Capturing Visual Environment Structure Correlates with Control Performance
作者: Jiahua Dong, Yunze Man, Pavel Tokmakov, Yu-Xiong Wang
分类: cs.RO
发布日期: 2026-02-04
💡 一句话要点
通过环境状态解码评估视觉表征,提升机器人控制策略泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视觉表征学习 机器人控制 环境状态解码 策略泛化 代理指标
📋 核心要点
- 现有机器人策略评估方法依赖耗时的策略rollout,且代理指标关注视觉世界的狭窄方面,限制了泛化能力。
- 论文提出一种分析方法,通过探测视觉编码器解码环境状态的能力来评估表征质量,无需直接策略训练。
- 实验表明,该探测精度与下游策略性能高度相关,优于现有指标,并能有效选择合适的视觉表征。
📝 摘要(中文)
视觉表征的选择是扩展通用机器人策略的关键。然而,即使在模拟环境中,通过策略rollout直接评估的代价也很高。现有的代理指标侧重于表征捕捉视觉世界狭窄方面的能力,例如物体形状,限制了跨环境的泛化。本文采取了一种分析的角度:通过测量预训练视觉编码器从图像中解码环境状态(包括几何、物体结构和物理属性)的能力来探测它们。利用可以访问ground-truth状态的模拟环境,我们表明这种探测精度与跨不同环境和学习设置的下游策略性能密切相关,显著优于先前的指标,并实现了有效的表征选择。更广泛地说,我们的研究深入了解了支持可泛化操作的表征属性,表明学习编码环境的潜在物理状态是控制的一个有希望的目标。
🔬 方法详解
问题定义:现有机器人控制策略的视觉表征学习缺乏有效的评估方法。直接通过策略rollout评估计算成本高昂,即使在模拟环境中也是如此。现有的代理指标,例如关注物体形状等特定视觉属性,无法很好地泛化到不同的环境和任务中。因此,如何高效且准确地评估视觉表征的质量,并选择适合特定控制任务的表征,是一个亟待解决的问题。
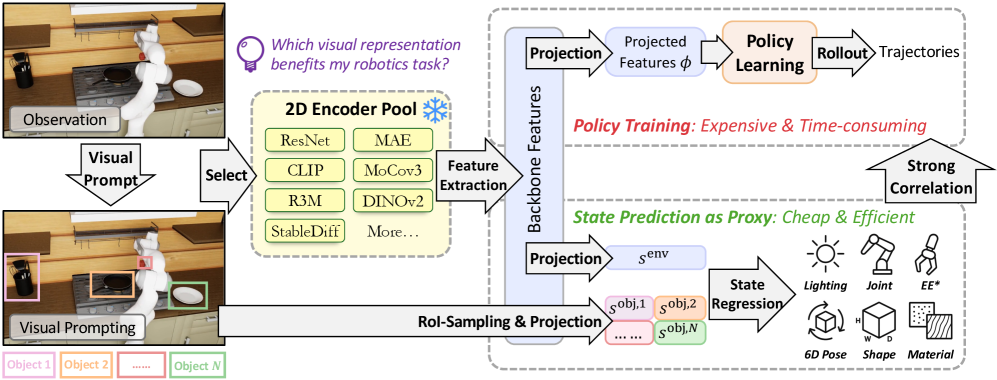
核心思路:本文的核心思路是,一个好的视觉表征应该能够有效地编码环境的状态信息,包括几何结构、物体属性和物理特性。因此,可以通过测量视觉编码器从图像中解码这些环境状态信息的能力来评估表征的质量。如果一个编码器能够准确地从图像中恢复环境状态,那么它就更有可能为下游的控制任务提供有用的信息,从而提高策略的性能。
技术框架:该方法主要包含以下几个步骤:1) 使用预训练的视觉编码器提取图像的视觉特征;2) 使用一个解码器,以视觉特征作为输入,预测环境的状态信息,例如物体的位置、姿态、质量等;3) 使用ground-truth的环境状态信息作为监督信号,训练解码器;4) 使用解码器的预测精度作为评估视觉表征质量的指标。整体流程是先用预训练模型提取特征,再训练一个解码器来预测环境状态,最后用解码器的精度来评估预训练模型的质量。
关键创新:该方法最重要的创新点在于,它提出了一种新的评估视觉表征质量的代理指标,即环境状态解码精度。与现有的代理指标相比,该指标更加全面地考虑了视觉表征所编码的信息,能够更好地反映表征对下游控制任务的适用性。此外,该方法避免了耗时的策略rollout,能够高效地评估大量的视觉表征。
