DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos
作者: Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Yuqi Xie, Ruijie Zheng, Dantong Niu, You Liang Tan, K. R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter Abbeel, Ming-Yu Liu, Yuke Zhu, Joel Jang, Linxi "Jim" Fan
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2026-02-06
备注: Project page: https://dreamdojo-world.github.io/
💡 一句话要点
DreamDojo:基于大规模人类视频的通用机器人世界模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人世界模型 大规模视频数据 连续潜在动作 模型预训练 模型蒸馏
📋 核心要点
- 现有机器人世界模型面临数据覆盖范围有限和动作标签稀缺的挑战,尤其是在灵巧操作任务中。
- DreamDojo利用大规模人类视频数据进行预训练,并引入连续潜在动作作为统一的代理动作,以解决动作标签稀疏问题。
- DreamDojo在后训练后表现出强大的物理理解和动作控制能力,并通过蒸馏加速到实时,支持多种应用。
📝 摘要(中文)
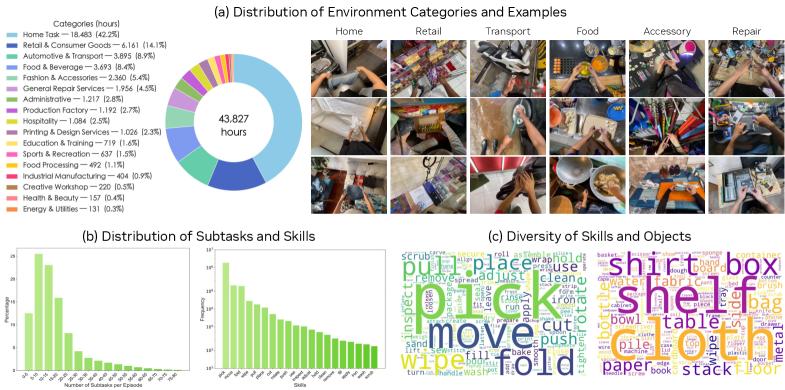
本文提出了DreamDojo,一个基础世界模型,它从4.4万小时的以自我为中心的人类视频中学习多样化的交互和灵巧的控制。该数据集是迄今为止用于世界模型预训练的最大视频数据集,涵盖了各种日常场景以及不同的对象和技能。为了解决动作标签稀缺的问题,引入了连续潜在动作作为统一的代理动作,从而增强了从无标签视频中迁移交互知识的能力。在小规模目标机器人数据上进行后训练后,DreamDojo展示了对物理学的深刻理解和精确的动作可控性。此外,还设计了一种蒸馏流程,将DreamDojo加速到10.81 FPS的实时速度,并进一步提高了上下文一致性。该工作支持基于生成世界模型的多种重要应用,包括实时远程操作、策略评估和基于模型的规划。在多个具有挑战性的分布外(OOD)基准上的系统评估验证了该方法在模拟开放世界、富接触任务中的重要性,为通用机器人世界模型铺平了道路。
🔬 方法详解
问题定义:现有机器人世界模型在模拟复杂环境中的动作结果时面临挑战,特别是对于需要灵巧操作的任务。主要痛点在于数据覆盖范围不足,以及缺乏精确的动作标签,导致模型难以学习到泛化性强的交互知识。
核心思路:DreamDojo的核心思路是利用大规模的人类第一视角视频数据作为预训练的知识来源。人类视频包含了丰富的日常交互场景和技能,可以为机器人世界模型提供宝贵的先验知识。通过学习人类如何与环境互动,模型能够更好地理解物理规律和动作的潜在语义。
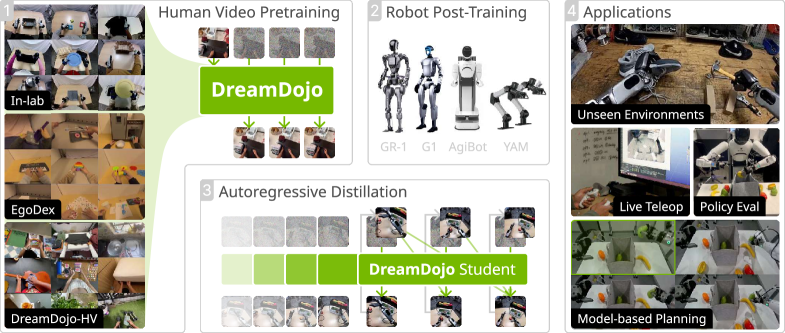
技术框架:DreamDojo的整体框架包括以下几个主要阶段:1) 大规模人类视频数据收集与处理;2) 基于Transformer的视频预测模型训练,该模型以连续潜在动作作为输入;3) 在目标机器人任务数据上进行后训练,以适应特定机器人平台的运动学和动力学特性;4) 模型蒸馏,将模型加速到实时性能。
关键创新:DreamDojo的关键创新在于利用连续潜在动作作为统一的代理动作,从而解决了动作标签稀缺的问题。通过学习将视频帧映射到潜在动作空间,模型可以从无标签视频中学习交互知识,并将其迁移到机器人控制任务中。此外,大规模人类视频数据的应用也是一个重要的创新点。
关键设计:DreamDojo使用了基于Transformer的视频预测模型,该模型能够捕捉视频中的长期依赖关系。连续潜在动作通过变分自编码器(VAE)学习得到。损失函数包括视频重构损失、潜在动作的正则化损失以及对抗损失,以提高生成视频的真实感。模型蒸馏采用知识蒸馏技术,将大型模型的知识迁移到小型模型,从而实现实时性能。
🖼️ 关键图片

📊 实验亮点
DreamDojo在多个具有挑战性的分布外(OOD)基准测试中表现出色,验证了其在模拟开放世界、富接触任务中的有效性。通过蒸馏,DreamDojo实现了10.81 FPS的实时推理速度,并提高了上下文一致性。这些结果表明,DreamDojo为构建通用机器人世界模型奠定了坚实的基础。
🎯 应用场景
DreamDojo具有广泛的应用前景,包括实时远程操作、策略评估和基于模型的规划。它可以用于训练机器人在各种复杂环境中执行任务,例如家庭服务、工业自动化和医疗保健。通过模拟真实世界的交互,DreamDojo可以加速机器人学习和开发过程,并提高机器人的自主性和适应性。
📄 摘要(原文)
Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels. As an endeavor towards this end, we introduce DreamDojo, a foundation world model that learns diverse interactions and dexterous controls from 44k hours of egocentric human videos. Our data mixture represents the largest video dataset to date for world model pretraining, spanning a wide range of daily scenarios with diverse objects and skills. To address the scarcity of action labels, we introduce continuous latent actions as unified proxy actions, enhancing interaction knowledge transfer from unlabeled videos. After post-training on small-scale target robot data, DreamDojo demonstrates a strong understanding of physics and precise action controllability. We also devise a distillation pipeline that accelerates DreamDojo to a real-time speed of 10.81 FPS and further improves context consistency. Our work enables several important applications based on generative world models, including live teleoperation, policy evaluation, and model-based planning. Systematic evaluation on multiple challenging out-of-distribution (OOD) benchmarks verifies the significance of our method for simulating open-world, contact-rich tasks, paving the way for general-purpose robot world models.