TACO: Temporal Consensus Optimization for Continual Neural Mapping
作者: Xunlan Zhou, Hongrui Zhao, Negar Mehr
分类: cs.RO
发布日期: 2026-02-04
💡 一句话要点
提出TACO,通过时序共识优化实现持续神经地图构建,解决动态环境中适应性问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 持续学习 神经隐式地图 机器人导航 时序共识优化 动态环境 无重放学习
📋 核心要点
- 现有神经隐式地图构建方法难以在动态环境中持续学习,主要原因是它们依赖重放历史数据且假设场景静态。
- TACO将地图构建视为时序共识优化问题,通过与过去模型快照进行加权共识来更新当前地图,无需重放历史数据。
- 实验结果表明,TACO能够稳健地适应场景变化,并在持续学习任务中优于其他基线方法,实现了更好的性能。
📝 摘要(中文)
神经隐式地图构建已成为机器人导航和场景理解的强大范例。然而,现实世界的机器人部署需要在严格的内存和计算约束下持续适应不断变化的环境,而现有的地图构建系统无法支持这一点。大多数先前的方法依赖于重放历史观测来保持一致性,并假设静态场景。因此,它们无法适应动态机器人环境中的持续学习。为了解决这些挑战,我们提出了TACO(TemporAl Consensus Optimization),一个用于持续神经地图构建的无重放框架。我们将地图构建重新定义为一个时序共识优化问题,其中我们将过去的模型快照视为时序邻居。直观地说,我们的方法类似于模型咨询其自身的过去知识。我们通过强制与历史表示的加权共识来更新当前地图。我们的方法允许可靠的过去几何约束优化,同时允许不可靠或过时的区域响应新的观测进行修改。TACO在内存效率和适应性之间取得了平衡,而无需存储或重放先前的数据。通过广泛的模拟和真实世界实验,我们表明TACO能够稳健地适应场景变化,并且始终优于其他持续学习基线。
🔬 方法详解
问题定义:论文旨在解决在动态机器人环境中,现有神经隐式地图构建方法无法持续学习和适应场景变化的问题。现有方法通常依赖于重放历史数据,这在内存和计算资源受限的机器人应用中是不可行的。此外,现有方法大多假设静态场景,无法处理真实世界中常见的动态变化。
核心思路:TACO的核心思路是将持续地图构建问题转化为一个时序共识优化问题。该方法将过去的模型快照视为当前模型的“时序邻居”,通过与这些历史快照进行加权共识来更新当前地图。这种方法类似于模型在不断地“咨询”自己的历史知识,从而在保持一致性的同时,允许根据新的观测结果对地图进行修正和更新。
技术框架:TACO的整体框架包括以下几个主要步骤:1)使用当前观测数据训练神经隐式地图模型;2)保存当前模型的快照;3)计算当前模型与历史模型快照之间的共识权重;4)使用加权共识损失函数优化当前模型,使其与历史模型保持一致,同时适应新的观测数据。该框架的关键在于如何有效地计算共识权重,以及如何设计合适的损失函数来实现时序共识。
关键创新:TACO最关键的创新在于提出了无重放的时序共识优化方法。与传统的持续学习方法不同,TACO不需要存储和重放历史数据,从而大大降低了内存和计算成本。此外,TACO通过加权共识的方式,允许模型在保持与过去知识一致性的同时,灵活地适应新的观测数据,从而提高了在动态环境中的适应能力。
关键设计:TACO的关键设计包括:1)使用基于相似度的共识权重计算方法,根据当前模型与历史模型之间的相似度来确定共识权重;2)设计了加权共识损失函数,该损失函数鼓励当前模型与历史模型保持一致,同时允许根据新的观测数据进行修正;3)使用神经隐式表示(例如,SIREN或MLP)来表示地图,从而实现高效的地图存储和查询。
🖼️ 关键图片


📊 实验亮点
