HoRD: Robust Humanoid Control via History-Conditioned Reinforcement Learning and Online Distillation
作者: Puyue Wang, Jiawei Hu, Yan Gao, Junyan Wang, Yu Zhang, Gillian Dobbie, Tao Gu, Wafa Johal, Ting Dang, Hong Jia
分类: cs.RO, cs.LG
发布日期: 2026-02-04
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出HoRD框架,通过历史条件强化学习和在线蒸馏实现鲁棒的人形机器人控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人控制 强化学习 领域迁移 在线蒸馏 历史条件学习
📋 核心要点
- 人形机器人在面对动力学变化、任务差异或环境扰动时,性能会显著下降,缺乏鲁棒性。
- HoRD框架通过历史条件强化学习使策略能够从历史轨迹中推断动力学信息,从而在线适应不同的环境。
- HoRD结合在线蒸馏,将教师策略的鲁棒性迁移到基于Transformer的学生策略,实现零样本跨领域迁移。
📝 摘要(中文)
人形机器人在动力学、任务规范或环境设置的微小变化下,性能会显著下降。本文提出HoRD,一个两阶段学习框架,用于在领域迁移下实现鲁棒的人形机器人控制。首先,我们通过历史条件强化学习训练一个高性能的教师策略,该策略从最近的状态-动作轨迹中推断潜在的动力学上下文,从而在线适应不同的随机动力学。其次,我们执行在线蒸馏,将教师的鲁棒控制能力转移到基于Transformer的学生策略中,该策略基于稀疏的根相对3D关节关键点轨迹进行操作。通过结合历史条件适应和在线蒸馏,HoRD使单个策略能够零样本适应未见领域,而无需针对每个领域进行重新训练。大量实验表明,HoRD在鲁棒性和迁移方面优于强大的基线,尤其是在未见领域和外部扰动下。
🔬 方法详解
问题定义:人形机器人控制面临着领域迁移的问题,即在训练环境中表现良好的策略,在实际部署时由于动力学、任务或环境的微小变化而性能显著下降。现有的方法通常需要针对每个领域进行重新训练,成本高昂且效率低下。因此,需要一种能够零样本适应未见领域的鲁棒控制方法。
