Now You See That: Learning End-to-End Humanoid Locomotion from Raw Pixels
作者: Wandong Sun, Yongbo Su, Leoric Huang, Alex Zhang, Dwyane Wei, Mu San, Daniel Tian, Ellie Cao, Finn Yan, Ethan Xie, Zongwu Xie
分类: cs.RO
发布日期: 2026-02-06
💡 一句话要点
提出端到端框架,从原始像素学习稳健的人形机器人运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人形机器人 运动控制 深度学习 模拟到真实 行为蒸馏 地形适应 视觉感知
📋 核心要点
- 现有基于视觉的人形机器人运动控制方法受限于模拟到真实环境的差距,导致感知噪声影响性能。
- 论文提出端到端框架,通过高保真深度传感器模拟和视觉感知行为蒸馏,实现稳健的知识迁移。
- 通过地形特定奖励塑造和多评论家/判别器学习,使机器人能够适应多种地形,完成复杂运动任务。
📝 摘要(中文)
本文提出了一种端到端的视觉驱动人形机器人运动框架,旨在解决基于视觉的人形机器人运动控制中存在的两个主要问题:一是模拟到真实环境的差距导致感知噪声,降低了精细任务的性能;二是跨多种地形训练统一策略时,学习目标相互冲突。为了实现稳健的模拟到真实环境迁移,本文开发了一种高保真深度传感器模拟,捕捉了真实世界传感中固有的立体匹配伪影和校准不确定性。此外,还提出了一种视觉感知的行为蒸馏方法,该方法将潜在空间对齐与噪声不变的辅助任务相结合,从而能够有效地将来自特权高度图的知识迁移到嘈杂的深度观测。为了适应多种地形,本文引入了特定于地形的奖励塑造,并结合多评论家和多判别器学习,其中专用网络捕获每种地形类型的不同动态和运动先验。在配备不同立体深度摄像头的两个人形机器人平台上验证了该方法。结果表明,该策略在各种环境中表现出强大的性能,无缝处理了高平台和宽间隙等极端挑战,以及双向长期楼梯遍历等精细任务。
🔬 方法详解
问题定义:现有基于视觉的人形机器人运动控制方法,在从模拟环境迁移到真实环境时,会受到感知噪声的严重影响,尤其是在需要精细控制的任务中表现不佳。此外,针对不同地形训练统一的控制策略,由于不同地形的运动动力学差异较大,容易导致学习目标冲突,难以获得理想的控制效果。
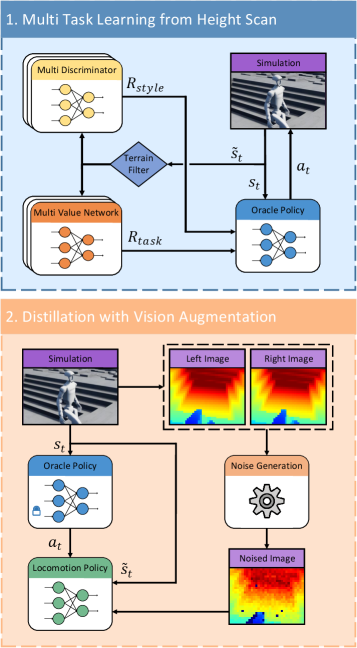
核心思路:论文的核心思路是构建一个端到端的学习框架,直接从原始像素输入学习人形机器人的运动控制策略。为了解决模拟到真实环境的差距,采用高保真深度传感器模拟,尽可能还原真实环境中的感知噪声。同时,利用视觉感知的行为蒸馏方法,将模拟环境中学习到的知识迁移到真实环境中。为了适应多种地形,采用地形特定的奖励塑造和多评论家/判别器学习,使机器人能够学习到针对不同地形的运动策略。
技术框架:整体框架包含以下几个主要模块:1) 高保真深度传感器模拟器,用于生成带有真实感知噪声的深度图像;2) 视觉感知的行为蒸馏模块,用于将模拟环境中的策略知识迁移到真实环境;3) 地形特定的奖励塑造模块,用于引导机器人学习针对不同地形的运动策略;4) 多评论家和多判别器学习模块,用于提高策略的鲁棒性和泛化能力。整个流程是从原始像素输入开始,经过深度图像处理、策略网络、运动控制,最终实现人形机器人的运动。
关键创新:论文的关键创新在于以下几个方面:1) 提出了高保真深度传感器模拟方法,能够有效模拟真实环境中的感知噪声,从而提高了模拟到真实环境迁移的性能;2) 提出了视觉感知的行为蒸馏方法,能够有效地将模拟环境中学习到的知识迁移到真实环境中,克服了感知噪声带来的影响;3) 提出了地形特定的奖励塑造和多评论家/判别器学习方法,能够使机器人学习到针对不同地形的运动策略,提高了机器人的适应能力。
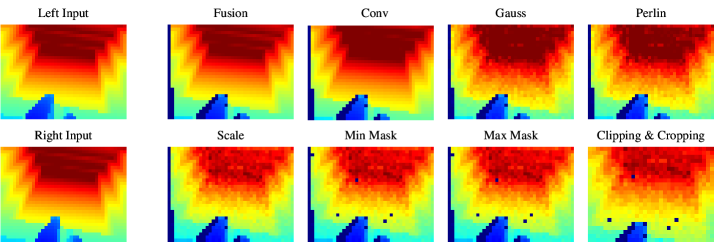
