World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
作者: Xiaokang Liu, Zechen Bai, Hai Ci, Kevin Yuchen Ma, Mike Zheng Shou
分类: cs.RO
发布日期: 2026-02-06
备注: 14 pages, 8 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出World-VLA-Loop,用于视频世界模型和VLA策略的闭环学习,提升机器人操作性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 视觉-语言-动作策略 闭环学习 强化学习 机器人操作 视频扩散模型 状态感知 SANS数据集
📋 核心要点
- 现有基于视频扩散Transformer的世界模型在模拟真实视觉效果方面表现出色,但在动作执行精度方面存在不足,限制了其在机器人学习中的应用。
- World-VLA-Loop框架通过闭环方式联合优化世界模型和VLA策略,利用状态感知的视频世界模型和SANS数据集来提升动作执行的可靠性。
- 该框架在模拟和真实世界任务中验证了其有效性,能够以较少的物理交互显著提升VLA策略的性能,实现世界建模和策略学习的互利共赢。
📝 摘要(中文)
本文提出World-VLA-Loop,一个用于联合优化世界模型和视觉-语言-动作(VLA)策略的闭环框架。该框架利用状态感知的视频世界模型,通过联合预测未来观测和奖励信号,作为一个高保真的交互式模拟器。为了提高可靠性,引入了SANS数据集,该数据集包含近成功轨迹,以改善世界模型中的动作-结果对齐。该框架支持完全在虚拟环境中对VLA策略进行强化学习(RL)后训练的闭环。至关重要的是,该方法促进了一个共同进化的循环:VLA策略产生的失败轨迹被迭代地反馈以改进世界模型的精度,进而增强后续的RL优化。在模拟和真实世界任务中的评估表明,该框架以最小的物理交互显著提高了VLA性能,从而在世界建模和策略学习之间建立了互利的通用机器人关系。
🔬 方法详解
问题定义:现有基于视频扩散Transformer的世界模型虽然能够生成逼真的视觉预测,但在机器人控制任务中,其动作执行的精确性往往不足。这导致策略学习难以在这些世界模型中有效地进行,限制了其在实际机器人应用中的价值。现有方法难以保证动作与结果的精确对齐,从而影响了策略学习的可靠性。
核心思路:World-VLA-Loop的核心思路是通过闭环反馈机制,迭代地优化世界模型和VLA策略。VLA策略在世界模型中进行训练,产生的失败轨迹被用于改进世界模型,使其能够更准确地预测动作的结果。改进后的世界模型反过来又可以提升VLA策略的训练效果,形成一个正向循环。这种共同进化的方式能够逐步提高世界模型的精度和VLA策略的性能。
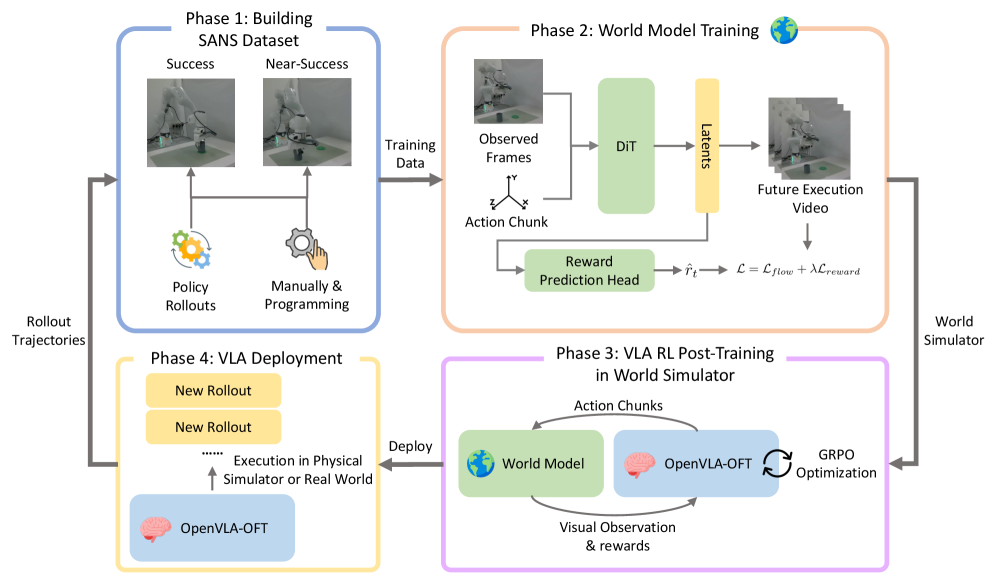
技术框架:World-VLA-Loop框架包含三个主要组成部分:状态感知的视频世界模型、VLA策略以及闭环反馈机制。首先,状态感知的视频世界模型负责预测给定当前状态和动作序列的未来观测和奖励信号。其次,VLA策略根据当前观测选择动作,并在世界模型中执行。最后,闭环反馈机制收集VLA策略在世界模型中产生的轨迹,特别是失败轨迹,并将其用于重新训练世界模型。
关键创新:该论文的关键创新在于提出了一个闭环的训练框架,能够联合优化世界模型和VLA策略。与传统的单向训练方式不同,World-VLA-Loop通过反馈机制实现了世界模型和策略学习的共同进化。此外,SANS数据集的引入也提高了世界模型中动作-结果对齐的可靠性。
关键设计:状态感知的视频世界模型采用视频扩散Transformer架构,能够生成高分辨率的视觉预测。SANS数据集包含近成功轨迹,能够提供更丰富的动作-结果对齐信息。闭环反馈机制采用迭代的方式,逐步提高世界模型的精度和VLA策略的性能。具体的损失函数和网络结构等技术细节在论文中有详细描述,但此处未提供具体参数。
🖼️ 关键图片

📊 实验亮点
