Trace-Focused Diffusion Policy for Multi-Modal Action Disambiguation in Long-Horizon Robotic Manipulation
作者: Yuxuan Hu, Xiangyu Chen, Chuhao Zhou, Yuxi Liu, Gen Li, Jindou Jia, Jianfei Yang
分类: cs.RO
发布日期: 2026-02-07
💡 一句话要点
提出Trace-Focused Diffusion Policy,解决长时程机器人操作中的多模态动作歧义问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 长时程任务 多模态动作歧义 扩散策略 执行轨迹
📋 核心要点
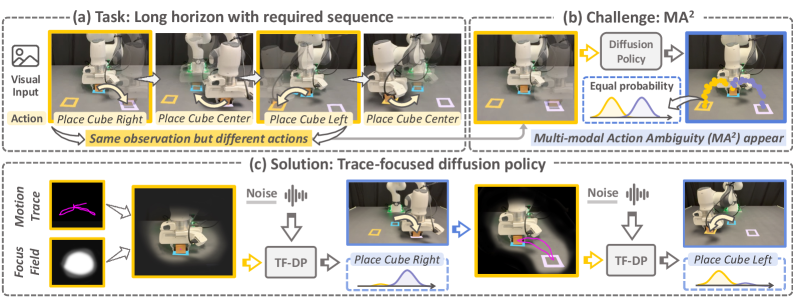
- 长时程机器人操作任务中,相似视觉观测需不同动作,导致多模态动作歧义,现有方法难以有效区分。
- TF-DP通过显式地将历史运动轨迹投影到视觉空间,为当前动作生成提供阶段感知的上下文信息。
- 实验表明,TF-DP在多模态动作歧义和视觉干扰下,显著提升了策略的鲁棒性和时间一致性。
📝 摘要(中文)
基于生成模型的策略在模仿学习的机器人操作中表现出色,通过从演示中学习动作分布。然而,在长时程任务中,视觉上相似的观测可能在执行阶段重复出现,但需要不同的动作,当策略仅以瞬时观测为条件时,会导致模糊的预测,即多模态动作歧义(MA2)。为了解决这个挑战,我们提出了Trace-Focused Diffusion Policy(TF-DP),一个简单而有效的基于扩散的框架,它显式地将动作生成建立在机器人的执行历史之上。TF-DP将历史运动表示为显式的执行轨迹,并将其投影到视觉观测空间中,当仅凭当前观测不足时,提供阶段感知的上下文。此外,所产生的以轨迹为中心的场强调与历史运动相关的任务相关区域,从而提高对背景视觉干扰的鲁棒性。我们在具有明显多模态动作歧义和视觉杂乱条件下的真实机器人操作任务中评估了TF-DP。实验结果表明,TF-DP提高了时间一致性和鲁棒性,在具有多模态动作歧义的任务中优于原始扩散策略80.56%,在视觉干扰下优于86.11%,同时保持了推理效率,运行时间仅增加了6.4%。这些结果表明,执行轨迹条件化为在单个策略中实现鲁棒的长时程机器人操作提供了一种可扩展且有原则的方法。
🔬 方法详解
问题定义:论文旨在解决长时程机器人操作任务中,由于视觉相似的观测在不同阶段需要执行不同动作而导致的多模态动作歧义(MA2)问题。现有方法通常只依赖于瞬时观测,无法有效区分这些歧义情况,导致策略性能下降。
核心思路:论文的核心思路是将机器人的执行历史作为显式的执行轨迹,并将其投影到视觉观测空间中,从而为当前动作的生成提供阶段感知的上下文信息。通过这种方式,策略可以区分视觉上相似但语义不同的状态,从而解决多模态动作歧义问题。
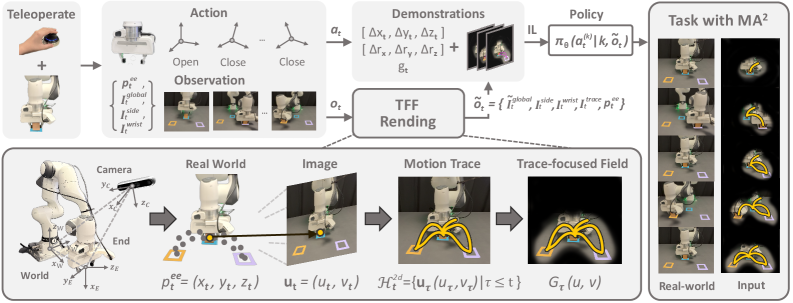
技术框架:TF-DP的整体框架包括以下几个主要模块:1) 历史运动轨迹编码器:将历史动作序列编码为执行轨迹。2) 轨迹投影模块:将执行轨迹投影到视觉观测空间,生成轨迹聚焦场。3) 扩散策略网络:以当前视觉观测和轨迹聚焦场为条件,生成动作分布。整个流程是,首先利用历史动作信息构建轨迹,然后将轨迹信息融入到当前观测中,最后利用扩散模型生成动作。
关键创新:TF-DP的关键创新在于显式地利用执行轨迹作为上下文信息,并将其投影到视觉空间中,从而为策略提供阶段感知的上下文。与现有方法相比,TF-DP不需要额外的模态信息或者复杂的注意力机制,而是通过一种简单而有效的方式来解决多模态动作歧义问题。
关键设计:论文中一个关键的设计是轨迹聚焦场的生成方式。具体来说,论文首先将历史动作序列编码为执行轨迹,然后将执行轨迹投影到视觉观测空间中,生成一个与历史运动相关的任务相关区域的注意力图。这个注意力图可以帮助策略关注与历史运动相关的关键区域,从而提高对背景视觉干扰的鲁棒性。损失函数方面,采用标准的扩散模型训练目标,优化动作生成的概率分布。
🖼️ 关键图片
📊 实验亮点
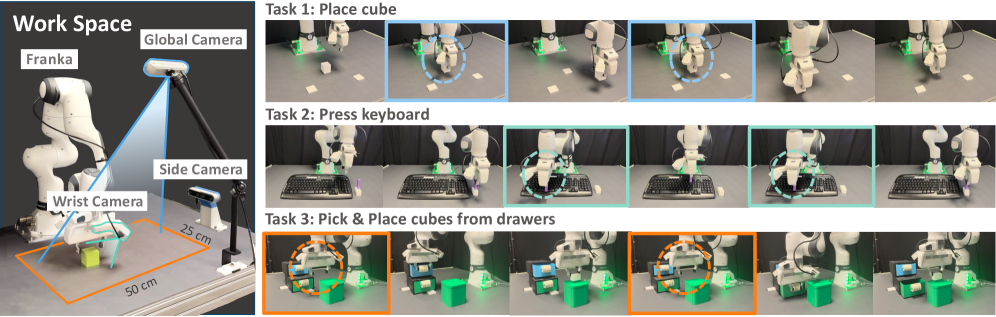
