Affordance-Aware Interactive Decision-Making and Execution for Ambiguous Instructions
作者: Hengxuan Xu, Fengbo Lan, Zhixin Zhao, Shengjie Wang, Mengqiao Liu, Jieqian Sun, Yu Cheng, Tao Zhang
分类: cs.RO
发布日期: 2026-02-05
备注: 14 pages, 10 figures, 8 tables
💡 一句话要点
提出AIDE框架,解决机器人交互式理解模糊指令并执行任务的问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 机器人 视觉-语言模型 人机交互 模糊指令 可供性分析
📋 核心要点
- 现有基于视觉-语言模型的方法在处理机器人与环境交互,理解模糊指令并执行任务方面存在不足,缺乏有效的推理和环境交互。
- AIDE框架通过双流结构,将交互式探索与视觉-语言推理相结合,实现对模糊指令的零样本可供性分析和解释。
- 实验结果表明,AIDE在任务规划成功率和执行准确率方面均优于现有方法,并在真实环境中表现出良好的性能。
📝 摘要(中文)
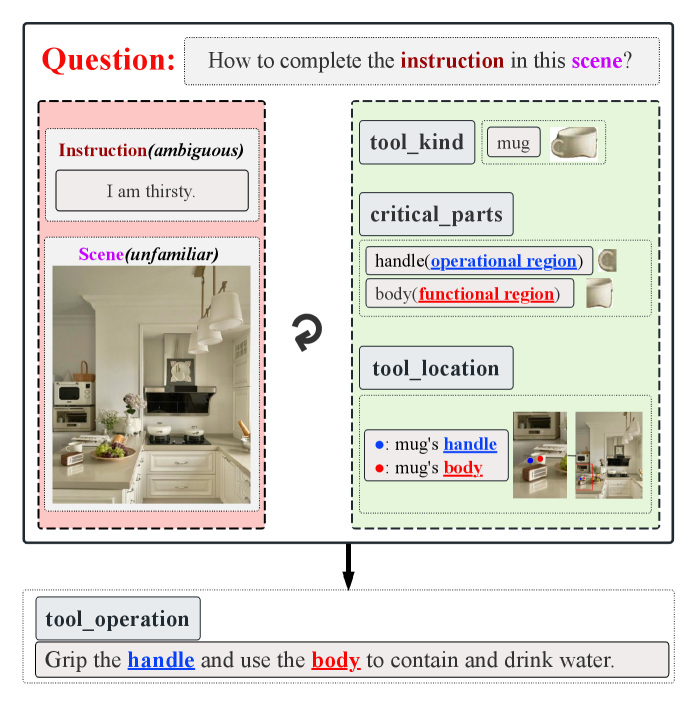
本文提出了一种名为Affordance-Aware Interactive Decision-Making and Execution for Ambiguous Instructions (AIDE) 的双流框架,旨在解决机器人如何在不熟悉的环境中,通过交互式地识别任务相关对象(例如,识别杯子或饮料以响应“我渴了”),来理解和执行模糊的人类指令的问题。AIDE框架集成了交互式探索与视觉-语言推理,其中多阶段推理(MSI)作为决策流,加速决策(ADM)作为执行流,从而实现零样本可供性分析和模糊指令的解释。在模拟和真实环境中的大量实验表明,AIDE在闭环连续执行中以10 Hz的频率实现了超过80%的任务规划成功率和超过95%的准确率,优于现有基于VLM的方法。
🔬 方法详解
问题定义:论文旨在解决机器人如何在不熟悉的环境中,根据模糊的人类指令(例如“我渴了”),通过与环境的交互来识别任务相关的对象并执行任务。现有方法主要依赖于视觉-语言模型,但缺乏有效的推理能力和环境交互机制,导致无法准确理解和执行指令。现有方法的痛点在于无法有效地将视觉信息、语言信息和环境交互信息进行融合,从而导致任务规划和执行的失败。
核心思路:论文的核心思路是构建一个双流框架,将交互式探索与视觉-语言推理相结合。通过交互式探索,机器人可以主动获取环境信息,从而更好地理解模糊指令。通过视觉-语言推理,机器人可以将语言指令与视觉信息进行关联,从而确定任务相关的对象和动作。这种结合使得机器人能够更好地理解和执行模糊指令。
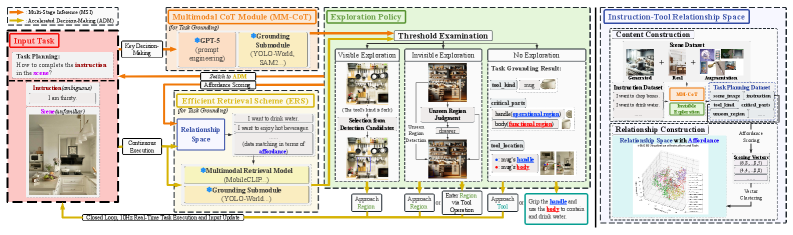
技术框架:AIDE框架包含两个主要模块:多阶段推理(MSI)和加速决策(ADM)。MSI作为决策流,负责根据视觉和语言信息进行推理,确定任务相关的对象和动作。ADM作为执行流,负责根据MSI的输出,控制机器人执行相应的动作。整个框架通过交互式探索不断更新环境信息,从而提高任务规划和执行的准确性。
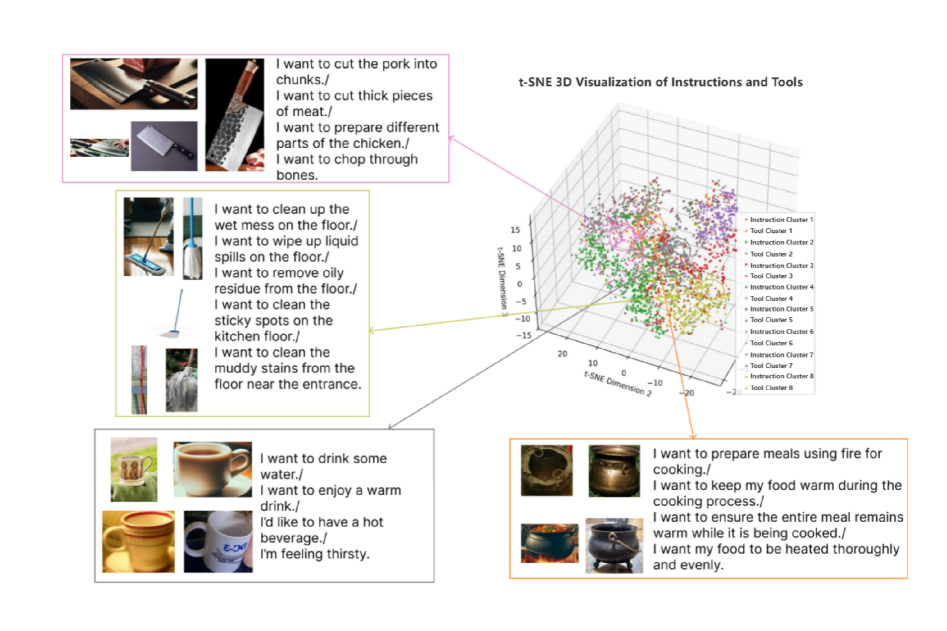
关键创新:AIDE框架的关键创新在于其双流结构和交互式探索机制。双流结构使得框架能够同时进行推理和执行,从而提高效率。交互式探索机制使得机器人能够主动获取环境信息,从而更好地理解模糊指令。此外,AIDE框架还实现了零样本可供性分析,即无需预先训练即可识别任务相关的对象。
