Force Generative Imitation Learning: Bridging Position Trajectory and Force Commands through Control Technique
作者: Hiroshi Sato, Sho Sakaino, Toshiaki Tsuji
分类: cs.RO, eess.SY
发布日期: 2026-02-06
备注: Accepted for IEEE Access
DOI: 10.1109/ACCESS.2026.3662516
💡 一句话要点
提出基于反馈控制的力生成模仿学习,解决接触任务中力指令生成难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 力生成 模仿学习 反馈控制 机器人控制 接触任务
📋 核心要点
- 接触任务中,获取精确力指令困难,现有VLA模型因硬件差异难以直接应用。
- 提出力生成模仿学习模型,从位置轨迹预测力指令,并引入反馈控制提升泛化性。
- 实验表明,无记忆的力生成模型结合反馈控制,能有效处理未见轨迹,提升书写任务性能。
📝 摘要(中文)
在富含接触的任务中,位置轨迹通常容易获得,但合适的力指令通常是未知的。虽然可以使用预训练的基础模型(如视觉-语言-动作(VLA)模型)生成力指令,但力控制高度依赖于机器人的特定硬件,这使得此类模型的应用具有挑战性。为了弥合这一差距,我们提出了一种力生成模型,该模型从给定的位置轨迹估计力指令。然而,当处理未见过的位置轨迹时,该模型难以生成准确的力指令。为了解决这个问题,我们引入了一种反馈控制机制。我们的实验表明,当力生成模型具有记忆时,反馈控制不会收敛。因此,我们采用了一个没有记忆的模型,从而实现稳定的反馈控制。这种方法允许系统有效地生成力指令,即使对于未见过的位置轨迹,从而提高真实世界机器人书写任务的泛化能力。
