MobileManiBench: Simplifying Model Verification for Mobile Manipulation
作者: Wenbo Wang, Fangyun Wei, QiXiu Li, Xi Chen, Yaobo Liang, Chang Xu, Jiaolong Yang, Baining Guo
分类: cs.RO
发布日期: 2026-02-05
💡 一句话要点
MobileManiBench:简化移动操作机器人模型验证的大规模基准测试
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 机器人操作 视觉语言动作模型 仿真基准 强化学习
📋 核心要点
- 现有VLA模型依赖于静态桌面场景数据集,限制了其在复杂移动操作任务中的应用。
- MobileManiBench通过仿真生成多样化、带注释的移动操作轨迹,用于VLA模型验证。
- 该基准包含多种机器人形态、感知模态和任务,加速数据效率和泛化能力的研究。
📝 摘要(中文)
视觉-语言-动作模型在机器人操作领域取得了进展,但仍受限于大型遥操作数据集,这些数据集主要由静态桌面场景组成。本文提出了一个“仿真优先”框架,用于在实际部署之前验证VLA架构,并引入了MobileManiBench,这是一个用于移动机器人操作的大规模基准。该基准构建于NVIDIA Isaac Sim之上,并由强化学习驱动,能够自主生成多样化的操作轨迹,并带有丰富的注释(语言指令、多视角RGB-D-分割图像、同步的对象/机器人状态和动作)。MobileManiBench包含2个移动平台(平行爪和灵巧手机器人)、2个同步摄像头(头部和右腕)、20个类别中的630个对象、5个技能(打开、关闭、拉动、推动、拾取),以及在100个真实场景中执行的100多个任务,从而产生30万条轨迹。这种设计能够对机器人形态、感知模态和策略架构进行可控、可扩展的研究,从而加速数据效率和泛化方面的研究。