Viewpoint Matters: Dynamically Optimizing Viewpoints with Masked Autoencoder for Visual Manipulation
作者: Pengfei Yi, Yifan Han, Junyan Li, Litao Liu, Wenzhao Lian
分类: cs.RO
发布日期: 2026-02-04
备注: 5 pages, 2 figures, 3 tables
💡 一句话要点
提出MAE-Select,利用掩码自编码器动态优化机器人操作的视角选择。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 主动视角选择 掩码自编码器 单相机系统
📋 核心要点
- 现有模仿学习方法依赖固定相机,限制了机器人操作的适应性和覆盖范围。
- MAE-Select利用预训练掩码自编码器,动态选择信息量最大的视角,无需人工标注。
- 实验表明,MAE-Select提升了单相机系统的性能,甚至超越了多相机系统。
📝 摘要(中文)
机器人操作仍然是一个挑战,模仿学习(IL)使机器人能够从专家演示中学习任务。目前的IL方法通常依赖于固定的相机设置,相机被手动放置在静态位置,对适应性和覆盖范围造成了重大限制。受到人类主动感知的启发,人类会动态调整他们的视角以捕获最相关和最少噪声的信息,我们提出了MAE-Select,这是一种用于单相机机器人系统中主动视角选择的新框架。MAE-Select充分利用了预训练的多视角掩码自编码器表示,并在每个时间块动态选择下一个最具信息量的视角,而无需标记的视角。大量的实验表明,MAE-Select提高了单相机系统的能力,在某些情况下,甚至超过了多相机设置。
🔬 方法详解
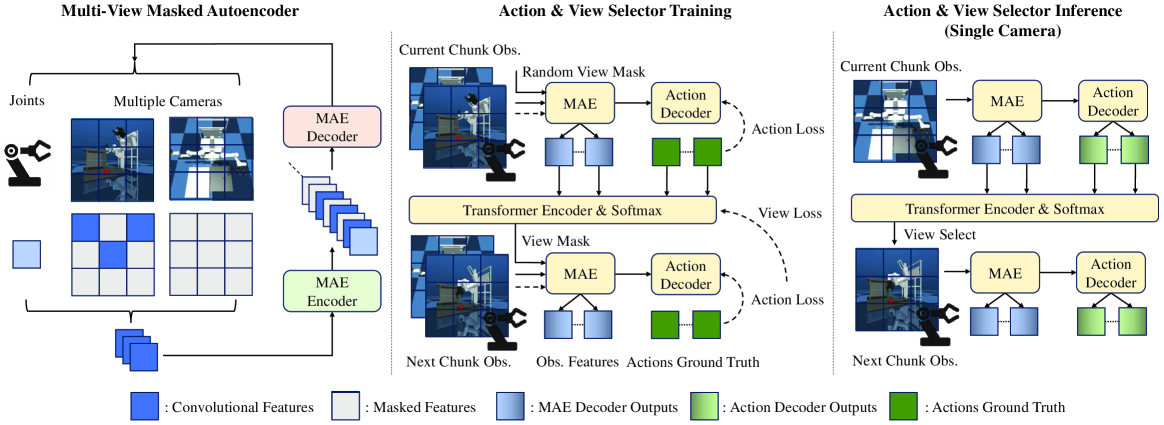
问题定义:论文旨在解决单相机机器人操作中视角选择的问题。现有方法通常采用固定相机位置,这限制了机器人对不同场景的适应性,并且可能无法捕捉到操作过程中的关键信息。因此,如何动态地选择最佳视角,以提高机器人操作的性能,是本文要解决的核心问题。
核心思路:论文的核心思路是模仿人类的主动感知机制,即通过动态调整视角来获取最相关的信息。具体而言,利用预训练的掩码自编码器(MAE)提取多视角图像的特征表示,并基于这些特征选择下一个最具信息量的视角。这种方法无需人工标注视角,而是通过自监督学习的方式学习视角的选择策略。
技术框架:MAE-Select框架主要包含以下几个模块:1) 多视角图像采集模块:从不同的视角采集机器人操作过程中的图像。2) 掩码自编码器(MAE)特征提取模块:利用预训练的MAE提取多视角图像的特征表示。3) 视角选择模块:基于MAE提取的特征,选择下一个最具信息量的视角。4) 机器人操作模块:根据选择的视角,控制机器人执行相应的操作。整个流程是一个循环迭代的过程,不断地选择最佳视角,并执行相应的操作。
关键创新:该论文的关键创新在于将预训练的掩码自编码器应用于机器人操作的视角选择问题。与传统的基于人工标注的视角选择方法不同,MAE-Select通过自监督学习的方式学习视角的选择策略,无需人工干预。此外,MAE-Select能够动态地选择视角,从而更好地适应不同的场景和操作任务。
关键设计:在MAE-Select框架中,一个关键的设计是使用预训练的MAE作为特征提取器。MAE通过掩码部分图像并预测被掩盖的部分,从而学习到图像的鲁棒特征表示。在视角选择模块中,可以使用不同的策略来选择下一个视角,例如,选择信息熵最大的视角,或者选择与当前视角差异最大的视角。损失函数的设计也至关重要,需要能够引导模型学习到有效的视角选择策略。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MAE-Select在单相机机器人操作任务中取得了显著的性能提升。在某些情况下,MAE-Select甚至超越了多相机系统的性能。具体的性能数据和对比基线需要在论文中查找。该研究证明了动态视角选择对于提高机器人操作性能的重要性,并为未来的研究提供了新的思路。
🎯 应用场景
MAE-Select具有广泛的应用前景,例如,可应用于工业自动化、医疗机器人、家庭服务机器人等领域。通过动态选择最佳视角,可以提高机器人在复杂环境中的操作能力和鲁棒性。此外,该方法还可以应用于其他需要主动感知的任务,例如,目标跟踪、三维重建等。未来,MAE-Select有望成为机器人操作领域的一项关键技术。
📄 摘要(原文)
Robotic manipulation continues to be a challenge, and imitation learning (IL) enables robots to learn tasks from expert demonstrations. Current IL methods typically rely on fixed camera setups, where cameras are manually positioned in static locations, imposing significant limitations on adaptability and coverage. Inspired by human active perception, where humans dynamically adjust their viewpoint to capture the most relevant and least noisy information, we propose MAE-Select, a novel framework for active viewpoint selection in single-camera robotic systems. MAE-Select fully leverages pre-trained multi-view masked autoencoder representations and dynamically selects the next most informative viewpoint at each time chunk without requiring labeled viewpoints. Extensive experiments demonstrate that MAE-Select improves the capabilities of single-camera systems and, in some cases, even surpasses multi-camera setups. The project will be available at https://mae-select.github.io.