Reshaping Action Error Distributions for Reliable Vision-Language-Action Models
作者: Shuanghao Bai, Dakai Wang, Cheng Chi, Wanqi Zhou, Jing Lyu, Xiaoguang Zhao, Pengwei Wang, Zhongyuan Wang, Lei Xing, Shanghang Zhang, Badong Chen
分类: cs.RO
发布日期: 2026-02-04
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
针对连续动作VLA模型,提出基于最小误差熵的训练方法,提升泛化性和鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 最小误差熵 连续动作控制 模仿学习
📋 核心要点
- 现有VLA模型依赖MSE损失,对每个动作预测施加过强约束,忽略了动作误差分布的整体信息。
- 提出基于最小误差熵(MEE)的训练方法,重塑动作误差分布,提升模型的泛化能力和鲁棒性。
- 实验表明,该方法在模拟和真实机器人任务中,均能显著提升VLA模型的成功率和鲁棒性。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为学习通用且可扩展机器人策略的一种有前景的范例。现有VLA框架主要依赖于标准监督目标,如离散动作的交叉熵和连续动作回归的均方误差(MSE),这些方法对单个预测施加了强烈的逐点约束。本文关注连续动作VLA模型,通过在训练期间重塑动作误差分布,超越了传统的基于MSE的回归。借鉴信息论原理,我们将最小误差熵(MEE)引入现代VLA架构,并提出了轨迹级别的MEE目标,以及两个加权变体,与MSE结合用于连续动作VLA训练。我们在LIBERO和SimplerEnv等模拟基准以及真实机器人操作任务上,在标准、少样本和噪声设置中评估了我们的方法在多个代表性VLA架构上的表现。实验结果表明,在这些设置中,成功率和鲁棒性均得到了持续提高。在不平衡数据情况下,增益在良好表征的工作范围内持续存在,同时产生可忽略不计的额外训练成本,并且不影响推理效率。我们进一步提供了理论分析,解释了为什么基于MEE的监督是有效的,并描述了它的实际范围。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型,特别是针对连续动作控制的模型,通常使用均方误差(MSE)作为损失函数进行训练。这种方法假设动作误差服从高斯分布,并对每个动作的预测进行逐点约束。然而,实际的机器人操作任务中,动作误差的分布可能更加复杂,例如存在多峰或偏斜的情况。MSE损失对异常值敏感,并且无法充分利用动作误差分布的整体信息,导致模型泛化能力受限,在噪声环境下的鲁棒性较差。
核心思路:本文的核心思路是利用最小误差熵(Minimum Error Entropy, MEE)准则来优化VLA模型。MEE旨在最小化误差分布的熵,从而使误差分布更加集中和均匀。与MSE不同,MEE关注的是误差分布的整体形状,而不是单个误差的大小。通过最小化误差熵,可以使模型对噪声和异常值更加鲁棒,并提高模型的泛化能力。此外,本文还提出了轨迹级别的MEE目标,考虑了动作序列之间的相关性,进一步提升了模型的性能。
技术框架:该方法的技术框架主要包括以下几个部分:1) VLA模型:使用现有的VLA架构,例如基于Transformer的模型或基于CNN的模型。2) 动作误差计算:计算模型预测的动作与真实动作之间的误差。3) 误差熵估计:使用Parzen窗估计或其他方法来估计动作误差分布的熵。4) 损失函数:将MEE损失与MSE损失结合,形成最终的损失函数。5) 优化器:使用Adam或其他优化器来训练VLA模型。
关键创新:该论文的关键创新在于将最小误差熵(MEE)准则引入到连续动作VLA模型的训练中。与传统的MSE损失相比,MEE能够更好地处理复杂的动作误差分布,提高模型的泛化能力和鲁棒性。此外,轨迹级别的MEE目标考虑了动作序列之间的相关性,进一步提升了模型的性能。
关键设计:在具体实现上,论文提出了两种加权的MEE变体,用于平衡MEE损失和MSE损失之间的权重。MEE损失的计算使用了Parzen窗估计,其中核函数的带宽是一个重要的参数。论文通过实验分析了带宽参数对模型性能的影响,并给出了合理的参数选择范围。此外,论文还研究了在不平衡数据情况下,MEE损失的有效性,并给出了相应的建议。
🖼️ 关键图片


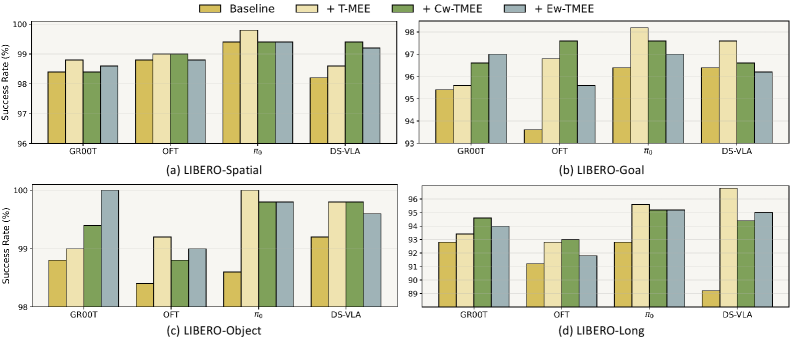
📊 实验亮点
实验结果表明,在LIBERO和SimplerEnv等模拟基准以及真实机器人操作任务上,该方法在标准、少样本和噪声设置中,均能显著提升VLA模型的成功率和鲁棒性。例如,在某些任务中,成功率提升了5%以上。此外,该方法在不平衡数据情况下仍然有效,并且不会增加额外的训练成本和推理时间。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过提高VLA模型的泛化能力和鲁棒性,可以使机器人更好地适应复杂和不确定的环境,从而实现更高效、更可靠的自动化操作。此外,该方法还可以应用于其他连续动作控制任务,例如自动驾驶、游戏AI等。
📄 摘要(原文)
In robotic manipulation, vision-language-action (VLA) models have emerged as a promising paradigm for learning generalizable and scalable robot policies. Most existing VLA frameworks rely on standard supervised objectives, typically cross-entropy for discrete actions and mean squared error (MSE) for continuous action regression, which impose strong pointwise constraints on individual predictions. In this work, we focus on continuous-action VLA models and move beyond conventional MSE-based regression by reshaping action error distributions during training. Drawing on information-theoretic principles, we introduce Minimum Error Entropy (MEE) into modern VLA architectures and propose a trajectory-level MEE objective, together with two weighted variants, combined with MSE for continuous-action VLA training. We evaluate our approaches across standard, few-shot, and noisy settings on multiple representative VLA architectures, using simulation benchmarks such as LIBERO and SimplerEnv as well as real-world robotic manipulation tasks. Experimental results demonstrate consistent improvements in success rates and robustness across these settings. Under imbalanced data regimes, the gains persist within a well-characterized operating range, while incurring negligible additional training cost and no impact on inference efficiency. We further provide theoretical analyses that explain why MEE-based supervision is effective and characterize its practical range. Project Page: https://cognition2actionlab.github.io/VLA-TMEE.github.io/