MultiGraspNet: A Multitask 3D Vision Model for Multi-gripper Robotic Grasping
作者: Stephany Ortuno-Chanelo, Paolo Rabino, Enrico Civitelli, Tatiana Tommasi, Raffaello Camoriano
分类: cs.RO, cs.CV
发布日期: 2026-02-06
💡 一句话要点
MultiGraspNet:用于多夹爪机器人抓取的3D视觉多任务模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人抓取 多夹爪 3D视觉 多任务学习 深度学习
📋 核心要点
- 现有基于视觉的机器人抓取模型通常仅限于单个夹爪或依赖于定制混合夹爪,限制了其通用性。
- MultiGraspNet通过统一的框架,同时预测平行和真空夹爪的可行姿态,使单个机器人能够处理多个末端执行器。
- 实验结果表明,MultiGraspNet在真实场景中优于真空基线,抓取更多已知和未知物体,并在平行抓取任务中表现出竞争力。
📝 摘要(中文)
本文提出MultiGraspNet,一种新颖的多任务3D深度学习方法,可在统一框架内同时预测平行夹爪和真空夹爪的可行姿态,使单个机器人能够处理多个末端执行器。该模型在经过对齐的GraspNet-1Billion和SuctionNet-1Billion数据集上进行训练,生成可抓取性掩码,量化每个场景点成功抓取的适用性。通过共享早期特征,同时保持特定于夹爪的细化器,MultiGraspNet有效地利用了跨抓取模式的互补信息,从而增强了在杂乱场景中的鲁棒性和适应性。通过广泛的实验分析来表征MultiGraspNet的性能,证明了其在相关基准测试中与单任务模型的竞争力。在单臂多夹爪机器人设置上进行的真实世界实验表明,该方法优于真空基线,抓取了多16%的已知物体和多32%的未知物体,同时获得了平行抓取任务的有竞争力的结果。
🔬 方法详解
问题定义:现有基于视觉的机器人抓取方法通常针对单一类型的夹爪,例如平行夹爪或真空吸盘,或者依赖于定制的混合夹爪。这些方法无法充分利用不同类型夹爪之间的互补信息,并且难以泛化到新的任务和场景中。此外,为每种夹爪单独训练模型需要大量的标注数据和计算资源。
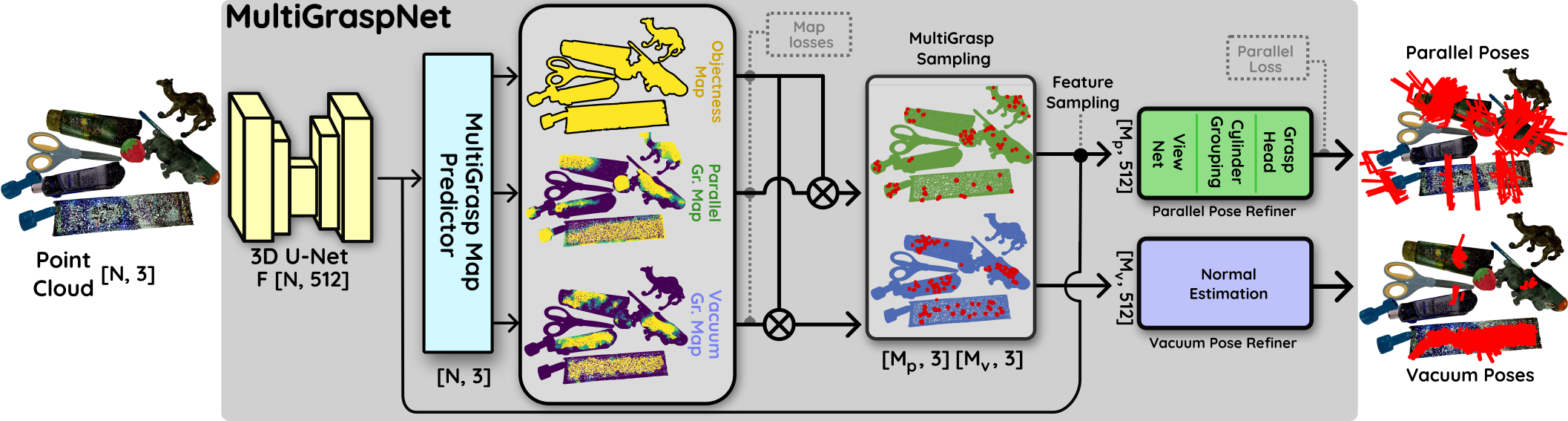
核心思路:MultiGraspNet的核心思路是利用多任务学习框架,同时预测不同类型夹爪(平行夹爪和真空夹爪)的可行抓取姿态。通过共享早期特征提取层,模型可以学习到通用的场景理解能力,并利用不同夹爪之间的互补信息来提高抓取预测的准确性和鲁棒性。特定于夹爪的细化器则负责对不同夹爪的抓取姿态进行精细调整。
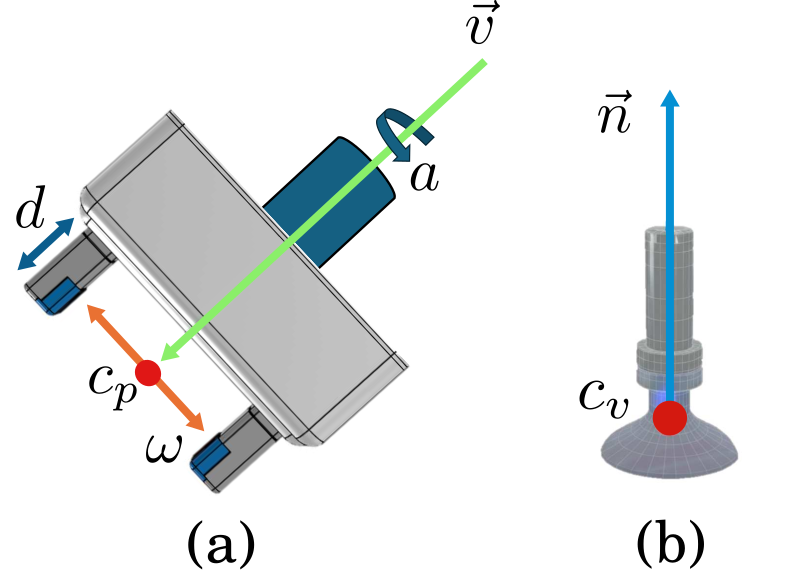
技术框架:MultiGraspNet的整体架构包含以下几个主要模块:1) 共享特征提取器:用于从3D场景点云中提取通用特征表示。2) 夹爪特定细化器:针对每种夹爪类型(平行夹爪和真空夹爪)分别设计,用于根据共享特征预测可行的抓取姿态。3) 可抓取性掩码生成器:用于量化每个场景点成功抓取的适用性。模型首先通过共享特征提取器提取场景特征,然后将特征分别输入到平行夹爪和真空夹爪的细化器中,得到各自的抓取姿态预测。最后,通过可抓取性掩码生成器生成每个场景点的可抓取性得分。
关键创新:MultiGraspNet的关键创新在于其多任务学习框架,该框架能够同时预测不同类型夹爪的可行抓取姿态,并利用不同夹爪之间的互补信息。与现有方法相比,MultiGraspNet能够更有效地利用数据,提高抓取预测的准确性和鲁棒性,并实现单个机器人处理多个末端执行器。
关键设计:MultiGraspNet使用PointNet++作为共享特征提取器,并设计了特定于夹爪的细化器,用于对不同夹爪的抓取姿态进行精细调整。模型使用GraspNet-1Billion和SuctionNet-1Billion数据集进行训练,并采用交叉熵损失函数来优化可抓取性掩码的预测。为了平衡不同夹爪之间的学习,模型还使用了加权损失函数。
🖼️ 关键图片

📊 实验亮点
