GeoLanG: Geometry-Aware Language-Guided Grasping with Unified RGB-D Multimodal Learning
作者: Rui Tang, Guankun Wang, Long Bai, Huxin Gao, Jiewen Lai, Chi Kit Ng, Jiazheng Wang, Fan Zhang, Hongliang Ren
分类: cs.RO
发布日期: 2026-02-04
备注: IEEE ICRA 2025
💡 一句话要点
GeoLanG:提出几何感知语言引导抓取框架,解决复杂场景下的多模态机器人操作问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言引导抓取 多模态融合 深度学习 机器人操作 几何感知 CLIP 端到端学习
📋 核心要点
- 现有语言引导抓取方法依赖多阶段流程,导致跨模态融合有限,计算冗余,且在复杂场景泛化性差。
- GeoLanG通过CLIP架构统一视觉和语言输入,利用深度信息增强几何感知,并自适应融合多层特征。
- 实验表明,GeoLanG在复杂环境中实现了精确和鲁棒的语言引导抓取,提升了多模态机器人操作的可靠性。
📝 摘要(中文)
本文提出GeoLanG,一个端到端的多任务框架,基于CLIP架构,将视觉和语言输入统一到共享表示空间,以实现鲁棒的语义对齐和更好的泛化能力,从而解决复杂或遮挡场景下的语言引导抓取问题。为了增强在遮挡和低纹理条件下的目标区分能力,本文探索了一种更有效地利用深度信息的方法,即深度引导几何模块(DGGM),它将深度转换为显式的几何先验,并将其注入到注意力机制中,而无需额外的计算开销。此外,本文还提出了自适应密集通道集成,自适应地平衡多层特征的贡献,以产生更具区分性和泛化性的视觉表示。在OCID-VLG数据集以及模拟和真实世界的硬件上的大量实验表明,GeoLanG能够在复杂的、混乱的环境中实现精确和鲁棒的语言引导抓取,为现实世界中以人为中心的更可靠的多模态机器人操作铺平了道路。
🔬 方法详解
问题定义:现有语言引导抓取方法通常采用多阶段pipeline,将物体感知和抓取分离,导致跨模态信息融合不充分,计算冗余,并且在复杂、遮挡或低纹理场景下泛化能力较差。因此,需要一个能够端到端学习,有效融合多模态信息,并且对复杂场景具有鲁棒性的抓取框架。
核心思路:GeoLanG的核心思路是将视觉和语言信息统一到一个共享的表示空间中,利用深度信息增强几何感知能力,并通过自适应的方式融合多层特征,从而提高在复杂场景下的抓取精度和鲁棒性。这种端到端的学习方式能够更好地利用跨模态信息,避免了多阶段pipeline带来的信息损失。
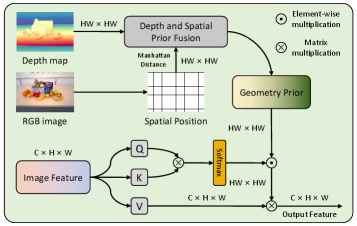
技术框架:GeoLanG是一个端到端的多任务框架,基于CLIP架构。它包含以下主要模块:1) 视觉编码器:用于提取RGB-D图像的视觉特征;2) 语言编码器:用于提取语言指令的语义特征;3) 深度引导几何模块(DGGM):将深度信息转换为几何先验,并注入到视觉特征中;4) 自适应密集通道集成:自适应地融合多层视觉特征;5) 抓取预测模块:基于融合后的视觉和语言特征,预测抓取姿态。
关键创新:GeoLanG的关键创新在于:1) 端到端的多模态融合:将视觉和语言信息统一到共享表示空间,避免了多阶段pipeline的信息损失;2) 深度引导几何模块(DGGM):利用深度信息增强几何感知能力,提高在遮挡和低纹理场景下的目标区分能力;3) 自适应密集通道集成:自适应地融合多层视觉特征,提高视觉表示的区分性和泛化性。
关键设计:DGGM将深度图转换为点云,并计算每个点的法向量和曲率,作为几何先验信息。这些几何先验信息通过注意力机制注入到视觉特征中。自适应密集通道集成使用可学习的权重来平衡不同层特征的贡献。损失函数包括抓取分类损失和抓取回归损失,用于优化抓取姿态的预测。
🖼️ 关键图片


📊 实验亮点
GeoLanG在OCID-VLG数据集上取得了显著的性能提升,超过了现有的基线方法。在模拟和真实世界的硬件实验中,GeoLanG也表现出良好的鲁棒性和泛化能力,能够在复杂的、混乱的环境中实现精确和鲁棒的语言引导抓取。具体性能数据未知,但实验结果表明GeoLanG在复杂场景下的抓取成功率明显高于现有方法。
🎯 应用场景
GeoLanG在机器人操作领域具有广泛的应用前景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。它可以使机器人能够理解人类的语言指令,并在复杂的环境中执行抓取任务,从而提高机器人的智能化水平和工作效率。该研究对于实现更可靠、更智能的人机协作具有重要意义。
📄 摘要(原文)
Language-guided grasping has emerged as a promising paradigm for enabling robots to identify and manipulate target objects through natural language instructions, yet it remains highly challenging in cluttered or occluded scenes. Existing methods often rely on multi-stage pipelines that separate object perception and grasping, which leads to limited cross-modal fusion, redundant computation, and poor generalization in cluttered, occluded, or low-texture scenes. To address these limitations, we propose GeoLanG, an end-to-end multi-task framework built upon the CLIP architecture that unifies visual and linguistic inputs into a shared representation space for robust semantic alignment and improved generalization. To enhance target discrimination under occlusion and low-texture conditions, we explore a more effective use of depth information through the Depth-guided Geometric Module (DGGM), which converts depth into explicit geometric priors and injects them into the attention mechanism without additional computational overhead. In addition, we propose Adaptive Dense Channel Integration, which adaptively balances the contributions of multi-layer features to produce more discriminative and generalizable visual representations. Extensive experiments on the OCID-VLG dataset, as well as in both simulation and real-world hardware, demonstrate that GeoLanG enables precise and robust language-guided grasping in complex, cluttered environments, paving the way toward more reliable multimodal robotic manipulation in real-world human-centric settings.