关键设计:MSI模块采用多阶段推理的方式,逐步缩小搜索范围,提高推理效率。ADM模块采用加速决策的方式,快速生成执行动作。框架使用视觉-语言模型来关联视觉信息和语言指令。具体的网络结构和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
AIDE框架在模拟和真实环境中的实验结果表明,其任务规划成功率超过80%,闭环连续执行准确率超过95%,并且在10Hz的频率下运行。这些结果显著优于现有的基于VLM的方法,证明了AIDE框架在处理模糊指令和环境交互方面的有效性。具体提升幅度未知,需要参考论文中的详细数据。
🎯 应用场景
该研究成果可应用于家庭服务机器人、工业机器人、医疗机器人等领域。例如,在家庭环境中,机器人可以根据用户的模糊指令(如“把东西拿过来”)来识别并拿取用户需要的物品。在工业环境中,机器人可以根据工人的指令来完成复杂的装配任务。在医疗环境中,机器人可以协助医生进行手术操作。
📄 摘要(原文)
Enabling robots to explore and act in unfamiliar environments under ambiguous human instructions by interactively identifying task-relevant objects (e.g., identifying cups or beverages for "I'm thirsty") remains challenging for existing vision-language model (VLM)-based methods. This challenge stems from inefficient reasoning and the lack of environmental interaction, which hinder real-time task planning and execution. To address this, We propose Affordance-Aware Interactive Decision-Making and Execution for Ambiguous Instructions (AIDE), a dual-stream framework that integrates interactive exploration with vision-language reasoning, where Multi-Stage Inference (MSI) serves as the decision-making stream and Accelerated Decision-Making (ADM) as the execution stream, enabling zero-shot affordance analysis and interpretation of ambiguous instructions. Extensive experiments in simulation and real-world environments show that AIDE achieves the task planning success rate of over 80\% and more than 95\% accuracy in closed-loop continuous execution at 10 Hz, outperforming existing VLM-based methods in diverse open-world scenarios.