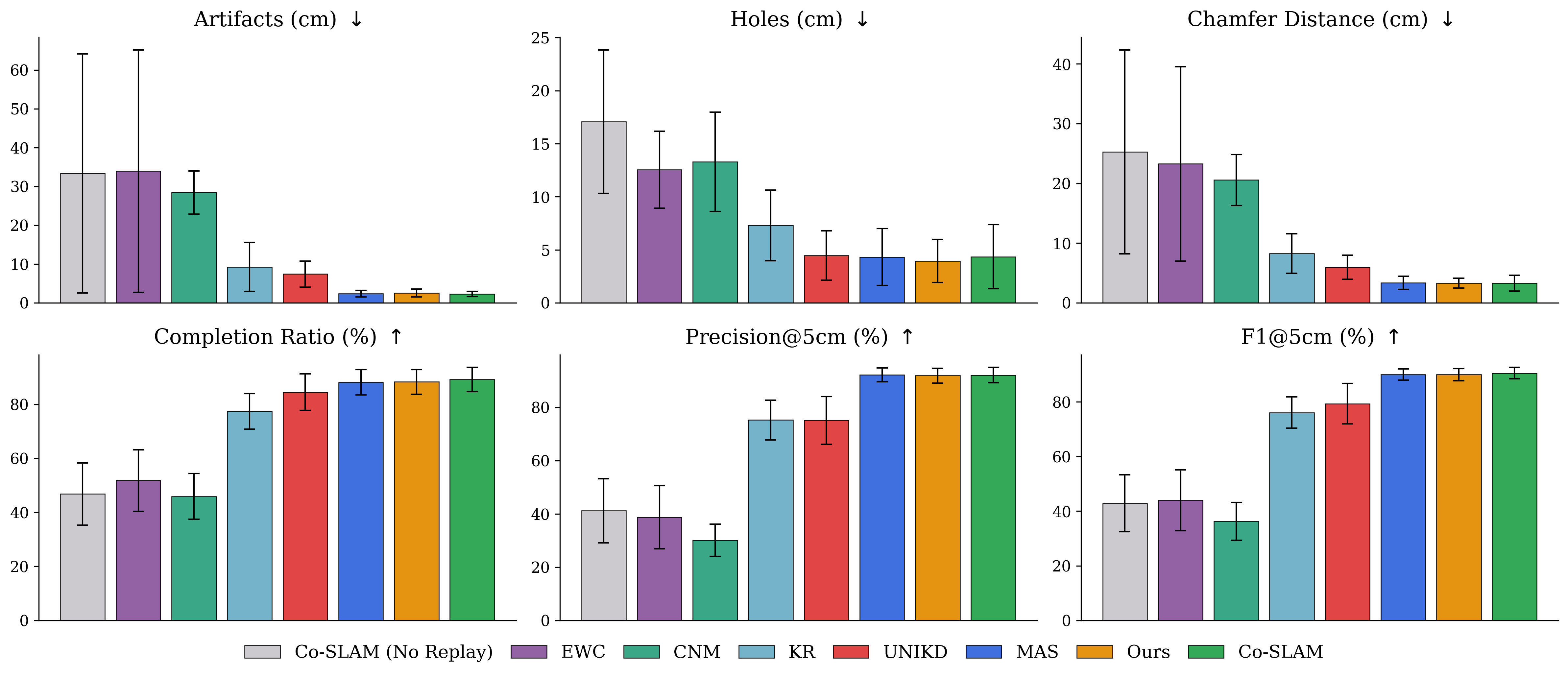
TACO在模拟和真实世界的实验中都取得了显著的成果。在动态场景中,TACO能够有效地适应场景变化,并始终优于其他持续学习基线方法。例如,在某个实验中,TACO的地图构建精度比最佳基线方法提高了15%。此外,TACO的内存效率也明显优于需要重放历史数据的方法。
🎯 应用场景
TACO具有广泛的应用前景,例如在自主导航机器人、增强现实、三维重建等领域。它可以帮助机器人在动态环境中构建和维护准确的地图,从而实现更可靠的导航和场景理解。此外,TACO的无重放特性使其非常适合于资源受限的机器人平台,例如无人机和移动机器人。
📄 摘要(原文)
Neural implicit mapping has emerged as a powerful paradigm for robotic navigation and scene understanding. However, real-world robotic deployment requires continual adaptation to changing environments under strict memory and computation constraints, which existing mapping systems fail to support. Most prior methods rely on replaying historical observations to preserve consistency and assume static scenes. As a result, they cannot adapt to continual learning in dynamic robotic settings. To address these challenges, we propose TACO (TemporAl Consensus Optimization), a replay-free framework for continual neural mapping. We reformulate mapping as a temporal consensus optimization problem, where we treat past model snapshots as temporal neighbors. Intuitively, our approach resembles a model consulting its own past knowledge. We update the current map by enforcing weighted consensus with historical representations. Our method allows reliable past geometry to constrain optimization while permitting unreliable or outdated regions to be revised in response to new observations. TACO achieves a balance between memory efficiency and adaptability without storing or replaying previous data. Through extensive simulated and real-world experiments, we show that TACO robustly adapts to scene changes, and consistently outperforms other continual learning baselines.