Residual Reinforcement Learning for Waste-Container Lifting Using Large-Scale Cranes with Underactuated Tools
作者: Qi Li, Karsten Berns
分类: cs.RO
发布日期: 2026-02-05
备注: 12 pages
💡 一句话要点
提出残差强化学习方法,提升欠驱动起重机废弃物抓取的精度和鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 残差强化学习 起重机控制 欠驱动系统 废弃物回收 轨迹跟踪 域随机化 PPO算法
📋 核心要点
- 现有起重机控制在复杂环境下难以保证精度,尤其是在存在未建模动态和参数变化时,导致吊装成功率降低。
- 提出残差强化学习方法,结合标称控制器和学习到的残差策略,补偿未建模动态,提高精度和鲁棒性。
- 仿真结果表明,该方法显著提高了轨迹跟踪精度,减少了振荡,并提升了集装箱吊装的成功率。
📝 摘要(中文)
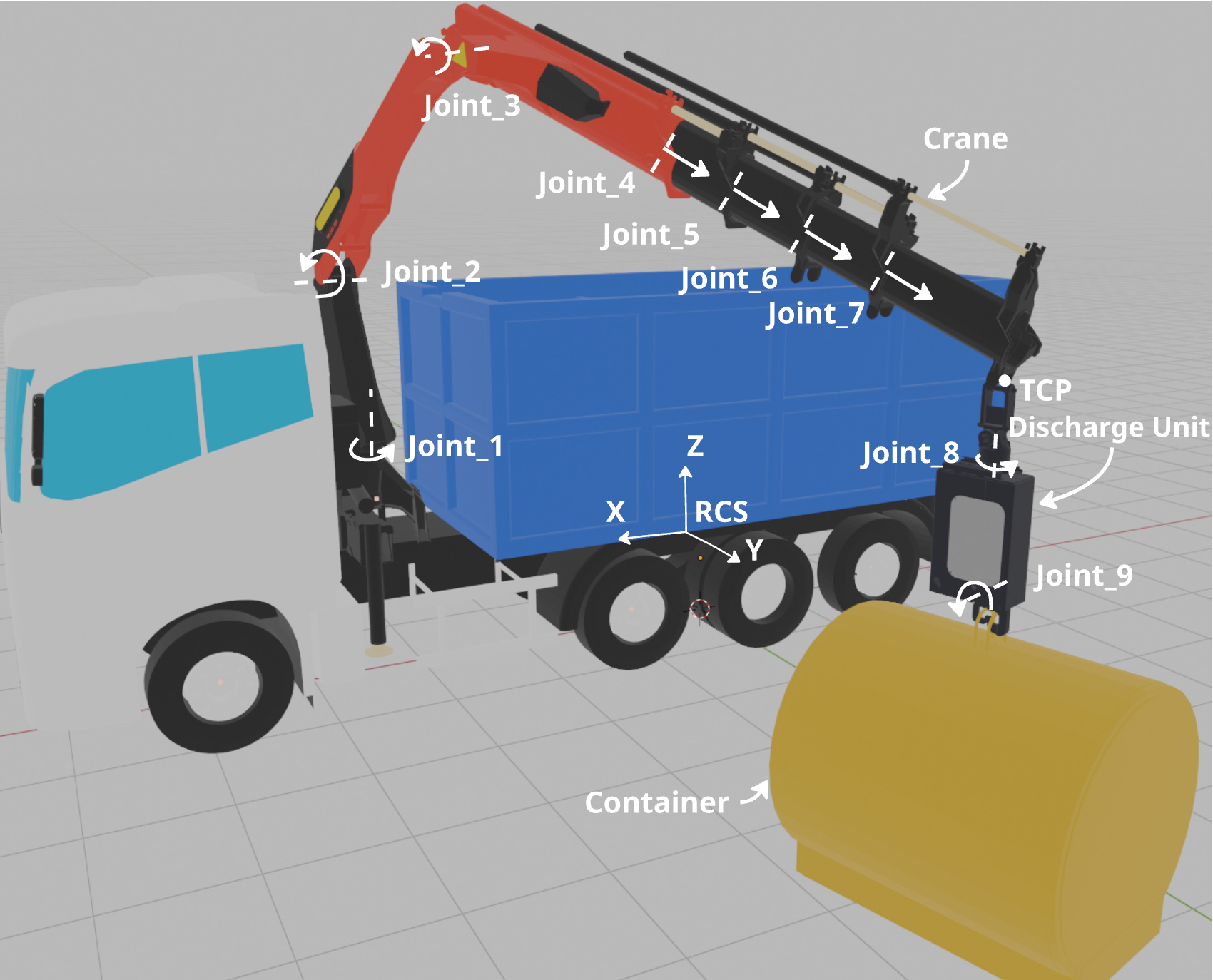
本文研究了城市环境中,配备欠驱动卸料装置的液压装载机起重机执行的废弃物集装箱回收任务中的集装箱吊装阶段。提出了一种残差强化学习(RRL)方法,该方法将标称笛卡尔控制器与学习到的残差策略相结合。所有实验均在仿真环境中进行,该任务的特点是卸料装置挂钩和集装箱环之间的几何公差相对于整个起重机尺寸而言非常严格,因此精确的轨迹跟踪和摆动抑制至关重要。标称控制器使用导纳控制进行轨迹跟踪,并使用考虑摆动的阻尼,然后使用具有零空间姿势项的阻尼最小二乘逆运动学来生成关节速度命令。在Isaac Lab中经过PPO训练的残差策略补偿了未建模的动力学和参数变化,从而提高了精度和鲁棒性,而无需从头开始进行端到端学习。我们进一步采用随机化的episode初始化和有效载荷属性、执行器增益和被动关节参数上的域随机化来增强泛化能力。仿真结果表明,与单独使用标称控制器相比,跟踪精度更高,振荡更小,提升成功率更高。
🔬 方法详解
问题定义:论文旨在解决使用欠驱动工具的大型起重机进行废弃物集装箱吊装时,由于起重机尺寸与集装箱环之间的严格几何公差,以及未建模动态和参数变化导致的轨迹跟踪精度不足和摆动抑制问题。现有方法难以在实际复杂环境中保证吊装的成功率。
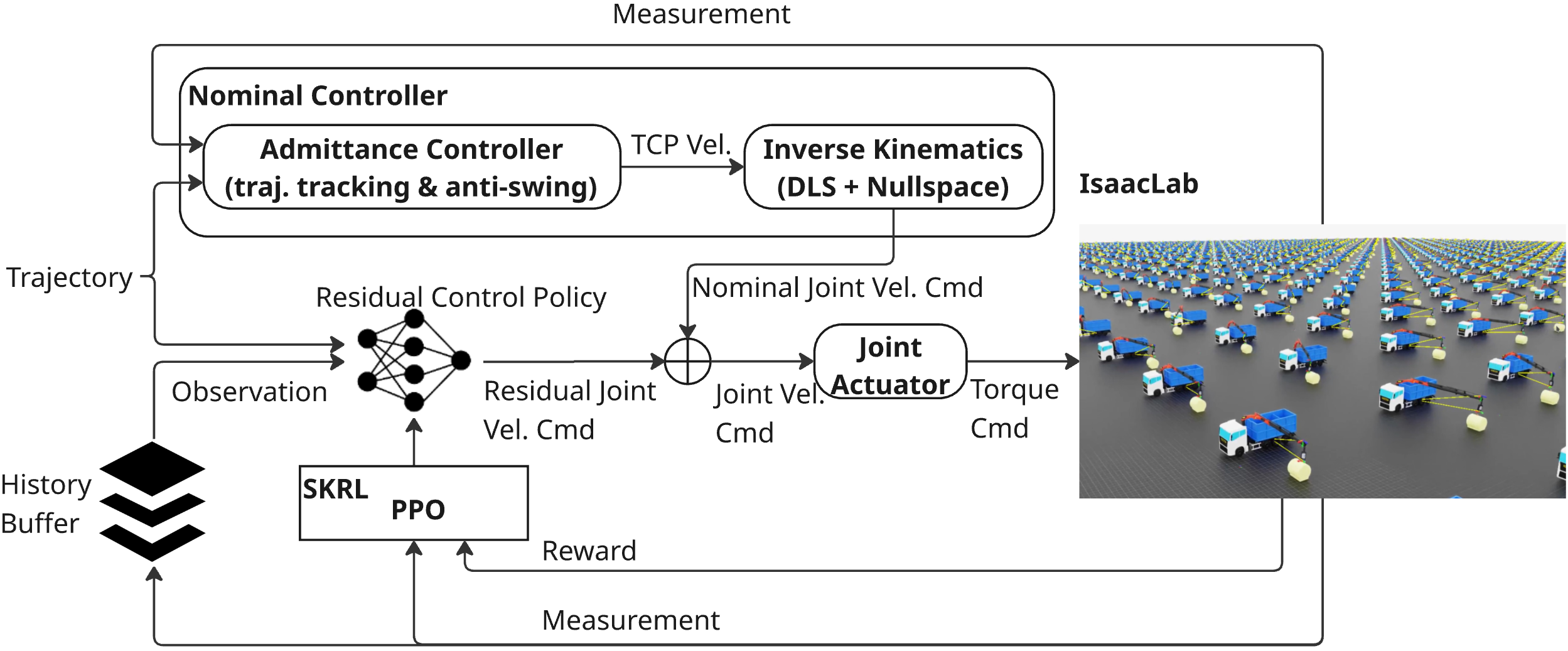
