Think Proprioceptively: Embodied Visual Reasoning for VLA Manipulation
作者: Fangyuan Wang, Peng Zhou, Jiaming Qi, Shipeng Lyu, David Navarro-Alarcon, Guodong Guo
分类: cs.RO, cs.CV
发布日期: 2026-02-06
💡 一句话要点
ThinkProprio:通过具身视觉推理提升VLA模型操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉语言动作模型 机器人操作 本体感受 文本token化
📋 核心要点
- 现有VLA模型对本体感受利用不足,导致机器人状态难以有效影响指令理解和视觉信息处理。
- ThinkProprio将本体感受转化为文本token,与指令早期融合,引导视觉推理关注动作相关的关键信息。
- 实验表明,ThinkProprio在多个数据集上超越基线,并显著降低了推理延迟,提升了操作效率。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通常仅将本体感受作为后期条件信号注入,这阻碍了机器人状态影响指令理解和视觉token的注意力选择。我们提出了ThinkProprio,它将本体感受转换为VLM嵌入空间中的文本token序列,并在输入端将其与任务指令融合。这种早期融合使具身状态能够参与后续的视觉推理和token选择,从而将计算偏向于对动作至关重要的证据,同时抑制冗余的视觉token。通过对本体感受编码、状态入口点和动作头条件反射的系统性消融研究,我们发现文本token化比学习到的投影更有效,并且保留大约15%的视觉token可以匹配使用完整token集的性能。在CALVIN、LIBERO和真实世界操作中,ThinkProprio匹配或优于强大的基线,同时将端到端推理延迟降低了50%以上。
🔬 方法详解
问题定义:现有VLA模型在处理机器人操作任务时,通常将本体感受信息作为后期条件信号输入,这导致模型无法充分利用机器人自身的状态信息来指导指令理解和视觉推理。这种滞后的信息融合方式限制了模型对环境变化的适应能力,降低了操作的准确性和效率。现有方法的痛点在于本体感受信息利用率低,无法有效指导视觉token的选择和处理。
核心思路:ThinkProprio的核心思路是将本体感受信息转化为文本token,并在视觉语言模型的早期阶段将其与任务指令融合。通过这种方式,机器人状态信息可以更早地参与到视觉推理过程中,引导模型关注与动作相关的关键视觉信息,抑制冗余信息,从而提高操作的准确性和效率。这种早期融合的设计使得模型能够更好地理解任务指令,并根据自身状态做出更合理的决策。
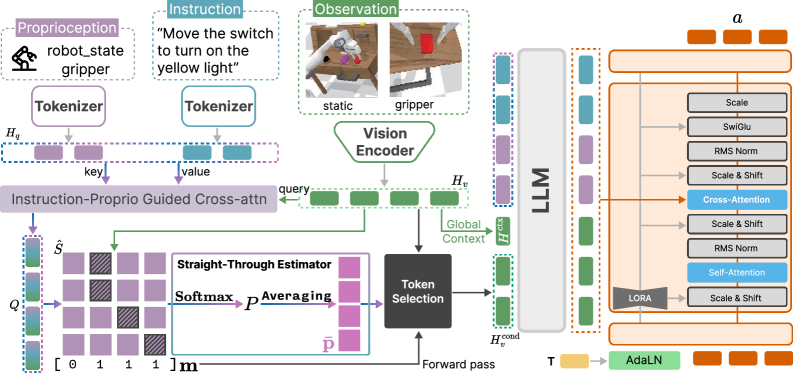
技术框架:ThinkProprio的整体框架包括以下几个主要模块:1) 本体感受编码模块:将机器人状态信息(如关节角度、末端执行器位置等)转化为文本token序列。2) 指令融合模块:将本体感受token序列与任务指令进行融合,形成统一的输入表示。3) 视觉语言模型:使用融合后的输入表示进行视觉推理和动作预测。4) 动作执行模块:根据模型预测的动作执行相应的操作。
关键创新:ThinkProprio最重要的技术创新点在于本体感受信息的文本token化和早期融合。与传统的后期条件反射方法相比,这种方法能够更有效地利用机器人状态信息来指导视觉推理和动作预测。此外,通过选择性地保留关键视觉token,可以进一步提高模型的效率和准确性。
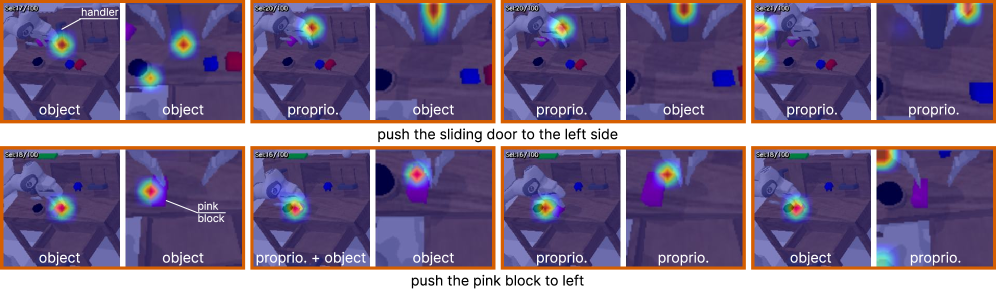
关键设计:在本体感受编码方面,论文比较了文本token化和学习到的投影两种方法,发现文本token化更有效。在状态入口点方面,论文研究了不同的融合位置,发现早期融合效果更好。在视觉token选择方面,论文发现保留大约15%的关键视觉token可以匹配使用完整token集的性能。损失函数方面,使用了标准的交叉熵损失函数来训练模型。网络结构方面,使用了基于Transformer的视觉语言模型。
🖼️ 关键图片

📊 实验亮点
ThinkProprio在CALVIN、LIBERO和真实世界操作等多个数据集上取得了显著的性能提升。实验结果表明,ThinkProprio能够匹配或优于强大的基线模型,同时将端到端推理延迟降低了50%以上。此外,消融实验表明,文本token化比学习到的投影更有效,并且保留大约15%的视觉token可以匹配使用完整token集的性能。
🎯 应用场景
ThinkProprio具有广泛的应用前景,可应用于各种机器人操作任务,例如:工业自动化、家庭服务机器人、医疗机器人等。通过提高机器人操作的准确性和效率,可以降低生产成本,提高服务质量,并为人类提供更便捷的生活体验。该研究的成果也有助于推动具身智能和人机协作的发展。
📄 摘要(原文)
Vision-language-action (VLA) models typically inject proprioception only as a late conditioning signal, which prevents robot state from shaping instruction understanding and from influencing which visual tokens are attended throughout the policy. We introduce ThinkProprio, which converts proprioception into a sequence of text tokens in the VLM embedding space and fuses them with the task instruction at the input. This early fusion lets embodied state participate in subsequent visual reasoning and token selection, biasing computation toward action-critical evidence while suppressing redundant visual tokens. In a systematic ablation over proprioception encoding, state entry point, and action-head conditioning, we find that text tokenization is more effective than learned projectors, and that retaining roughly 15% of visual tokens can match the performance of using the full token set. Across CALVIN, LIBERO, and real-world manipulation, ThinkProprio matches or improves over strong baselines while reducing end-to-end inference latency over 50%.