TOLEBI: Learning Fault-Tolerant Bipedal Locomotion via Online Status Estimation and Fallibility Rewards
作者: Hokyun Lee, Woo-Jeong Baek, Junhyeok Cha, Jaeheung Park
分类: cs.RO
发布日期: 2026-02-05
备注: Accepted for Publication at IEEE International Conference on Robotics and Automation (ICRA) 2026
💡 一句话要点
TOLEBI:通过在线状态估计和容错奖励学习具有容错能力的两足行走
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双足行走 强化学习 容错控制 在线状态估计 机器人故障诊断
📋 核心要点
- 现有双足行走强化学习方法在硬件故障处理方面存在不足,真实环境中的干扰可能导致严重后果。
- TOLEBI框架通过模拟故障场景学习容错策略,并结合在线关节状态估计模块,提升了机器人应对故障的能力。
- 实验结果表明,该方法在模拟和真实机器人上均有效,为双足行走的容错学习提供了一种新的解决方案。
📝 摘要(中文)
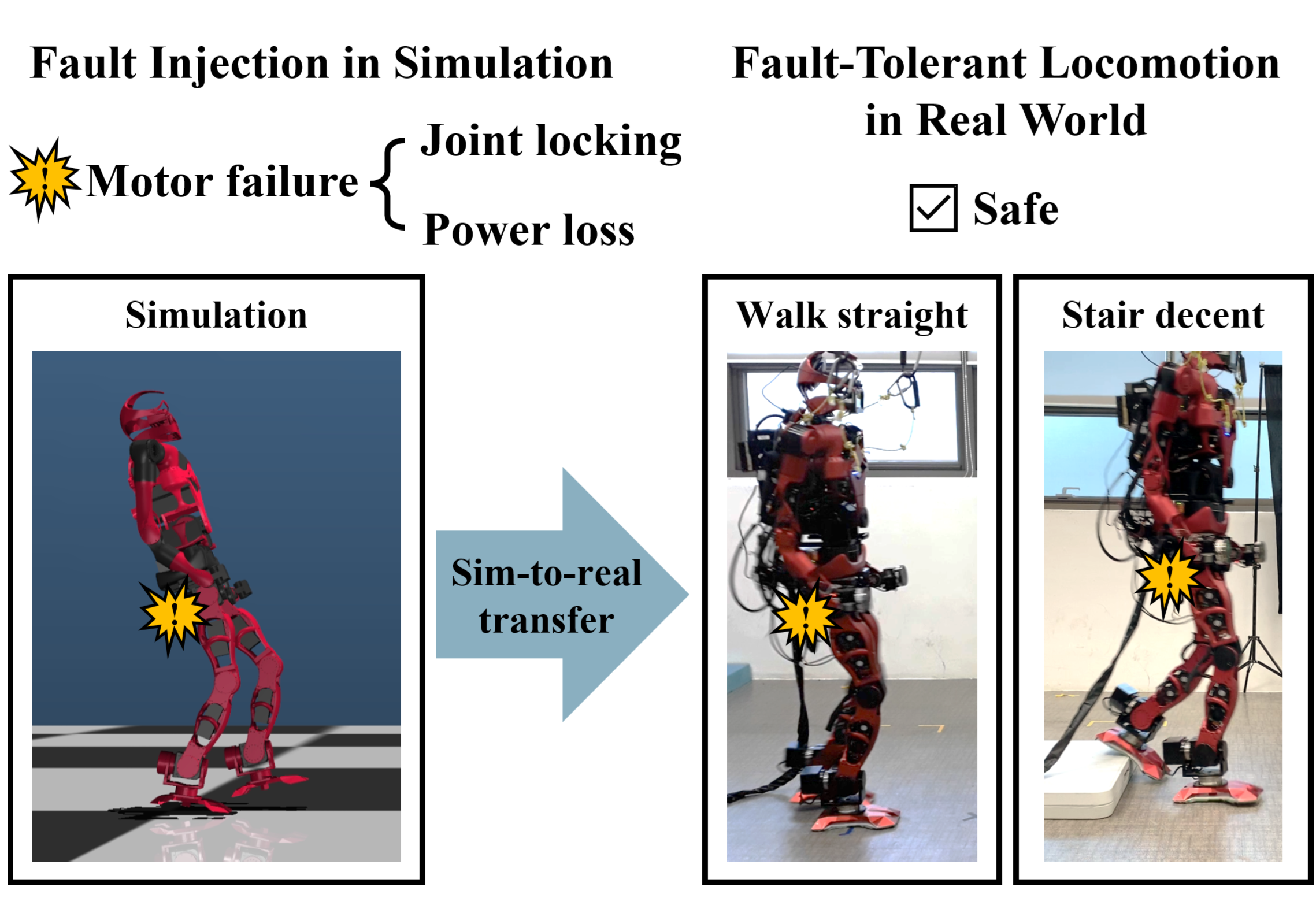
随着学习算法在机器人应用中日益普及,用于双足行走的强化学习已成为人形机器人研究的核心课题。虽然最近的研究在行走任务中取得了很高的成功率,但很少有研究致力于开发能够处理行走过程中可能发生的硬件故障的方法。然而,在现实环境中,环境干扰或硬件故障的突然发生可能会产生严重后果。为了解决这些问题,本文提出了TOLEBI(一种用于双足行走容错学习框架),该框架可以在机器人运行期间处理故障。具体来说,在模拟中注入关节锁定、功率损耗和外部干扰,以学习容错行走策略。除了通过sim-to-real迁移将学习到的策略迁移到真实机器人之外,还加入了一个在线关节状态模块。该模块能够通过参考真实环境下的实际观测值来对关节状况进行分类。在真实环境和模拟环境中对人形机器人TOCABI进行的验证实验突出了所提出方法的适用性。据我们所知,本文提供了一种基于学习的、用于双足行走的容错框架,从而促进了该领域高效学习方法的发展。
🔬 方法详解
问题定义:论文旨在解决双足机器人在实际应用中,由于硬件故障(如关节锁定、功率损失)和外部干扰导致的行走失败问题。现有的强化学习方法通常假设机器人运行环境是理想的,缺乏对故障的鲁棒性,难以应对真实世界的挑战。
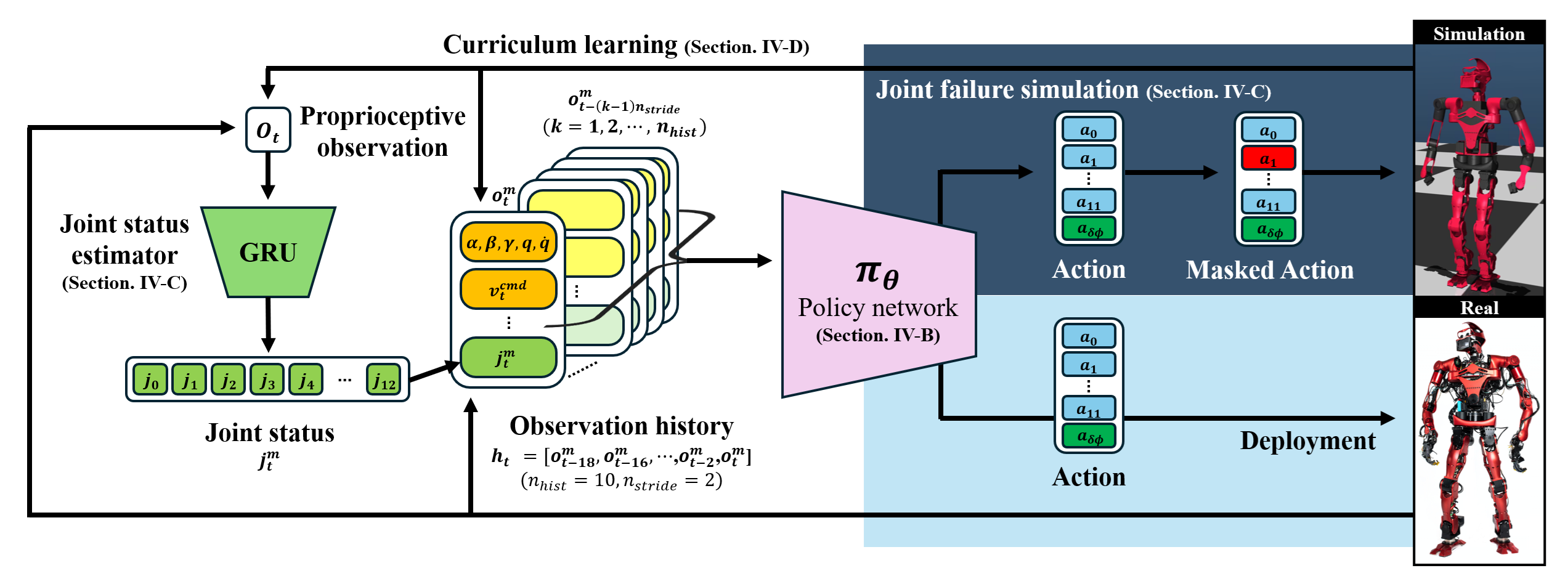