MultiGraspNet在真实机器人实验中表现出色,相比于真空吸盘基线,在抓取已知物体时成功率提升了16%,在抓取未知物体时成功率提升了32%。同时,在平行夹爪任务中,MultiGraspNet也取得了具有竞争力的结果,证明了其在多夹爪机器人抓取方面的有效性。
🎯 应用场景
MultiGraspNet在工业自动化、物流、仓储等领域具有广泛的应用前景。它可以使机器人能够灵活地处理各种形状和尺寸的物体,提高生产效率和自动化水平。例如,在电商仓库中,机器人可以利用MultiGraspNet同时使用平行夹爪和真空吸盘来抓取不同类型的商品,从而实现更高效的拣选和包装。
📄 摘要(原文)
Vision-based models for robotic grasping automate critical, repetitive, and draining industrial tasks. Existing approaches are typically limited in two ways: they either target a single gripper and are potentially applied on costly dual-arm setups, or rely on custom hybrid grippers that require ad-hoc learning procedures with logic that cannot be transferred across tasks, restricting their general applicability. In this work, we present MultiGraspNet, a novel multitask 3D deep learning method that predicts feasible poses simultaneously for parallel and vacuum grippers within a unified framework, enabling a single robot to handle multiple end effectors. The model is trained on the richly annotated GraspNet-1Billion and SuctionNet-1Billion datasets, which have been aligned for the purpose, and generates graspability masks quantifying the suitability of each scene point for successful grasps. By sharing early-stage features while maintaining gripper-specific refiners, MultiGraspNet effectively leverages complementary information across grasping modalities, enhancing robustness and adaptability in cluttered scenes. We characterize MultiGraspNet's performance with an extensive experimental analysis, demonstrating its competitiveness with single-task models on relevant benchmarks. We run real-world experiments on a single-arm multi-gripper robotic setup showing that our approach outperforms the vacuum baseline, grasping 16% percent more seen objects and 32% more of the novel ones, while obtaining competitive results for the parallel task.