RoboPaint: From Human Demonstration to Any Robot and Any View
作者: Jiacheng Fan, Zhiyue Zhao, Yiqian Zhang, Chao Chen, Peide Wang, Hengdi Zhang, Zhengxue Cheng
分类: cs.RO
发布日期: 2026-02-05
备注: 17 pages
💡 一句话要点
RoboPaint:通过人类演示,为任意机器人和视角生成可执行的训练数据。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 灵巧操作 数据生成 Real-Sim-Real 触觉感知 VLA模型 数据重定向
📋 核心要点
- 现有VLA模型在灵巧操作中面临大规模、高质量机器人演示数据获取的瓶颈。
- 提出Real-Sim-Real数据收集和编辑流程,将人类演示转化为机器人可执行的训练数据,无需机器人遥操作。
- 实验表明,该方法在多种操作任务中取得了较高的成功率,并验证了VLA策略在生成数据上的有效性。
📝 摘要(中文)
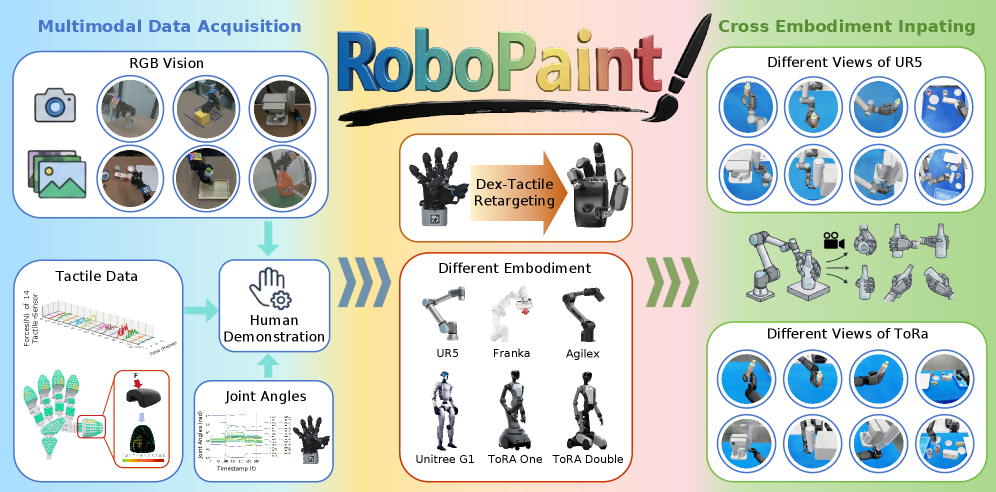
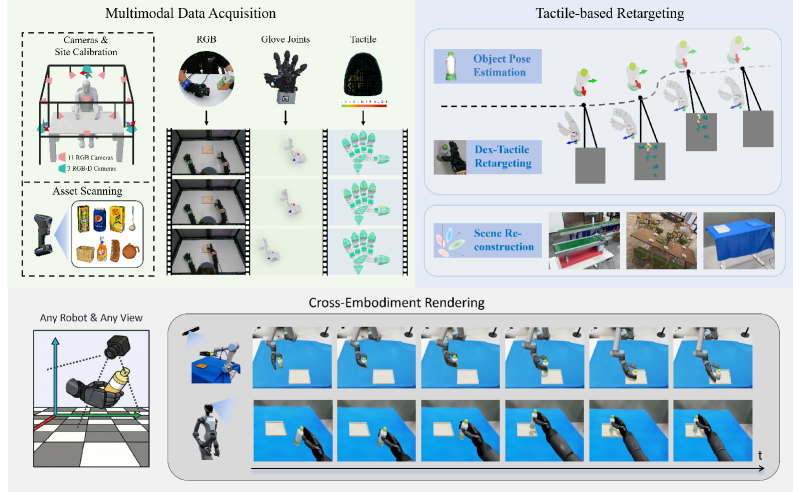
本文提出了一种Real-Sim-Real的数据收集和编辑流程,旨在将人类演示转化为机器人可执行的、特定环境的训练数据,无需直接进行机器人遥操作。构建了标准化的数据收集室,用于捕获多模态的人类演示数据(同步的3个RGB-D视频、11个RGB视频、29自由度手套关节角度和14通道触觉信号)。基于这些数据,引入了一种触觉感知的重定向方法,通过几何和力引导的优化,将人类手部状态映射到机器人灵巧手状态。然后,将重定向的机器人轨迹在逼真的Isaac Sim环境中渲染,以构建机器人训练数据。实验表明,重定向的灵巧手轨迹在10个不同的物体操作任务中实现了84%的成功率。仅使用生成的数据训练的VLA策略(Pi0.5)在抓取放置、推和倾倒三个代表性任务上实现了80%的平均成功率。结论是,可以使用我们的real-sim-real数据管道从人类演示中高效地“绘制”机器人训练数据,为复杂灵巧操作提供了一种可扩展、经济高效的遥操作替代方案,且性能损失最小。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在灵巧操作领域面临着数据瓶颈,即难以获取大规模、高质量的机器人演示数据。传统的机器人遥操作成本高昂且难以扩展,限制了VLA模型的发展。因此,需要一种更高效、更经济的方式来生成机器人训练数据。
核心思路:RoboPaint的核心思路是利用人类演示作为机器人学习的“蓝图”,通过数据重定向和仿真技术,将人类的操作技能迁移到机器人身上。这种方法避免了直接进行机器人遥操作的复杂性和成本,同时利用了人类在操作技能方面的优势。
技术框架:RoboPaint包含以下几个主要阶段:1) 数据采集:构建标准化的数据采集环境,同步记录人类演示的多模态数据,包括RGB-D视频、RGB视频、手套数据和触觉数据。2) 数据重定向:利用触觉感知的重定向方法,将人类手部状态映射到机器人灵巧手状态,通过几何和力引导的优化,生成机器人轨迹。3) 数据生成:将重定向的机器人轨迹在Isaac Sim环境中渲染,生成逼真的机器人训练数据。4) 策略训练:使用生成的数据训练VLA策略,使其能够在真实机器人上执行操作任务。
关键创新:该方法的关键创新在于触觉感知的重定向方法,它不仅考虑了人类手部和机器人手部的几何差异,还考虑了操作过程中的力反馈信息。这种方法能够更准确地将人类的操作技能迁移到机器人身上,提高了机器人操作的成功率。此外,Real-Sim-Real的流程也降低了数据采集的成本,提高了数据生成的效率。