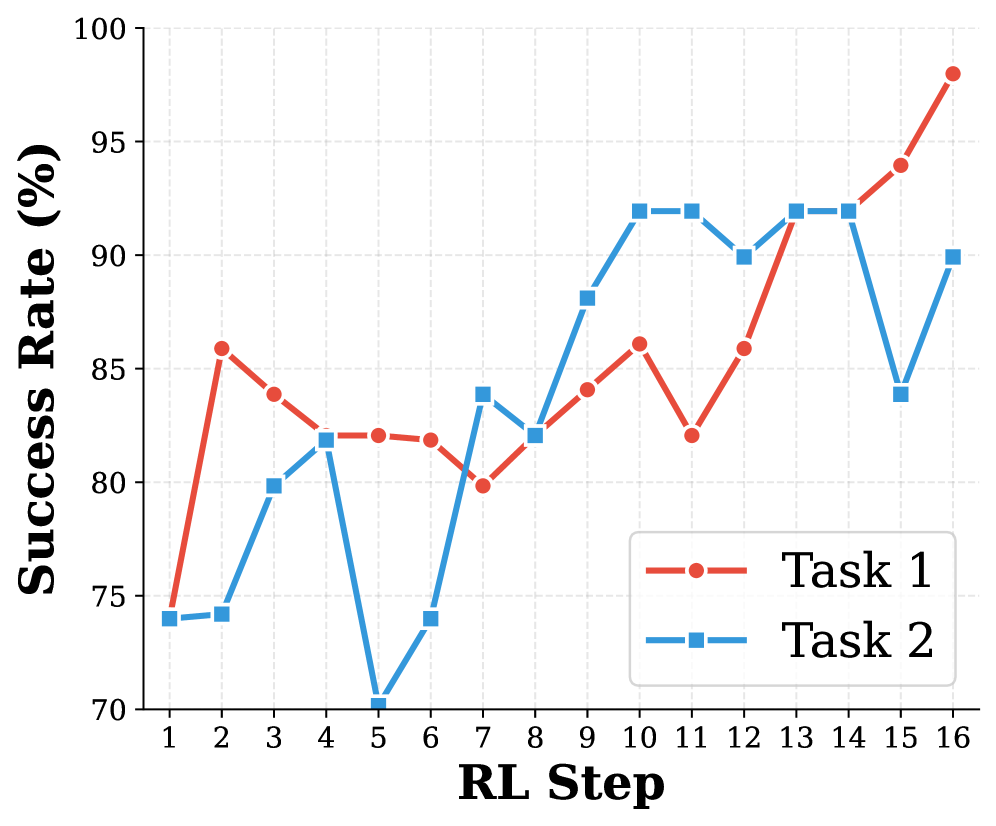
实验结果表明,World-VLA-Loop框架能够显著提升VLA策略的性能。在模拟环境中,该方法在多个机器人操作任务上取得了优于现有方法的性能。在真实世界实验中,该方法也展现出了良好的泛化能力,能够以较少的物理交互实现有效的策略学习。具体性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过在虚拟环境中进行策略学习,可以显著减少机器人与真实环境的交互次数,降低训练成本和风险。该方法有望推动通用机器人技术的发展,使其能够更灵活、高效地完成各种复杂任务。
📄 摘要(原文)
Recent progress in robotic world models has leveraged video diffusion transformers to predict future observations conditioned on historical states and actions. While these models can simulate realistic visual outcomes, they often exhibit poor action-following precision, hindering their utility for downstream robotic learning. In this work, we introduce World-VLA-Loop, a closed-loop framework for the joint refinement of world models and Vision-Language-Action (VLA) policies. We propose a state-aware video world model that functions as a high-fidelity interactive simulator by jointly predicting future observations and reward signals. To enhance reliability, we introduce the SANS dataset, which incorporates near-success trajectories to improve action-outcome alignment within the world model. This framework enables a closed-loop for reinforcement learning (RL) post-training of VLA policies entirely within a virtual environment. Crucially, our approach facilitates a co-evolving cycle: failure rollouts generated by the VLA policy are iteratively fed back to refine the world model precision, which in turn enhances subsequent RL optimization. Evaluations across simulation and real-world tasks demonstrate that our framework significantly boosts VLA performance with minimal physical interaction, establishing a mutually beneficial relationship between world modeling and policy learning for general-purpose robotics. Project page: https://showlab.github.io/World-VLA-Loop/.