Nipping the Drift in the Bud: Retrospective Rectification for Robust Vision-Language Navigation
作者: Gang He, Zhenyang Liu, Kepeng Xu, Li Xu, Tong Qiao, Wenxin Yu, Chang Wu, Weiying Xie
分类: cs.RO, eess.SY
发布日期: 2026-02-06
💡 一句话要点
BudVLN:通过回溯修正解决视觉-语言导航中的漂移问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 具身智能 模仿学习 暴露偏差 回溯修正
📋 核心要点
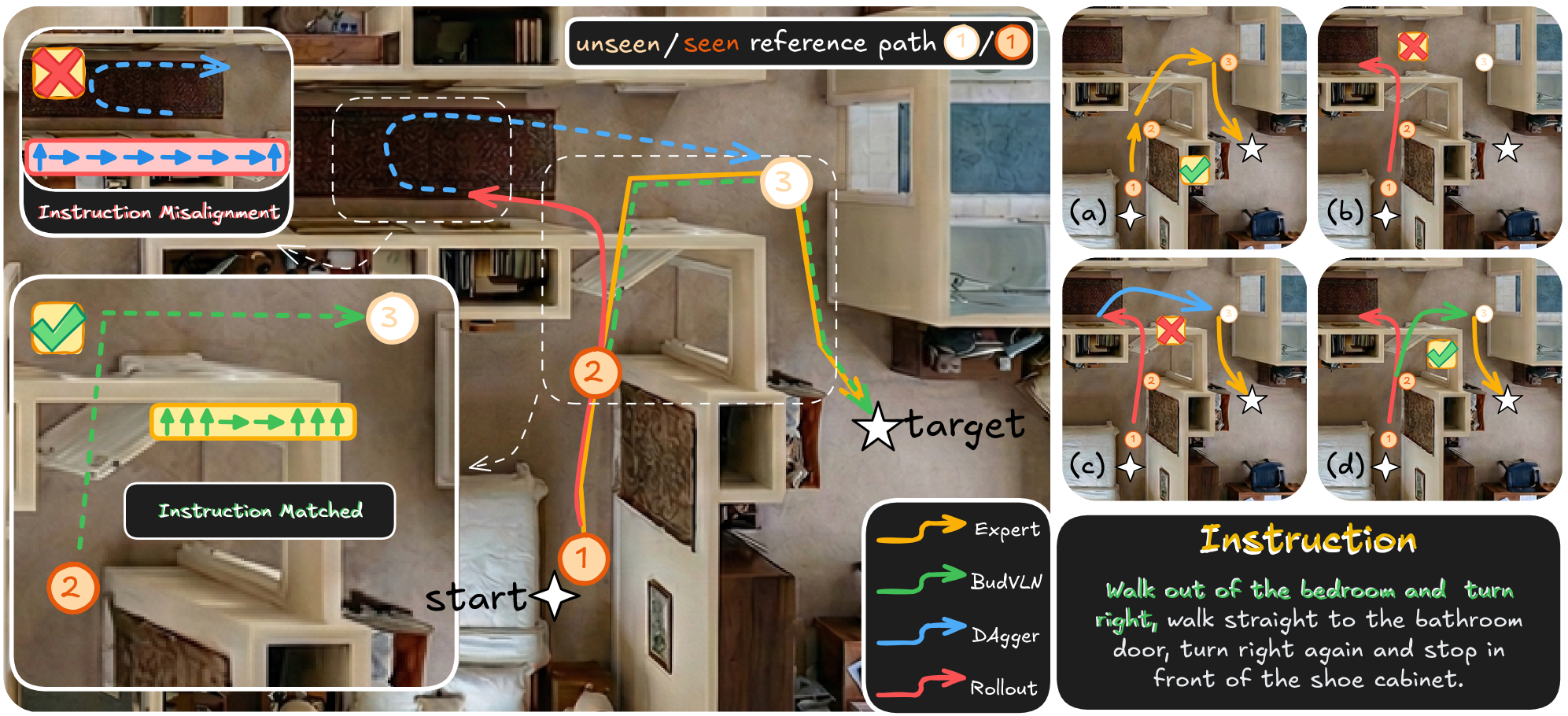
- 模仿学习在VLN中易受暴露偏差影响,导致累积误差,且现有DAgger类方法存在指令-状态未对齐问题。
- BudVLN通过在线学习和回溯修正,利用反事实重锚定和决策条件监督合成,生成语义一致的修正轨迹。
- 在R2R-CE和RxR-CE基准测试中,BudVLN显著缓解了分布偏移,并在成功率和SPL方面取得了SOTA性能。
📝 摘要(中文)
视觉-语言导航(VLN)要求具身智能体理解自然语言指令并在复杂的连续3D环境中导航。然而,主流的模仿学习范式受到暴露偏差的影响,推理过程中的微小偏差会导致累积误差。DAgger类方法试图通过纠正错误状态来缓解这个问题,但我们发现了一个关键限制:指令-状态未对齐。强制智能体从偏离轨迹的状态中学习恢复动作,通常会产生与原始指令语义冲突的监督信号。为了应对这些挑战,我们提出了BudVLN,一个在线框架,通过构建与当前状态分布匹配的监督信号,从on-policy rollouts中学习。BudVLN通过反事实重锚定和决策条件监督合成执行回溯修正,使用测地线oracle合成源自有效历史状态的修正轨迹,确保语义一致性。在标准R2R-CE和RxR-CE基准上的实验表明,BudVLN始终如一地缓解了分布偏移,并在成功率和SPL方面实现了最先进的性能。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据自然语言指令在3D环境中导航。现有的模仿学习方法,特别是DAgger类方法,在训练过程中容易出现暴露偏差,即智能体在推理时遇到的状态与训练时不同,导致累积误差。此外,当智能体偏离正确轨迹时,直接使用DAgger进行纠正可能导致指令与当前状态不匹配,产生语义冲突的监督信号。
核心思路:BudVLN的核心思路是通过回溯修正来解决指令-状态未对齐的问题。它不是直接从当前错误状态学习恢复动作,而是从历史状态中选择一个“锚点”,并基于该锚点生成修正轨迹。这样可以确保修正轨迹与原始指令在语义上保持一致,从而避免产生错误的监督信号。
技术框架:BudVLN是一个在线学习框架,主要包含以下几个模块:1) 智能体与环境交互,生成on-policy rollouts;2) 从历史状态中选择一个锚点,该锚点是智能体在过去某个时间点所处的状态,且被认为是“有效”的;3) 使用测地线oracle生成从锚点到目标状态的修正轨迹;4) 利用反事实重锚定和决策条件监督合成,生成与当前状态分布匹配的监督信号,用于训练智能体。
关键创新:BudVLN的关键创新在于其回溯修正机制,它通过反事实重锚定和决策条件监督合成,确保了修正轨迹与原始指令的语义一致性。与传统的DAgger类方法相比,BudVLN避免了从错误状态直接学习恢复动作,从而减少了指令-状态未对齐的问题。