核心思路:论文的核心思路是通过在训练过程中引入故障模拟,使机器人学习在各种故障情况下保持平衡和继续行走的能力。同时,利用在线关节状态估计模块,实时监测关节状态,以便及时调整控制策略,应对突发故障。这种方法结合了强化学习的自适应性和在线状态估计的实时性,提高了机器人的容错能力。
技术框架:TOLEBI框架主要包含以下几个模块:1) 故障模拟模块:在模拟环境中,随机注入关节锁定、功率损失和外部干扰等故障。2) 强化学习模块:使用强化学习算法训练机器人的控制策略,目标是最大化行走距离和稳定性,同时最小化故障带来的影响。3) 在线关节状态估计模块:利用传感器数据(如关节角度、力矩)实时估计关节状态,判断是否存在故障。4) Sim-to-real迁移模块:将模拟环境中训练好的策略迁移到真实机器人上。
关键创新:该论文的关键创新在于提出了一个完整的、基于学习的容错双足行走框架。具体来说,它将故障模拟、强化学习和在线状态估计相结合,使机器人能够在训练过程中学习应对各种故障,并在实际运行时实时监测和处理故障。这是第一个基于学习的、用于双足行走的容错框架。
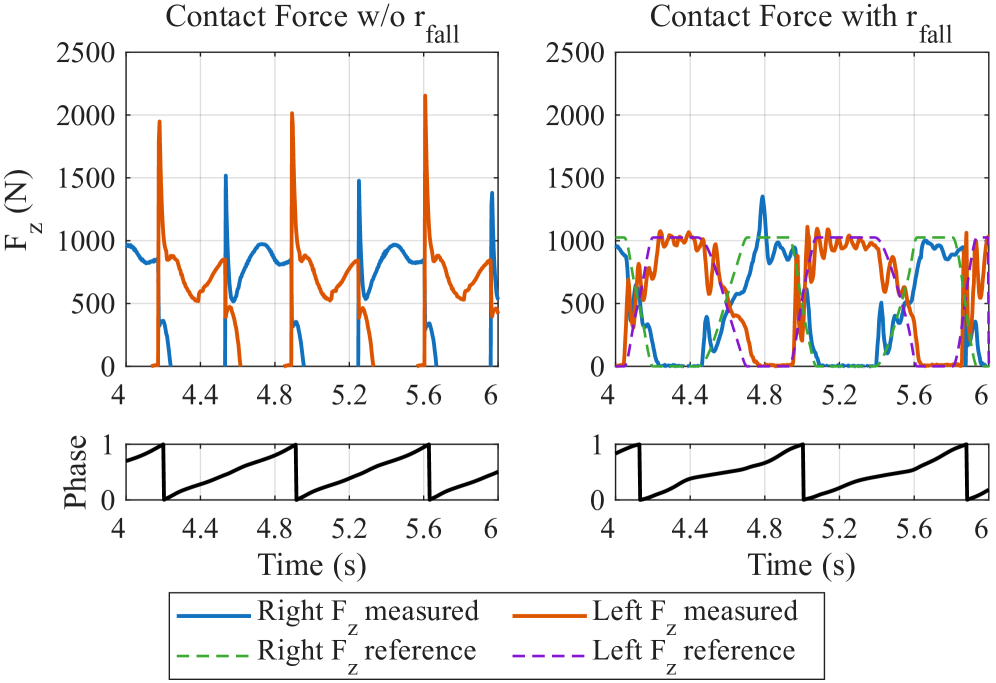
关键设计:在强化学习方面,论文使用了奖励函数来鼓励机器人保持平衡和行走,同时惩罚故障带来的影响。具体来说,奖励函数包括行走距离奖励、稳定性奖励和故障惩罚。在线关节状态估计模块使用了分类器来判断关节状态,分类器的输入是关节角度、力矩等传感器数据。Sim-to-real迁移使用了领域自适应技术,以减小模拟环境和真实环境之间的差异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TOLEBI框架能够有效地提高双足机器人的容错能力。在模拟环境中,与没有容错机制的基线方法相比,TOLEBI框架在存在故障的情况下,行走距离提高了显著百分比(具体数值未知)。在真实机器人上的实验也验证了该方法的有效性,机器人能够在一定程度上应对关节锁定和外部干扰等故障。
🎯 应用场景
该研究成果可应用于各种需要双足机器人行走的复杂和不确定环境,例如搜救、灾后救援、工业巡检等。通过提高机器人的容错能力,可以使其在恶劣条件下更可靠地完成任务,降低因故障导致的风险,具有重要的实际应用价值和潜在的社会效益。
📄 摘要(原文)
With the growing employment of learning algorithms in robotic applications, research on reinforcement learning for bipedal locomotion has become a central topic for humanoid robotics. While recently published contributions achieve high success rates in locomotion tasks, scarce attention has been devoted to the development of methods that enable to handle hardware faults that may occur during the locomotion process. However, in real-world settings, environmental disturbances or sudden occurrences of hardware faults might yield severe consequences. To address these issues, this paper presents TOLEBI (A faulT-tOlerant Learning framEwork for Bipedal locomotIon) that handles faults on the robot during operation. Specifically, joint locking, power loss and external disturbances are injected in simulation to learn fault-tolerant locomotion strategies. In addition to transferring the learned policy to the real robot via sim-to-real transfer, an online joint status module incorporated. This module enables to classify joint conditions by referring to the actual observations at runtime under real-world conditions. The validation experiments conducted both in real-world and simulation with the humanoid robot TOCABI highlight the applicability of the proposed approach. To our knowledge, this manuscript provides the first learning-based fault-tolerant framework for bipedal locomotion, thereby fostering the development of efficient learning methods in this field.