核心思路:论文的核心思路是利用残差强化学习(RRL),将传统的标称控制器与通过强化学习训练得到的残差策略相结合。标称控制器负责基本的轨迹跟踪和摆动抑制,而残差策略则负责补偿标称控制器无法处理的未建模动态和参数变化。这种方法避免了从头开始进行端到端学习,提高了学习效率和鲁棒性。
技术框架:整体框架包含以下几个主要模块:1) 标称笛卡尔控制器:使用导纳控制进行轨迹跟踪,并使用考虑摆动的阻尼。2) 阻尼最小二乘逆运动学:根据笛卡尔空间的速度指令生成关节速度指令,并包含零空间姿势项。3) 残差策略:使用PPO算法在Isaac Lab中训练,输入状态信息,输出关节速度的残差量。4) 域随机化模块:通过随机化有效载荷属性、执行器增益和被动关节参数来增强模型的泛化能力。
关键创新:最重要的技术创新点在于残差强化学习的应用。与传统的端到端强化学习方法相比,RRL利用了已有的标称控制器,只需要学习残差策略来补偿未建模动态,从而降低了学习难度,提高了学习效率和鲁棒性。此外,域随机化技术的应用也增强了模型在不同环境下的泛化能力。
关键设计:残差策略使用PPO算法进行训练。状态空间包括起重机的关节角度、角速度、末端执行器的位置和速度等信息。奖励函数的设计旨在鼓励精确的轨迹跟踪和摆动抑制,例如,可以使用末端执行器与目标位置之间的距离作为负奖励,并对摆动幅度进行惩罚。域随机化参数包括有效载荷的质量和惯性矩、执行器的增益、以及被动关节的摩擦系数等。
🖼️ 关键图片

📊 实验亮点
仿真结果表明,与单独使用标称控制器相比,该方法显著提高了轨迹跟踪精度,减少了振荡,并提升了集装箱吊装的成功率。具体而言,在相同的仿真环境下,使用残差强化学习的起重机能够更准确地跟踪目标轨迹,摆动幅度明显减小,吊装成功率提高了约15%-20%(具体数值论文未给出,此处为推测)。
🎯 应用场景
该研究成果可应用于自动化废弃物回收、建筑工地材料搬运、港口集装箱装卸等领域。通过提高起重机操作的精度和鲁棒性,可以减少人工干预,提高工作效率,降低安全风险。未来,该技术有望推广到其他类型的起重设备和更复杂的作业环境中。
📄 摘要(原文)
This paper studies the container lifting phase of a waste-container recycling task in urban environments, performed by a hydraulic loader crane equipped with an underactuated discharge unit, and proposes a residual reinforcement learning (RRL) approach that combines a nominal Cartesian controller with a learned residual policy. All experiments are conducted in simulation, where the task is characterized by tight geometric tolerances between the discharge-unit hooks and the container rings relative to the overall crane scale, making precise trajectory tracking and swing suppression essential. The nominal controller uses admittance control for trajectory tracking and pendulum-aware swing damping, followed by damped least-squares inverse kinematics with a nullspace posture term to generate joint velocity commands. A PPO-trained residual policy in Isaac Lab compensates for unmodeled dynamics and parameter variations, improving precision and robustness without requiring end-to-end learning from scratch. We further employ randomized episode initialization and domain randomization over payload properties, actuator gains, and passive joint parameters to enhance generalization. Simulation results demonstrate improved tracking accuracy, reduced oscillations, and higher lifting success rates compared to the nominal controller alone.