Action-to-Action Flow Matching
作者: Jindou Jia, Gen Li, Xiangyu Chen, Tuo An, Yuxuan Hu, Jingliang Li, Xinying Guo, Jianfei Yang
分类: cs.RO, cs.AI
发布日期: 2026-02-07
备注: 18 pages, 18 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Action-to-Action Flow Matching,加速扩散模型在机器人动作生成中的应用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人控制 扩散模型 动作生成 Flow Matching 时间序列建模
📋 核心要点
- 基于扩散模型的机器人策略通常需要多步迭代去噪,导致推理延迟高,限制了实时控制的应用。
- A2A利用历史动作序列信息初始化扩散过程,避免了从随机噪声开始的迭代去噪,从而加速推理。
- 实验证明A2A在训练效率、推理速度和泛化能力方面均有提升,并可扩展到视频生成任务。
📝 摘要(中文)
本文提出了一种新的策略范式Action-to-Action flow matching (A2A),旨在解决基于扩散模型的策略在机器人控制中推理延迟高的问题。与从随机高斯噪声中采样不同,A2A利用先前的动作信息来初始化动作生成过程。A2A将历史本体感受序列嵌入到高维潜在空间中,以此作为动作生成的起点。这种设计绕过了代价高昂的迭代去噪过程,同时有效地捕捉了机器人的物理动力学和时间连续性。实验表明,A2A具有较高的训练效率、快速的推理速度和更好的泛化能力。A2A仅需单步推理(0.56毫秒延迟)即可生成高质量的动作,并且对视觉扰动表现出优异的鲁棒性,并增强了对未见配置的泛化能力。此外,A2A还可扩展到视频生成,展示了其在时间建模方面的广泛适用性。
🔬 方法详解
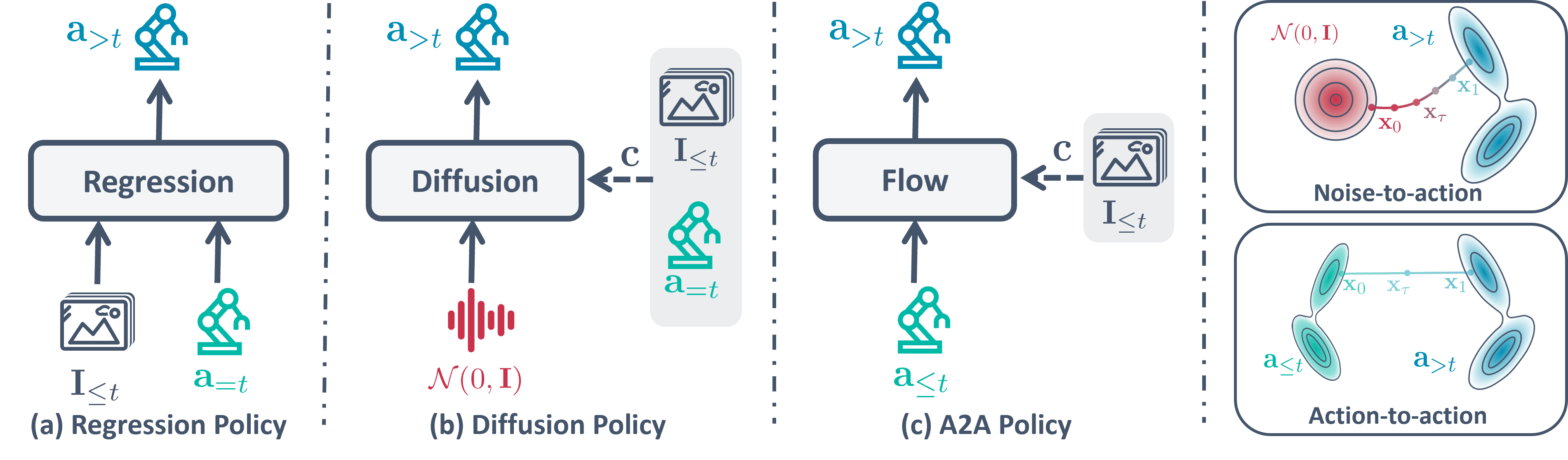
问题定义:基于扩散模型的机器人策略通过条件去噪过程预测动作。然而,从随机高斯噪声采样需要多次迭代才能生成干净的动作,导致推理延迟高,成为实时控制的瓶颈。现有方法通常将本体感受动作反馈视为静态条件,忽略了其时序信息。
核心思路:A2A的核心在于利用历史本体感受序列作为动作生成的起点,而非随机噪声。通过将历史动作嵌入到高维潜在空间,为扩散过程提供了一个信息丰富的初始化状态,从而减少了迭代去噪的步骤。
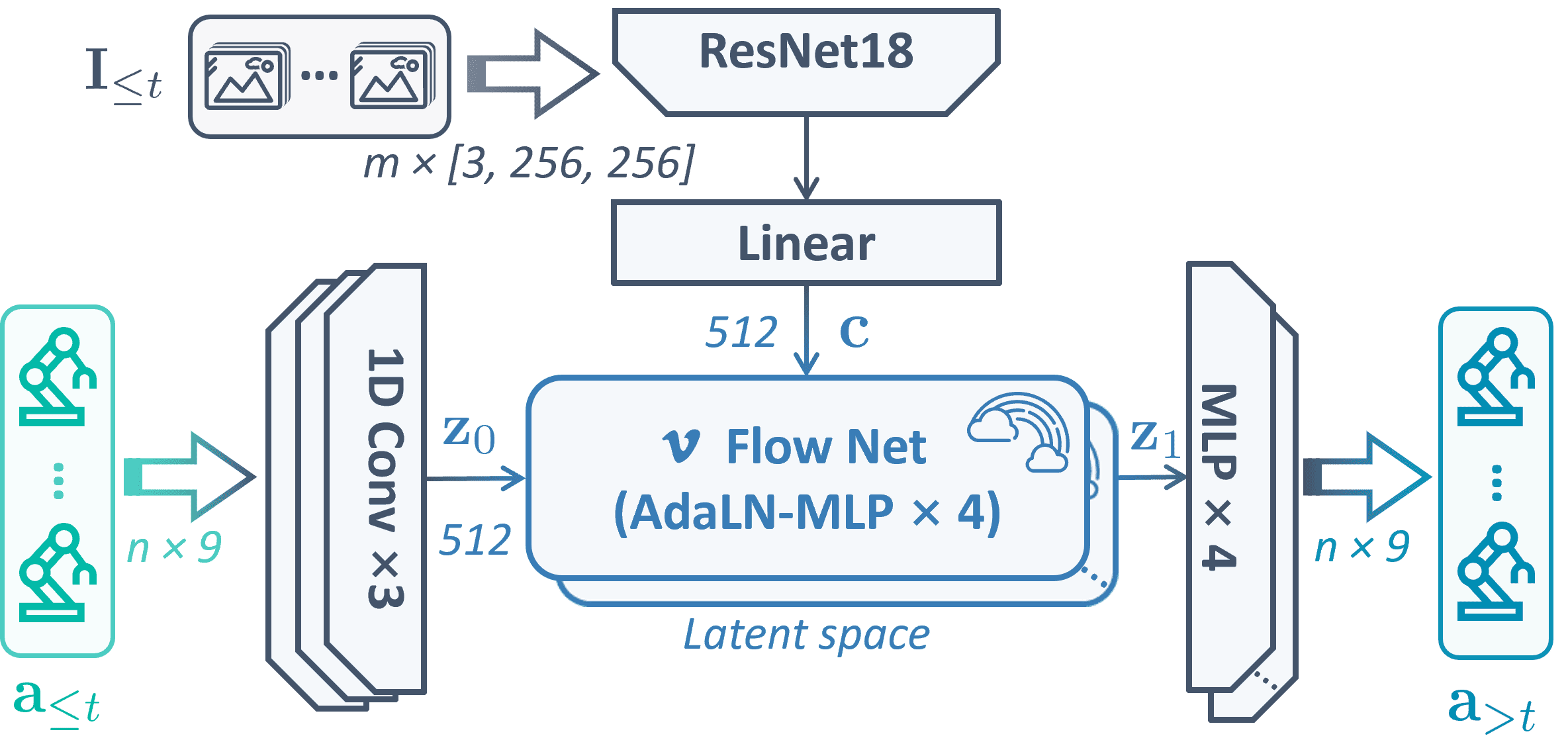
技术框架:A2A包含一个嵌入模块,用于将历史本体感受序列映射到潜在空间。然后,该潜在表示作为条件输入到扩散模型中,引导模型生成下一步的动作。整个流程避免了从随机噪声开始的采样,直接从一个与当前状态相关的潜在表示出发。
关键创新:A2A的关键创新在于将历史动作信息融入到扩散模型的初始化阶段,从而绕过了耗时的迭代去噪过程。与现有方法将本体感受信息作为静态条件不同,A2A充分利用了动作的时序信息,提高了动作生成的效率和质量。
关键设计:A2A使用Flow Matching作为扩散模型的训练目标,旨在学习一个向量场,将初始状态(历史动作嵌入)平滑地变换到目标状态(未来动作)。具体的网络结构和损失函数设计旨在最小化预测动作与真实动作之间的差异,并保证潜在空间的平滑性。
🖼️ 关键图片

📊 实验亮点
A2A在机器人控制任务中表现出显著的优势,仅需单步推理即可生成高质量的动作,推理延迟仅为0.56毫秒。实验表明,A2A对视觉扰动具有更强的鲁棒性,并且能够更好地泛化到未见过的配置。此外,A2A在视频生成任务中也取得了有竞争力的结果,证明了其在时间建模方面的通用性。
