HiWET: Hierarchical World-Frame End-Effector Tracking for Long-Horizon Humanoid Loco-Manipulation
作者: Zhanxiang Cao, Liyun Yan, Yang Zhang, Sirui Chen, Jianming Ma, Tianyue Zhan, Shengcheng Fu, Yufei Jia, Cewu Lu, Yue Gao
分类: cs.RO
发布日期: 2026-02-06
💡 一句话要点
HiWET:用于长时程人形机器人操作的层级世界坐标末端执行器跟踪
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 操作控制 强化学习 分层控制 世界坐标系 末端执行器跟踪 运动学流形先验
📋 核心要点
- 现有方法在人形机器人操作中,通常以身体为中心的坐标系进行控制,导致累积的世界坐标系漂移,影响操作精度。
- HiWET采用分层强化学习框架,将全局推理(高层策略)与动态执行(低层策略)解耦,实现世界坐标系下的精确末端执行器跟踪。
- 实验表明,HiWET在仿真中实现了精确稳定的末端执行器跟踪,并且低层策略可以零样本迁移到真实机器人上。
📝 摘要(中文)
人形机器人操作需要在基座运动和冲击中保持动态稳定,同时执行精确的操作任务。现有方法通常在以身体为中心的坐标系中制定指令,无法固有地纠正腿部运动引起的累积世界坐标系漂移。本文将问题重新定义为世界坐标系末端执行器跟踪,并提出了HiWET,一个分层强化学习框架,将全局推理与动态执行解耦。高层策略生成子目标,联合优化世界坐标系中的末端执行器精度和基座定位,而低层策略在稳定性约束下执行这些命令。本文引入了运动学流形先验(KMP),通过残差学习将操作流形嵌入到动作空间中,从而降低了探索维度并减轻了运动学上无效的行为。大量的仿真和消融研究表明,HiWET在长时程世界坐标系任务中实现了精确而稳定的末端执行器跟踪。在物理人形机器人上验证了低层策略的零样本sim-to-real迁移,证明了在各种操作命令下稳定的运动。这些结果表明,显式的世界坐标系推理与分层控制相结合,为长时程人形机器人操作提供了一种有效且可扩展的解决方案。
🔬 方法详解
问题定义:人形机器人操作需要在运动过程中保持动态平衡,同时精确控制末端执行器。现有方法主要在以身体为中心的坐标系下进行控制,这会导致由于腿部运动产生的累积误差,使得末端执行器在世界坐标系下的精度下降,尤其是在长时程任务中。这种漂移是现有方法的痛点。
核心思路:HiWET的核心思路是将人形机器人操作问题重新定义为世界坐标系下的末端执行器跟踪问题。通过在高层策略中显式地考虑世界坐标系下的目标,并结合分层强化学习,将全局规划和局部执行解耦,从而实现更精确和稳定的操作。这种设计允许系统在高层进行全局推理,并在低层进行动态执行,从而更好地应对运动和冲击。
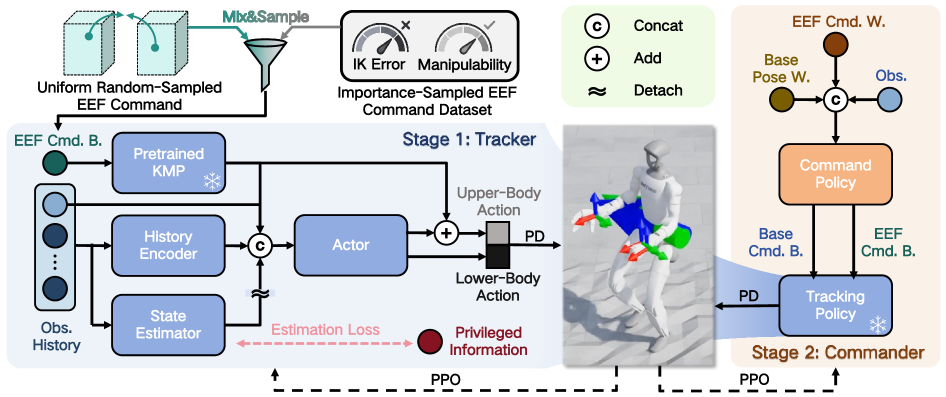
技术框架:HiWET是一个分层强化学习框架,包含两个主要模块:高层策略和低层策略。高层策略负责生成子目标,这些子目标联合优化末端执行器在世界坐标系中的精度和基座的定位。低层策略则负责在稳定性约束下执行这些子目标。整个框架通过强化学习进行训练,高层策略的学习目标是最大化任务完成的奖励,低层策略的学习目标是稳定地执行高层策略给出的指令。
关键创新:HiWET的关键创新在于以下两点:一是将人形机器人操作问题重新定义为世界坐标系下的末端执行器跟踪问题,从而能够显式地纠正累积误差。二是引入了运动学流形先验(KMP),通过残差学习将操作流形嵌入到动作空间中,从而降低了探索维度并减轻了运动学上无效的行为。KMP的引入使得智能体能够更有效地探索动作空间,并更快地学习到有效的策略。
关键设计:HiWET的关键设计包括:高层策略使用Transformer网络进行建模,以捕捉长时程依赖关系。低层策略使用PID控制器和神经网络相结合的方式,以实现精确的运动控制。运动学流形先验(KMP)通过学习一个残差网络,将动作限制在运动学可行的范围内。损失函数包括末端执行器跟踪误差、基座定位误差和稳定性惩罚项。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