关键设计:BudVLN使用测地线oracle来生成修正轨迹,这保证了轨迹的最优性。反事实重锚定选择合适的历史状态作为锚点,决策条件监督合成则根据当前状态和指令生成相应的监督信号。具体的损失函数设计需要根据具体的网络结构和任务目标进行调整,但核心思想是最小化智能体的预测动作与修正轨迹提供的监督信号之间的差异。
🖼️ 关键图片


📊 实验亮点
BudVLN在R2R-CE和RxR-CE基准测试中均取得了显著的性能提升。在R2R-CE上,BudVLN的成功率和SPL均超过了现有SOTA方法。在更具挑战性的RxR-CE基准上,BudVLN也表现出强大的泛化能力,显著提高了导航成功率。
🎯 应用场景
该研究成果可应用于机器人导航、虚拟现实、自动驾驶等领域。通过提升智能体在复杂环境中的导航能力,可以实现更智能化的服务机器人、更逼真的虚拟现实体验以及更安全的自动驾驶系统。此外,该方法对于解决其他序列决策问题也具有借鉴意义。
📄 摘要(原文)
Vision-Language Navigation (VLN) requires embodied agents to interpret natural language instructions and navigate through complex continuous 3D environments. However, the dominant imitation learning paradigm suffers from exposure bias, where minor deviations during inference lead to compounding errors. While DAgger-style approaches attempt to mitigate this by correcting error states, we identify a critical limitation: Instruction-State Misalignment. Forcing an agent to learn recovery actions from off-track states often creates supervision signals that semantically conflict with the original instruction. In response to these challenges, we introduce BudVLN, an online framework that learns from on-policy rollouts by constructing supervision to match the current state distribution. BudVLN performs retrospective rectification via counterfactual re-anchoring and decision-conditioned supervision synthesis, using a geodesic oracle to synthesize corrective trajectories that originate from valid historical states, ensuring semantic consistency. Experiments on the standard R2R-CE and RxR-CE benchmarks demonstrate that BudVLN consistently mitigates distribution shift and achieves state-of-the-art performance in both Success Rate and SPL.