关键设计:在高保真深度传感器模拟中,考虑了立体匹配伪影和校准不确定性等因素,尽可能还原真实环境中的感知噪声。在视觉感知的行为蒸馏中,采用了潜在空间对齐和噪声不变的辅助任务,以提高知识迁移的效率和鲁棒性。在地形特定的奖励塑造中,针对不同地形设计了不同的奖励函数,以引导机器人学习针对不同地形的运动策略。多评论家和多判别器学习中,采用了多个评论家和判别器网络,以提高策略的鲁棒性和泛化能力。
🖼️ 关键图片

📊 实验亮点
该方法在两个不同的人形机器人平台上进行了验证,实验结果表明,该方法能够使机器人在各种复杂环境中实现稳健的运动控制,例如在高平台上行走、跨越宽间隙、以及双向长期楼梯遍历等。与现有方法相比,该方法在复杂地形的适应性和运动控制的鲁棒性方面均有显著提升。
🎯 应用场景
该研究成果可应用于各种需要人形机器人进行复杂运动控制的场景,例如搜救、灾后救援、复杂地形探索、工业巡检等。通过提升机器人在复杂环境下的运动能力,可以使其在这些场景中发挥更大的作用,降低人类的风险和成本,提高工作效率。
📄 摘要(原文)
Achieving robust vision-based humanoid locomotion remains challenging due to two fundamental issues: the sim-to-real gap introduces significant perception noise that degrades performance on fine-grained tasks, and training a unified policy across diverse terrains is hindered by conflicting learning objectives. To address these challenges, we present an end-to-end framework for vision-driven humanoid locomotion. For robust sim-to-real transfer, we develop a high-fidelity depth sensor simulation that captures stereo matching artifacts and calibration uncertainties inherent in real-world sensing. We further propose a vision-aware behavior distillation approach that combines latent space alignment with noise-invariant auxiliary tasks, enabling effective knowledge transfer from privileged height maps to noisy depth observations. For versatile terrain adaptation, we introduce terrain-specific reward shaping integrated with multi-critic and multi-discriminator learning, where dedicated networks capture the distinct dynamics and motion priors of each terrain type. We validate our approach on two humanoid platforms equipped with different stereo depth cameras. The resulting policy demonstrates robust performance across diverse environments, seamlessly handling extreme challenges such as high platforms and wide gaps, as well as fine-grained tasks including bidirectional long-term staircase traversal.