实验结果表明,TF-DP在具有多模态动作歧义的任务中,性能优于原始扩散策略80.56%,在视觉干扰下优于86.11%。同时,TF-DP保持了较高的推理效率,运行时间仅增加了6.4%。这些结果验证了TF-DP在解决长时程机器人操作中的多模态动作歧义问题方面的有效性。
🎯 应用场景
TF-DP适用于各种需要长时程规划和操作的机器人任务,例如装配、烹饪、导航等。该方法可以提高机器人在复杂环境中的鲁棒性和可靠性,降低对环境感知的要求,并有望应用于智能制造、家庭服务等领域,实现更智能、更自主的机器人系统。
📄 摘要(原文)
Generative model-based policies have shown strong performance in imitation-based robotic manipulation by learning action distributions from demonstrations. However, in long-horizon tasks, visually similar observations often recur across execution stages while requiring distinct actions, which leads to ambiguous predictions when policies are conditioned only on instantaneous observations, termed multi-modal action ambiguity (MA2). To address this challenge, we propose the Trace-Focused Diffusion Policy (TF-DP), a simple yet effective diffusion-based framework that explicitly conditions action generation on the robot's execution history. TF-DP represents historical motion as an explicit execution trace and projects it into the visual observation space, providing stage-aware context when current observations alone are insufficient. In addition, the induced trace-focused field emphasizes task-relevant regions associated with historical motion, improving robustness to background visual disturbances. We evaluate TF-DP on real-world robotic manipulation tasks exhibiting pronounced multi-modal action ambiguity and visually cluttered conditions. Experimental results show that TF-DP improves temporal consistency and robustness, outperforming the vanilla diffusion policy by 80.56 percent on tasks with multi-modal action ambiguity and by 86.11 percent under visual disturbances, while maintaining inference efficiency with only a 6.4 percent runtime increase. These results demonstrate that execution-trace conditioning offers a scalable and principled approach for robust long-horizon robotic manipulation within a single policy.