关键设计:在实验中,使用了多种预训练的视觉编码器,例如ResNet、CLIP等。解码器通常是一个多层感知机(MLP),其输入是视觉特征,输出是环境状态的预测值。损失函数通常是均方误差(MSE),用于衡量预测值与ground-truth之间的差距。关键参数包括解码器的网络结构、学习率、训练轮数等。此外,还使用了数据增强等技术来提高解码器的泛化能力。
🖼️ 关键图片

📊 实验亮点
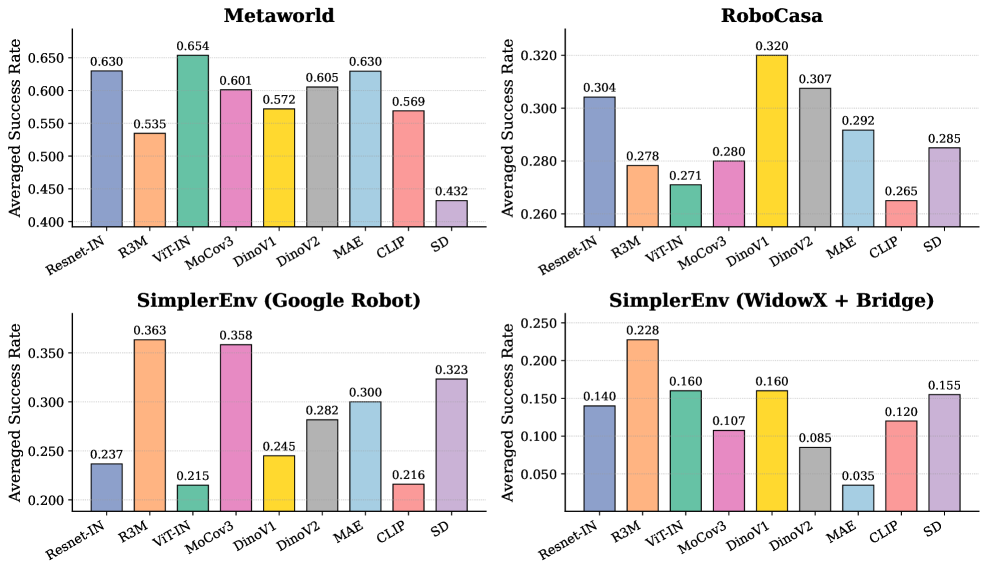
实验结果表明,本文提出的环境状态解码精度与下游策略性能具有很强的相关性,显著优于现有的代理指标。例如,在多个模拟环境中,使用该指标选择的视觉表征能够使策略的成功率提高10%-20%。此外,该方法还能够有效地区分不同的视觉表征,并选择出最适合特定控制任务的表征。
🎯 应用场景
该研究成果可应用于机器人通用策略学习、视觉表征选择和评估等领域。通过高效评估视觉表征,可以加速机器人策略的开发和部署,提高机器人在不同环境下的适应性和泛化能力。此外,该方法还可以用于指导视觉表征学习算法的设计,使其能够更好地编码环境状态信息,从而提升机器人控制性能。
📄 摘要(原文)
The choice of visual representation is key to scaling generalist robot policies. However, direct evaluation via policy rollouts is expensive, even in simulation. Existing proxy metrics focus on the representation's capacity to capture narrow aspects of the visual world, like object shape, limiting generalization across environments. In this paper, we take an analytical perspective: we probe pretrained visual encoders by measuring how well they support decoding of environment state -- including geometry, object structure, and physical attributes -- from images. Leveraging simulation environments with access to ground-truth state, we show that this probing accuracy strongly correlates with downstream policy performance across diverse environments and learning settings, significantly outperforming prior metrics and enabling efficient representation selection. More broadly, our study provides insight into the representational properties that support generalizable manipulation, suggesting that learning to encode the latent physical state of the environment is a promising objective for control.