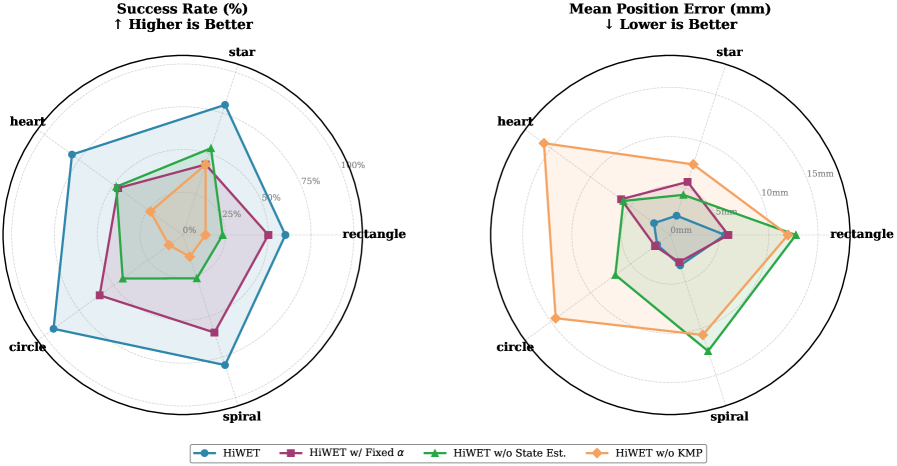
HiWET在仿真实验中表现出色,实现了精确稳定的末端执行器跟踪。消融实验验证了KMP的有效性。更重要的是,低层策略成功地零样本迁移到真实的物理人形机器人上,证明了HiWET的sim-to-real迁移能力和在真实环境中的可行性。具体的性能数据未知。
🎯 应用场景
HiWET在人形机器人操作领域具有广泛的应用前景,例如在复杂环境中进行物体搬运、装配等任务。该研究成果可以应用于智能制造、仓储物流、家庭服务等领域,提高人形机器人的自主性和适应性,使其能够更好地完成各种复杂的操作任务,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Humanoid loco-manipulation requires executing precise manipulation tasks while maintaining dynamic stability amid base motion and impacts. Existing approaches typically formulate commands in body-centric frames, fail to inherently correct cumulative world-frame drift induced by legged locomotion. We reformulate the problem as world-frame end-effector tracking and propose HiWET, a hierarchical reinforcement learning framework that decouples global reasoning from dynamic execution. The high-level policy generates subgoals that jointly optimize end-effector accuracy and base positioning in the world frame, while the low-level policy executes these commands under stability constraints. We introduce a Kinematic Manifold Prior (KMP) that embeds the manipulation manifold into the action space via residual learning, reducing exploration dimensionality and mitigating kinematically invalid behaviors. Extensive simulation and ablation studies demonstrate that HiWET achieves precise and stable end-effector tracking in long-horizon world-frame tasks. We validate zero-shot sim-to-real transfer of the low-level policy on a physical humanoid, demonstrating stable locomotion under diverse manipulation commands. These results indicate that explicit world-frame reasoning combined with hierarchical control provides an effective and scalable solution for long-horizon humanoid loco-manipulation.