关键设计:在数据重定向阶段,使用了几何和力引导的优化算法。几何约束保证了机器人手部能够到达目标位置,力约束则保证了机器人手部能够施加适当的力。损失函数的设计需要平衡几何误差和力误差,以获得最佳的重定向效果。在VLA策略训练阶段,使用了Pi0.5模型,并针对生成数据的特点进行了优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,重定向的灵巧手轨迹在10个不同的物体操作任务中实现了84%的成功率。更重要的是,仅使用生成的数据训练的VLA策略(Pi0.5)在抓取放置、推和倾倒三个代表性任务上实现了80%的平均成功率。这表明该方法能够有效地将人类的操作技能迁移到机器人身上,并生成高质量的机器人训练数据。
🎯 应用场景
RoboPaint技术可广泛应用于各种需要灵巧操作的机器人应用场景,例如:工业自动化、医疗手术、家庭服务等。通过降低机器人数据采集的成本和难度,加速VLA模型在机器人领域的应用,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Acquiring large-scale, high-fidelity robot demonstration data remains a critical bottleneck for scaling Vision-Language-Action (VLA) models in dexterous manipulation. We propose a Real-Sim-Real data collection and data editing pipeline that transforms human demonstrations into robot-executable, environment-specific training data without direct robot teleoperation. Standardized data collection rooms are built to capture multimodal human demonstrations (synchronized 3 RGB-D videos, 11 RGB videos, 29-DoF glove joint angles, and 14-channel tactile signals). Based on these human demonstrations, we introduce a tactile-aware retargeting method that maps human hand states to robot dex-hand states via geometry and force-guided optimization. Then the retargeted robot trajectories are rendered in a photorealistic Isaac Sim environment to build robot training data. Real world experiments have demonstrated: (1) The retargeted dex-hand trajectories achieve an 84\% success rate across 10 diverse object manipulation tasks. (2) VLA policies (Pi0.5) trained exclusively on our generated data achieve 80\% average success rate on three representative tasks, i.e., pick-and-place, pushing and pouring. To conclude, robot training data can be efficiently "painted" from human demonstrations using our real-sim-real data pipeline. We offer a scalable, cost-effective alternative to teleoperation with minimal performance loss for complex dexterous manipulation.