A Hybrid Autoencoder for Robust Heightmap Generation from Fused Lidar and Depth Data for Humanoid Robot Locomotion
作者: Dennis Bank, Joost Cordes, Thomas Seel, Simon F. G. Ehlers
分类: cs.RO, cs.LG
发布日期: 2026-02-05
💡 一句话要点
提出一种混合自编码器,用于从融合的激光雷达和深度数据中稳健生成高度图,应用于人形机器人运动。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人形机器人 地形感知 高度图生成 多模态融合 深度学习 卷积神经网络 门控循环单元
📋 核心要点
- 人形机器人需要在复杂环境中可靠感知地形,传统方法依赖人工设计的单传感器流水线,鲁棒性不足。
- 论文提出混合编码器-解码器结构(EDS),融合CNN和GRU,利用多模态数据(深度相机、激光雷达、IMU)生成高度图。
- 实验结果表明,多模态融合显著提升了重建精度,并减少了映射漂移,验证了所提方法的有效性。
📝 摘要(中文)
可靠的地形感知是人形机器人在非结构化、以人为中心的环境中部署的关键前提。本文提出了一种基于学习的框架,该框架使用机器人中心的高度图表示。引入了一种混合编码器-解码器结构(EDS),利用卷积神经网络(CNN)进行空间特征提取,并融合门控循环单元(GRU)核心以实现时间一致性。该架构集成了来自Intel RealSense深度相机、通过高效球面投影处理的LIVOX MID-360激光雷达以及板载IMU的多模态数据。定量结果表明,多模态融合比仅使用深度数据提高了7.2%的重建精度,比仅使用激光雷达提高了9.9%。此外,集成3.2秒的时间上下文减少了映射漂移。
🔬 方法详解
问题定义:人形机器人在复杂环境中运动时,需要准确的地形信息。传统方法依赖于人工设计的单传感器系统,容易受到光照、遮挡等因素的影响,导致地形感知不准确,进而影响机器人的运动控制。现有方法难以充分利用多模态传感器数据,且缺乏时间一致性。
核心思路:论文的核心思路是利用深度学习方法,融合来自不同传感器的多模态数据,生成鲁棒的高度图表示。通过结合CNN的空间特征提取能力和GRU的时间建模能力,实现对地形的准确感知,并减少映射漂移。这种方法旨在克服单传感器系统的局限性,提高地形感知的可靠性。
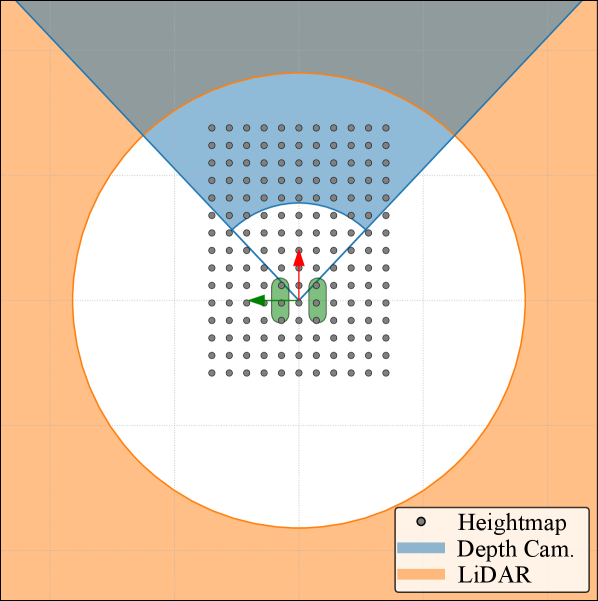
技术框架:整体架构是一个混合编码器-解码器结构(EDS)。编码器部分包含一个CNN用于提取空间特征,以及一个GRU用于建模时间序列信息。解码器部分则负责从编码后的特征重建高度图。输入数据包括来自Intel RealSense深度相机、LIVOX MID-360激光雷达和IMU的数据。激光雷达数据首先通过球面投影进行处理,然后与深度图像对齐。所有数据被输入到EDS中进行融合和处理。
关键创新:最重要的技术创新点在于混合编码器-解码器结构(EDS),它将CNN和GRU结合在一起,充分利用了空间和时间信息。此外,论文还提出了一种有效的数据融合策略,将来自不同传感器的多模态数据整合到统一的框架中。与传统的单传感器系统相比,该方法具有更高的鲁棒性和准确性。
关键设计:CNN部分使用了多个卷积层和池化层,用于提取图像的空间特征。GRU部分则用于建模时间序列信息,捕捉地形的变化趋势。损失函数使用了均方误差(MSE),用于衡量重建的高度图与真实高度图之间的差异。时间上下文窗口大小设置为3.2秒,以平衡计算复杂度和时间建模能力。球面投影采用高效的实现方式,以减少计算量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,多模态融合显著提高了高度图重建的准确性。与仅使用深度数据相比,重建精度提高了7.2%;与仅使用激光雷达相比,重建精度提高了9.9%。此外,集成3.2秒的时间上下文有效地减少了映射漂移。这些结果验证了所提方法的有效性,并表明多模态融合和时间建模对于地形感知至关重要。
🎯 应用场景
该研究成果可应用于人形机器人在复杂环境中的导航、避障和运动规划。例如,在灾难救援、物流配送、家庭服务等场景中,机器人需要能够准确感知地形,才能安全有效地完成任务。该方法还可以扩展到其他类型的机器人,如轮式机器人、无人机等,提高其在复杂环境中的适应能力。
📄 摘要(原文)
Reliable terrain perception is a critical prerequisite for the deployment of humanoid robots in unstructured, human-centric environments. While traditional systems often rely on manually engineered, single-sensor pipelines, this paper presents a learning-based framework that uses an intermediate, robot-centric heightmap representation. A hybrid Encoder-Decoder Structure (EDS) is introduced, utilizing a Convolutional Neural Network (CNN) for spatial feature extraction fused with a Gated Recurrent Unit (GRU) core for temporal consistency. The architecture integrates multimodal data from an Intel RealSense depth camera, a LIVOX MID-360 LiDAR processed via efficient spherical projection, and an onboard IMU. Quantitative results demonstrate that multimodal fusion improves reconstruction accuracy by 7.2% over depth-only and 9.9% over LiDAR-only configurations. Furthermore, the integration of a 3.2 s temporal context reduces mapping drift.