🎯 应用场景
A2A具有广泛的应用前景,包括机器人控制、自动化装配、智能驾驶等领域。其快速的推理速度和良好的泛化能力使其能够应用于实时性要求高的场景。此外,A2A在视频生成方面的潜力也使其能够应用于内容创作、视频编辑等领域,为时间序列建模提供了一种新的思路。
📄 摘要(原文)
Diffusion-based policies have recently achieved remarkable success in robotics by formulating action prediction as a conditional denoising process. However, the standard practice of sampling from random Gaussian noise often requires multiple iterative steps to produce clean actions, leading to high inference latency that incurs a major bottleneck for real-time control. In this paper, we challenge the necessity of uninformed noise sampling and propose Action-to-Action flow matching (A2A), a novel policy paradigm that shifts from random sampling to initialization informed by the previous action. Unlike existing methods that treat proprioceptive action feedback as static conditions, A2A leverages historical proprioceptive sequences, embedding them into a high-dimensional latent space as the starting point for action generation. This design bypasses costly iterative denoising while effectively capturing the robot's physical dynamics and temporal continuity. Extensive experiments demonstrate that A2A exhibits high training efficiency, fast inference speed, and improved generalization. Notably, A2A enables high-quality action generation in as few as a single inference step (0.56 ms latency), and exhibits superior robustness to visual perturbations and enhanced generalization to unseen configurations. Lastly, we also extend A2A to video generation, demonstrating its broader versatility in temporal modeling. Project site: https://lorenzo-0-0.github.io/A2A_Flow_Matching.