我们对代表性的VLA模型进行了基准测试,并报告了在复杂模拟环境中对感知、推理和控制的见解。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型主要依赖于在静态桌面环境中收集的大规模遥操作数据集进行训练和验证。这导致模型在面对真实的、动态的移动操作场景时,泛化能力不足。因此,需要一个能够模拟复杂移动操作环境,并提供丰富标注的大规模基准测试平台,以便更好地验证和改进VLA模型。
核心思路:本文的核心思路是采用“仿真优先”的方法,即在实际部署之前,先在仿真环境中对VLA模型进行充分的验证和测试。通过构建一个大规模的移动操作仿真环境,并利用强化学习自动生成多样化的操作轨迹,从而为VLA模型提供充足的训练和测试数据。这种方法可以降低实际部署的风险,并加速模型迭代。
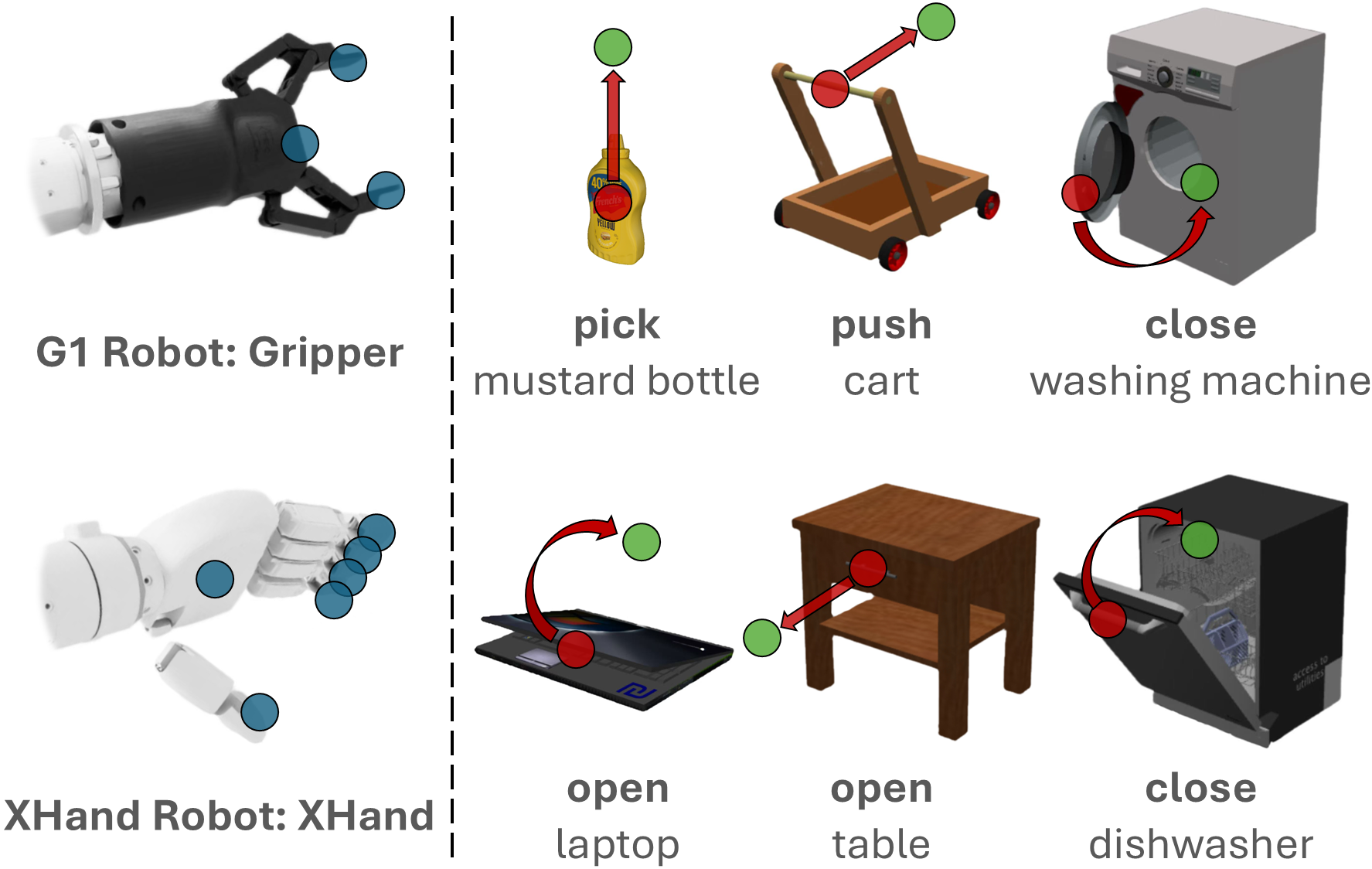
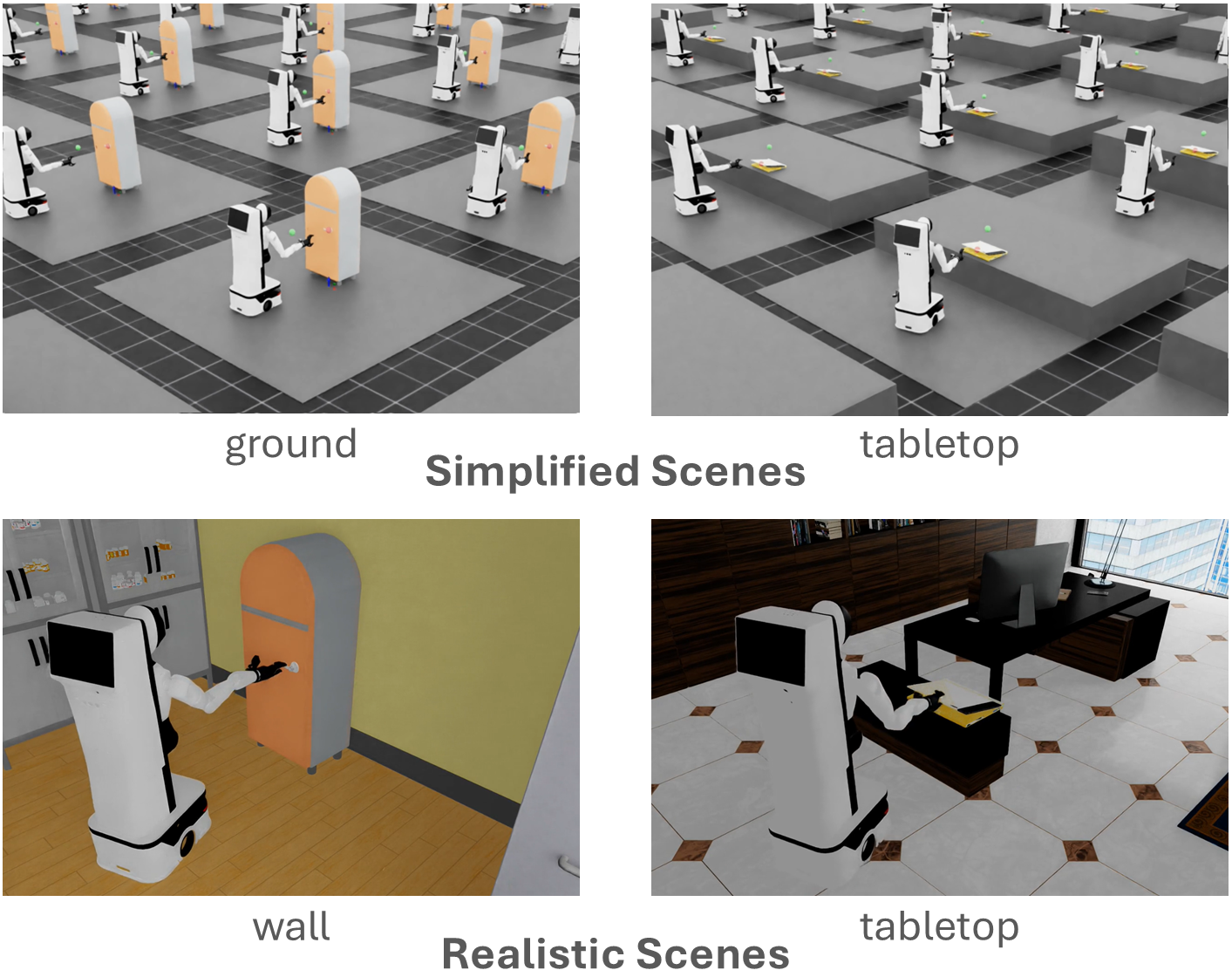
技术框架:MobileManiBench基准测试平台构建于NVIDIA Isaac Sim之上,利用其强大的物理仿真能力和渲染能力。该平台包含两个移动机器人平台(平行爪和灵巧手),配备头部和腕部摄像头。通过强化学习算法,平台可以自主生成包含语言指令、多视角RGB-D图像、分割图像、对象/机器人状态和动作等信息的轨迹数据。整个流程包括场景生成、任务定义、轨迹生成和数据标注等环节。
关键创新:MobileManiBench的关键创新在于其大规模、多样化的移动操作场景和轨迹数据。与现有的静态桌面操作数据集相比,MobileManiBench更加贴近真实的移动操作环境,能够更好地评估VLA模型的泛化能力。此外,该平台还提供了丰富的标注信息,方便研究人员进行各种分析和研究。