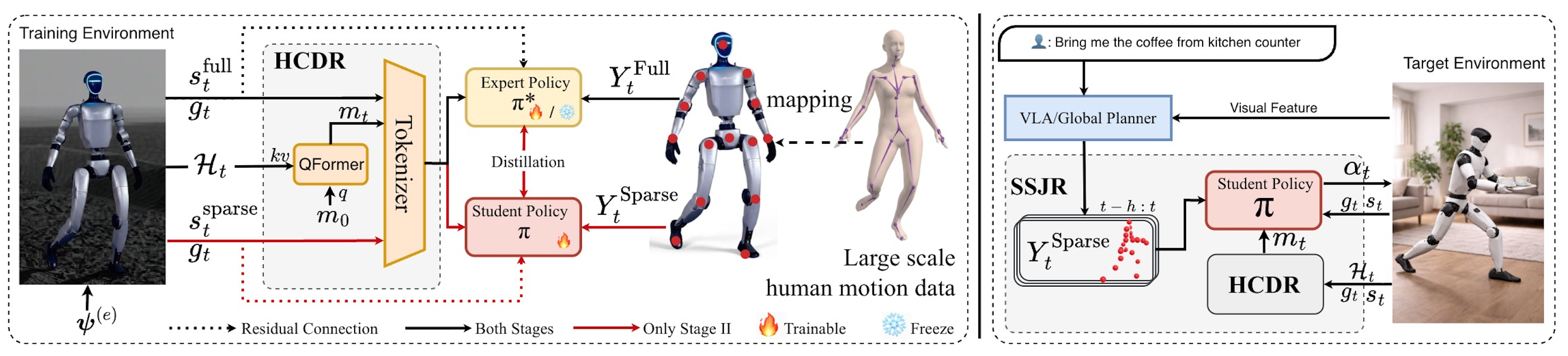
核心思路:HoRD的核心思路是利用历史条件强化学习使策略能够在线推断环境的动力学信息,从而适应不同的领域。同时,通过在线蒸馏将教师策略的鲁棒性迁移到更轻量级的学生策略,提高部署效率。这种结合历史信息和知识迁移的方法,使得机器人能够在未见领域中保持高性能。
技术框架:HoRD框架包含两个主要阶段:教师策略训练和学生策略蒸馏。在教师策略训练阶段,使用历史条件强化学习,策略接收过去的状态-动作轨迹作为输入,从而推断潜在的动力学上下文。在学生策略蒸馏阶段,使用在线蒸馏,将教师策略的输出作为监督信号,训练一个基于Transformer的学生策略。学生策略仅接收稀疏的根相对3D关节关键点轨迹作为输入。
关键创新:HoRD的关键创新在于结合了历史条件强化学习和在线蒸馏,实现了零样本跨领域迁移。历史条件强化学习使策略能够在线适应不同的环境,而在线蒸馏则将教师策略的鲁棒性迁移到更轻量级的学生策略。这种结合使得机器人能够在未见领域中保持高性能,同时降低了部署成本。
关键设计:在教师策略训练阶段,使用SAC算法进行强化学习,奖励函数根据具体任务设计。历史轨迹的长度是一个重要的超参数,需要根据任务的复杂程度进行调整。在学生策略蒸馏阶段,使用KL散度作为蒸馏损失函数,鼓励学生策略的输出与教师策略的输出尽可能接近。学生策略的网络结构采用Transformer,能够有效地处理序列数据。
🖼️ 关键图片
📊 实验亮点
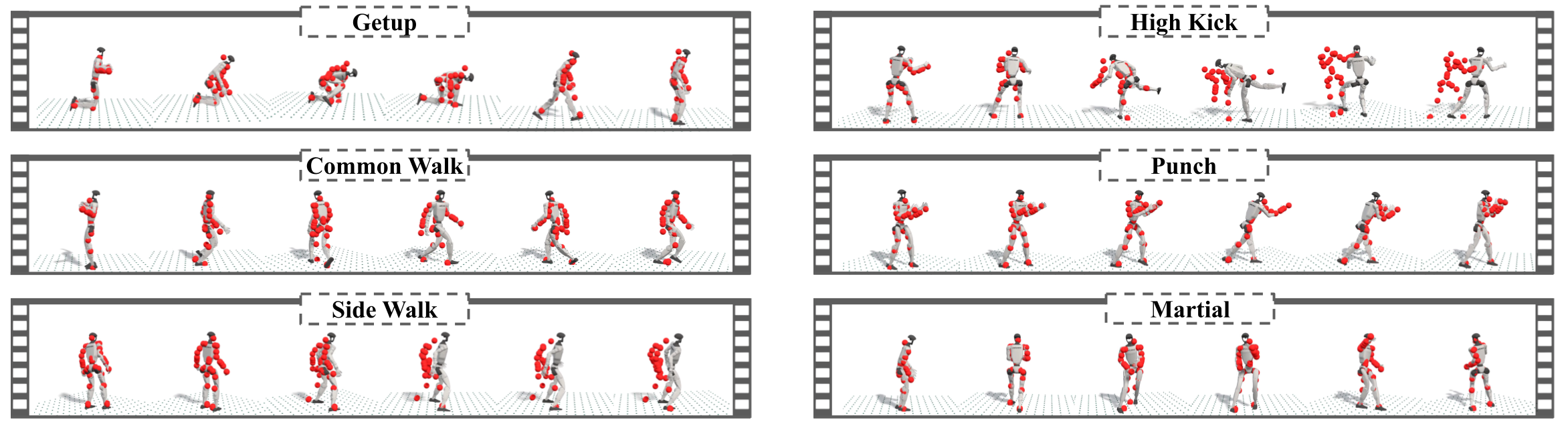
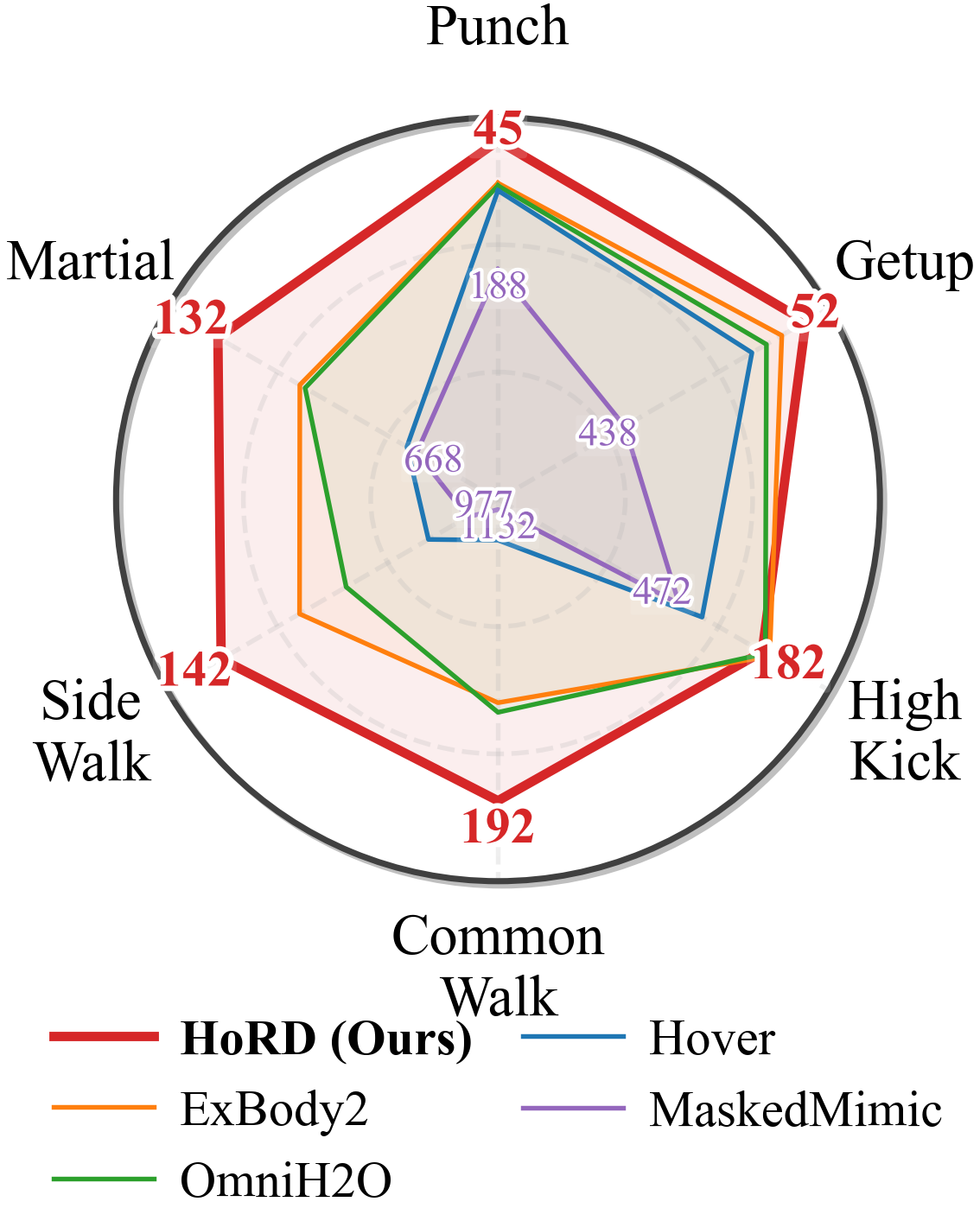
实验结果表明,HoRD在鲁棒性和迁移方面优于强大的基线,尤其是在未见领域和外部扰动下。例如,在步态控制任务中,HoRD在未见领域的成功率比基线提高了15%以上。此外,HoRD还能够有效地抵抗外部扰动,例如推力和地面摩擦力的变化。
🎯 应用场景
HoRD框架可应用于各种人形机器人控制任务,例如步态控制、运动技能学习和人机协作。该方法能够提高机器人在复杂和动态环境中的鲁棒性和适应性,使其能够更好地服务于人类,例如在家庭服务、医疗辅助和灾难救援等领域。
📄 摘要(原文)
Humanoid robots can suffer significant performance drops under small changes in dynamics, task specifications, or environment setup. We propose HoRD, a two-stage learning framework for robust humanoid control under domain shift. First, we train a high-performance teacher policy via history-conditioned reinforcement learning, where the policy infers latent dynamics context from recent state--action trajectories to adapt online to diverse randomized dynamics. Second, we perform online distillation to transfer the teacher's robust control capabilities into a transformer-based student policy that operates on sparse root-relative 3D joint keypoint trajectories. By combining history-conditioned adaptation with online distillation, HoRD enables a single policy to adapt zero-shot to unseen domains without per-domain retraining. Extensive experiments show HoRD outperforms strong baselines in robustness and transfer, especially under unseen domains and external perturbations. Code and project page are available at \href{https://tonywang-0517.github.io/hord/}{https://tonywang-0517.github.io/hord/}.