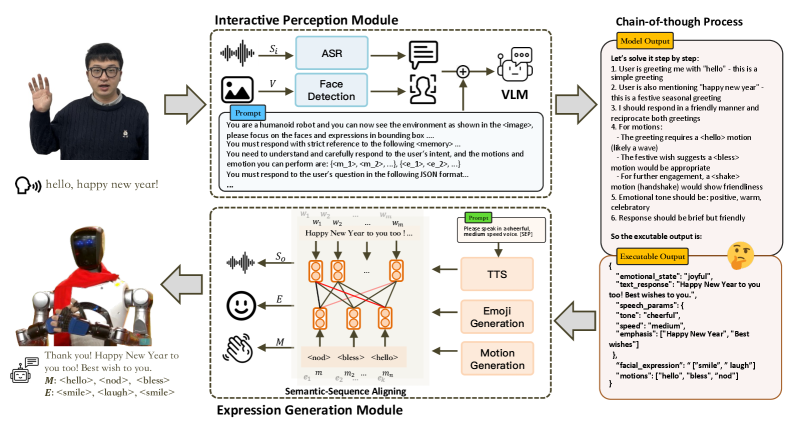
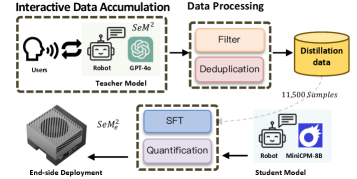
技术框架:SeM²框架包含三个主要模块:1) 多模态感知模块,用于捕获用户的语音、面部表情和肢体语言等上下文信息;2) 思维链推理模块,利用VLM进行响应规划,生成包含语音内容、情感表达和动作序列的交互方案;3) 语义序列对齐机制(SSAM),用于确保语音内容和物理表达之间的时间协调,避免出现不同模态信息不一致的情况。框架同时支持云端部署和边缘部署,边缘部署版本通过知识蒸馏进行优化。
关键创新:论文的关键创新在于提出了语义序列对齐机制(SSAM),该机制能够有效地解决多模态输出的时间同步问题,确保语音内容和物理表达在时间上保持一致,从而提升交互的自然性和流畅性。此外,边缘部署版本的实现也使得该框架能够在资源受限的设备上运行,具有更广泛的应用前景。
关键设计:SSAM的具体实现细节未知,但可以推测其可能涉及动态时间规整(DTW)或注意力机制等技术,用于对齐不同模态的序列数据。边缘部署版本的知识蒸馏过程的具体参数设置和损失函数未知,但其目标是尽可能地保留原始模型的性能,同时减小模型的大小和计算复杂度。VLM的具体选择也未知,但需要具备强大的多模态理解和生成能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SeM²框架在自然度、情感清晰度和模态一致性方面显著优于单模态基线。边缘部署版本(SeM²_e)通过知识蒸馏,在保持95%相对性能的同时,实现了在边缘硬件上的高效运行。这些结果验证了该框架的有效性和实用性。
🎯 应用场景
该研究成果可应用于各种人机交互场景,例如智能家居助手、教育机器人、医疗陪护机器人等。通过提供更自然、更具情感表达能力的交互方式,可以提升用户体验,增强机器人的实用性和亲和力。未来,该技术有望推动人形机器人在更多领域得到应用。
📄 摘要(原文)
Effective human-robot interaction requires emotionally rich multimodal expressions, yet most humanoid robots lack coordinated speech, facial expressions, and gestures. Meanwhile, real-world deployment demands on-device solutions that can operate autonomously without continuous cloud connectivity. To bridging \underline{\textit{S}}peech, \underline{\textit{E}}motion, and \underline{\textit{M}}otion, we present \textit{SeM$^2$}, a Vision Language Model-based framework that orchestrates emotionally coherent multimodal interactions through three key components: a multimodal perception module capturing user contextual cues, a Chain-of-Thought reasoning for response planning, and a novel Semantic-Sequence Aligning Mechanism (SSAM) that ensures precise temporal coordination between verbal content and physical expressions. We implement both cloud-based and \underline{\textit{e}}dge-deployed versions (\textit{SeM$^2_e$}), with the latter knowledge distilled to operate efficiently on edge hardware while maintaining 95\% of the relative performance. Comprehensive evaluations demonstrate that our approach significantly outperforms unimodal baselines in naturalness, emotional clarity, and modal coherence, advancing socially expressive humanoid robotics for diverse real-world environments.