🔬 方法详解
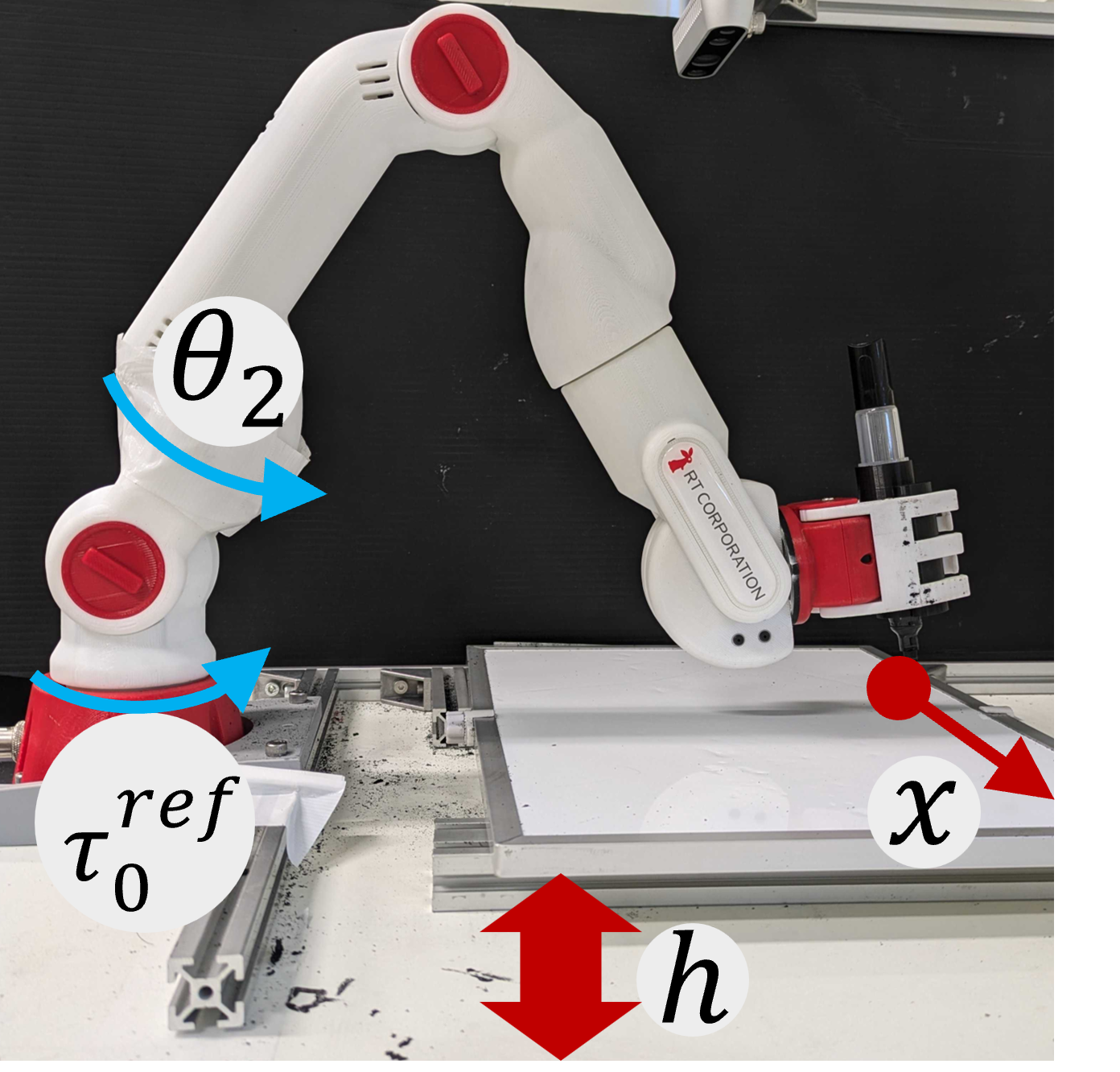
问题定义:论文旨在解决接触任务中,机器人难以从位置轨迹生成合适的力指令的问题。现有方法,如直接使用视觉-语言-动作模型,由于机器人硬件差异大,力控制的精确性难以保证,泛化能力不足。因此,需要一种方法能够根据位置轨迹,生成适应特定机器人硬件的力指令。
核心思路:论文的核心思路是利用模仿学习,训练一个力生成模型,该模型能够从位置轨迹预测力指令。为了提高模型对未见轨迹的泛化能力,引入了反馈控制机制,通过实时调整力指令,弥补模型预测的误差。
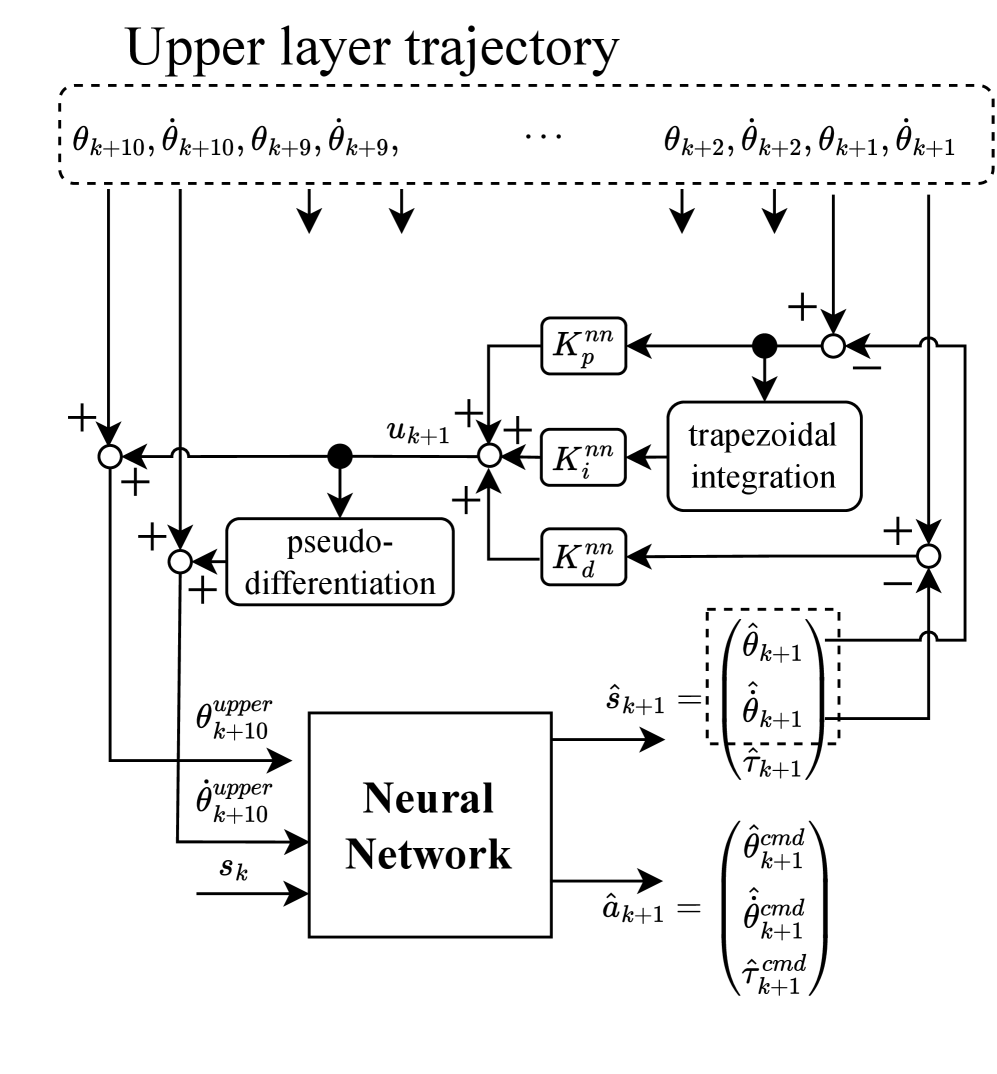
技术框架:整体框架包含两个主要部分:力生成模型和反馈控制器。力生成模型接收位置轨迹作为输入,输出力指令的预测值。反馈控制器接收期望力指令和实际力反馈作为输入,计算误差并调整力指令,最终控制机器人执行任务。整个系统通过迭代优化,使得机器人能够根据给定的位置轨迹,精确地执行接触任务。
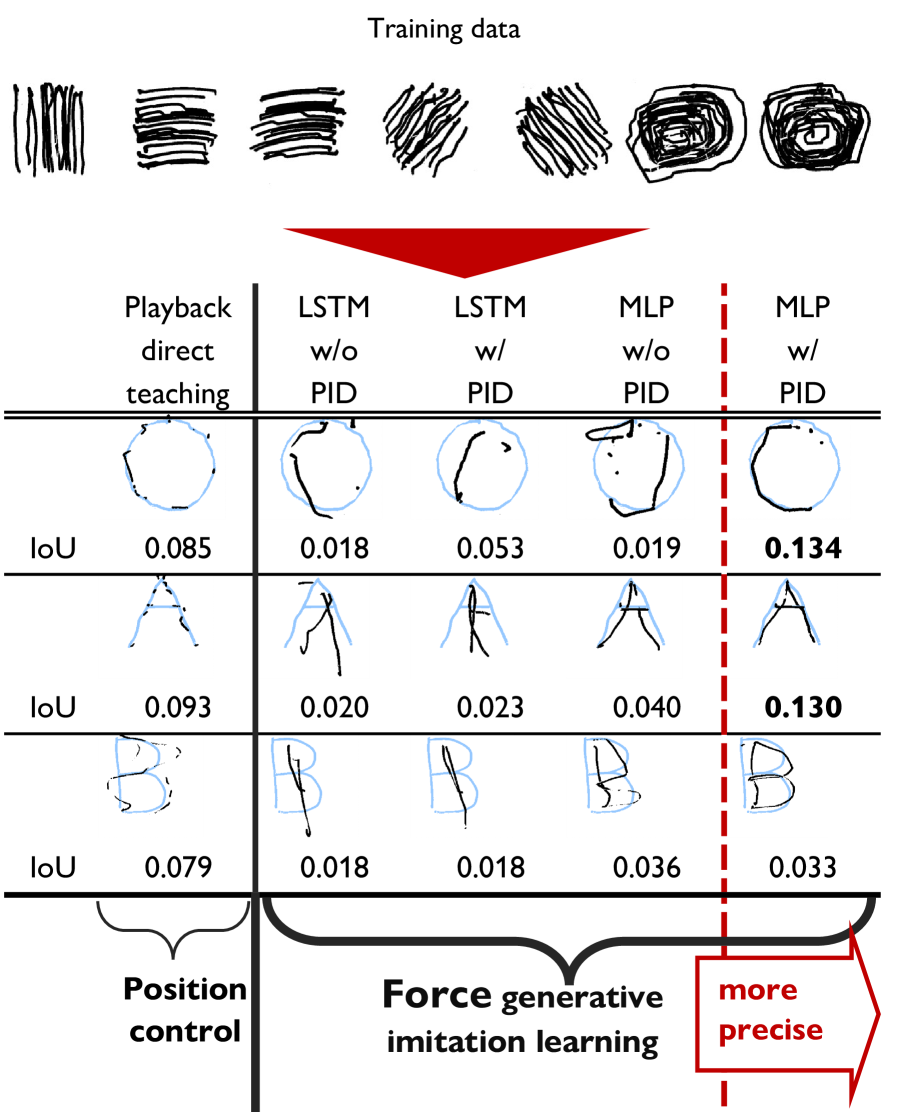
关键创新:论文的关键创新在于将力生成模型与反馈控制相结合,解决了力控制对硬件依赖性强的问题。通过模仿学习,力生成模型学习了位置轨迹与力指令之间的关系,而反馈控制则弥补了模型预测的误差,提高了系统的鲁棒性和泛化能力。此外,论文还发现,具有记忆的力生成模型会导致反馈控制的不稳定,因此采用了无记忆的模型。