关键设计:MobileManiBench包含630个对象,分为20个类别,涵盖了常见的操作对象。平台定义了5种基本操作技能(打开、关闭、拉动、推动、拾取),并设计了100多个不同的任务。强化学习算法用于生成操作轨迹,并对轨迹进行自动标注。此外,平台还提供了API,方便研究人员自定义任务和评估指标。
🖼️ 关键图片
📊 实验亮点
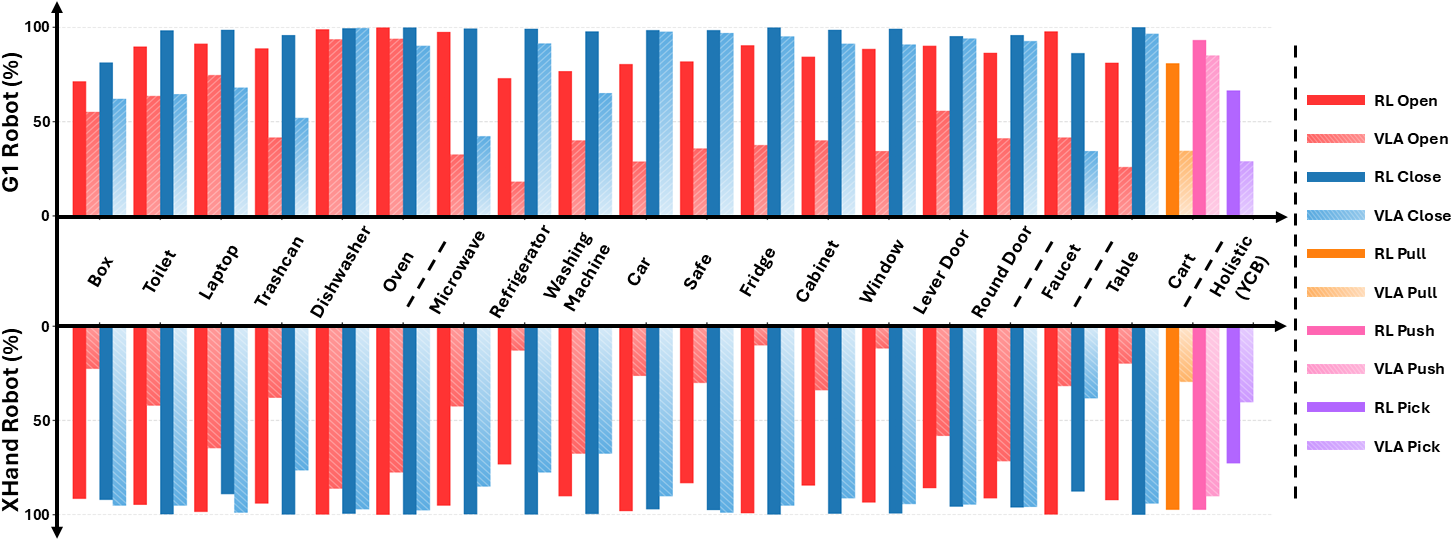
论文通过在MobileManiBench上对代表性的VLA模型进行基准测试,揭示了现有模型在感知、推理和控制方面的局限性。实验结果表明,现有模型在处理复杂场景和长时序任务时,性能显著下降。这些发现为未来的研究方向提供了重要的参考。
🎯 应用场景
MobileManiBench可应用于机器人操作、自动驾驶、智能家居等领域。通过该基准,研究人员可以更有效地开发和验证能够在复杂环境中执行任务的机器人。该研究有助于提升机器人的自主性和适应性,使其能够更好地服务于人类生活。
📄 摘要(原文)
Vision-language-action models have advanced robotic manipulation but remain constrained by reliance on the large, teleoperation-collected datasets dominated by the static, tabletop scenes. We propose a simulation-first framework to verify VLA architectures before real-world deployment and introduce MobileManiBench, a large-scale benchmark for mobile-based robotic manipulation. Built on NVIDIA Isaac Sim and powered by reinforcement learning, our pipeline autonomously generates diverse manipulation trajectories with rich annotations (language instructions, multi-view RGB-depth-segmentation images, synchronized object/robot states and actions). MobileManiBench features 2 mobile platforms (parallel-gripper and dexterous-hand robots), 2 synchronized cameras (head and right wrist), 630 objects in 20 categories, 5 skills (open, close, pull, push, pick) with over 100 tasks performed in 100 realistic scenes, yielding 300K trajectories. This design enables controlled, scalable studies of robot embodiments, sensing modalities, and policy architectures, accelerating research on data efficiency and generalization. We benchmark representative VLA models and report insights into perception, reasoning, and control in complex simulated environments.