VLN-Pilot: Large Vision-Language Model as an Autonomous Indoor Drone Operator
作者: Bessie Dominguez-Dager, Sergio Suescun-Ferrandiz, Felix Escalona, Francisco Gomez-Donoso, Miguel Cazorla
分类: cs.RO, cs.CV
发布日期: 2026-02-05
💡 一句话要点
提出VLN-Pilot,利用大视觉语言模型实现室内无人机自主导航。
🎯 匹配领域: 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 无人机导航 自主导航 室内环境 指令跟随
📋 核心要点
- 现有室内无人机导航方法依赖规则或几何规划,缺乏对自然语言指令的理解和复杂环境的适应性。
- VLN-Pilot利用大型视觉语言模型,将语言理解与视觉感知融合,实现无人机在复杂室内环境中的自主导航。
- 实验表明,VLN-Pilot在指令跟随任务中表现出色,有望减少操作员工作量并提高室内无人机任务的安全性。
📝 摘要(中文)
本文介绍了一种名为VLN-Pilot的新框架,该框架利用大型视觉语言模型(VLLM)作为室内无人机导航的人工飞行员。VLN-Pilot利用VLLM的多模态推理能力,解释自由形式的自然语言指令,并将其与视觉观察相结合,以规划和执行在无GPS室内环境中的无人机轨迹。与传统的基于规则或几何路径规划方法不同,我们的框架将语言驱动的语义理解与视觉感知相结合,从而以最少的特定任务工程实现上下文感知的高级飞行行为。VLN-Pilot通过推理空间关系、避障和对不可预见事件的动态反应,支持无人机的完全自主指令跟随。我们在一个定制的逼真室内模拟基准上验证了我们的框架,并展示了VLLM驱动的智能体在复杂的指令跟随任务(包括具有多个语义目标的长程导航)中实现高成功率的能力。实验结果突出了用语言引导的自主智能体取代远程无人机飞行员的前景,为在检查、搜索救援和设施监控等任务中可扩展的、人性化的室内无人机控制开辟了道路。我们的结果表明,基于VLLM的飞行员可以显著减少操作员的工作量,同时提高受限室内环境中的安全性和任务灵活性。
🔬 方法详解
问题定义:论文旨在解决室内无人机在复杂、无GPS环境中,如何根据自然语言指令进行自主导航的问题。现有方法主要依赖于规则或几何路径规划,缺乏对自然语言指令的语义理解能力,难以应对复杂和动态的室内环境,需要人工干预。
核心思路:论文的核心思路是利用大型视觉语言模型(VLLM)强大的多模态推理能力,将自然语言指令与无人机获取的视觉信息相结合,使无人机能够理解指令的意图,并自主规划和执行导航任务。通过VLLM,无人机可以理解空间关系、识别障碍物,并对突发事件做出反应。
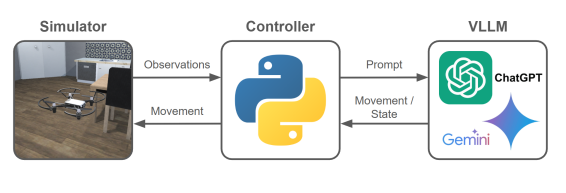
技术框架:VLN-Pilot框架主要包含以下几个模块:1) 视觉感知模块:无人机通过摄像头获取环境的视觉信息。2) 语言理解模块:VLLM解析自然语言指令,提取关键的语义信息。3) 路径规划模块:VLLM根据语义信息和视觉信息,规划无人机的飞行轨迹,并生成控制指令。4) 运动控制模块:无人机执行控制指令,实现自主导航。
关键创新:该论文的关键创新在于将大型视觉语言模型应用于室内无人机自主导航领域,实现了语言驱动的无人机控制。与传统方法相比,VLN-Pilot无需进行大量的特定任务工程,即可实现对复杂指令的理解和执行,具有更强的泛化能力和适应性。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。但可以推断,VLLM的选择和训练,以及视觉信息和语言信息的融合方式是关键的设计要素。此外,如何设计奖励函数,引导无人机学习更有效的导航策略,也是一个重要的考虑因素。具体的技术细节可能需要参考论文的后续版本或相关文献。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VLN-Pilot在定制的逼真室内模拟环境中,能够成功完成复杂的指令跟随任务,包括长距离导航和多目标点导航。该框架展示了VLLM驱动的智能体在室内无人机自主导航方面的巨大潜力,为取代远程无人机操作员提供了可能。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
VLN-Pilot技术可应用于室内无人机的自主巡检、搜索救援、设施监控等领域。该技术能够降低对专业无人机操作员的需求,提高任务执行效率和安全性,尤其是在危险或难以到达的室内环境中具有重要应用价值。未来,该技术有望推动无人机在智慧城市、智能家居等领域的广泛应用。
📄 摘要(原文)
This paper introduces VLN-Pilot, a novel framework in which a large Vision-and-Language Model (VLLM) assumes the role of a human pilot for indoor drone navigation. By leveraging the multimodal reasoning abilities of VLLMs, VLN-Pilot interprets free-form natural language instructions and grounds them in visual observations to plan and execute drone trajectories in GPS-denied indoor environments. Unlike traditional rule-based or geometric path-planning approaches, our framework integrates language-driven semantic understanding with visual perception, enabling context-aware, high-level flight behaviors with minimal task-specific engineering. VLN-Pilot supports fully autonomous instruction-following for drones by reasoning about spatial relationships, obstacle avoidance, and dynamic reactivity to unforeseen events. We validate our framework on a custom photorealistic indoor simulation benchmark and demonstrate the ability of the VLLM-driven agent to achieve high success rates on complex instruction-following tasks, including long-horizon navigation with multiple semantic targets. Experimental results highlight the promise of replacing remote drone pilots with a language-guided autonomous agent, opening avenues for scalable, human-friendly control of indoor UAVs in tasks such as inspection, search-and-rescue, and facility monitoring. Our results suggest that VLLM-based pilots may dramatically reduce operator workload while improving safety and mission flexibility in constrained indoor environments.