关键设计:力生成模型采用无记忆的神经网络结构,例如多层感知机(MLP),以保证反馈控制的稳定性。反馈控制器采用经典的PID控制算法,根据力误差调整力指令。损失函数包括力误差和位置误差,通过最小化这些误差,优化力生成模型的参数和PID控制器的参数。具体的参数设置,如学习率、PID参数等,需要根据具体的机器人硬件和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的力生成模仿学习方法结合反馈控制,能够有效地处理未见过的位置轨迹,并在真实机器人书写任务中取得了良好的泛化性能。与没有反馈控制的基线方法相比,该方法显著提高了书写精度和稳定性。此外,实验还验证了无记忆的力生成模型对于反馈控制稳定性的重要性。
🎯 应用场景
该研究成果可应用于各种需要精确力控制的机器人任务,如机器人打磨、装配、书写等。通过学习人类示教的位置轨迹,机器人可以自动生成合适的力指令,完成复杂的接触任务。该方法还可以应用于医疗机器人领域,例如手术机器人,提高手术的精确性和安全性。未来,该方法有望推广到更广泛的机器人应用场景,实现更智能、更灵活的机器人控制。
📄 摘要(原文)
In contact-rich tasks, while position trajectories are often easy to obtain, appropriate force commands are typically unknown. Although it is conceivable to generate force commands using a pretrained foundation model such as Vision-Language-Action (VLA) models, force control is highly dependent on the specific hardware of the robot, which makes the application of such models challenging. To bridge this gap, we propose a force generative model that estimates force commands from given position trajectories. However, when dealing with unseen position trajectories, the model struggles to generate accurate force commands. To address this, we introduce a feedback control mechanism. Our experiments reveal that feedback control does not converge when the force generative model has memory. We therefore adopt a model without memory, enabling stable feedback control. This approach allows the system to generate force commands effectively, even for unseen position trajectories, improving generalization for real-world robot writing tasks.