A Modern System Recipe for Situated Embodied Human-Robot Conversation with Real-Time Multimodal LLMs and Tool-Calling
作者: Dong Won Lee, Sarah Gillet, Louis-Philippe Morency, Cynthia Breazeal, Hae Won Park
分类: cs.RO
发布日期: 2026-02-04
备注: 9 pages, 7 figures
💡 一句话要点
提出基于实时多模态LLM和工具调用的具身人机对话系统
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身对话 人机交互 多模态学习 大型语言模型 主动感知
📋 核心要点
- 现有具身对话系统难以在低延迟约束下进行实时多模态感知和决策。
- 提出一种基于实时多模态LLM和工具调用的极简系统方案,实现主动感知。
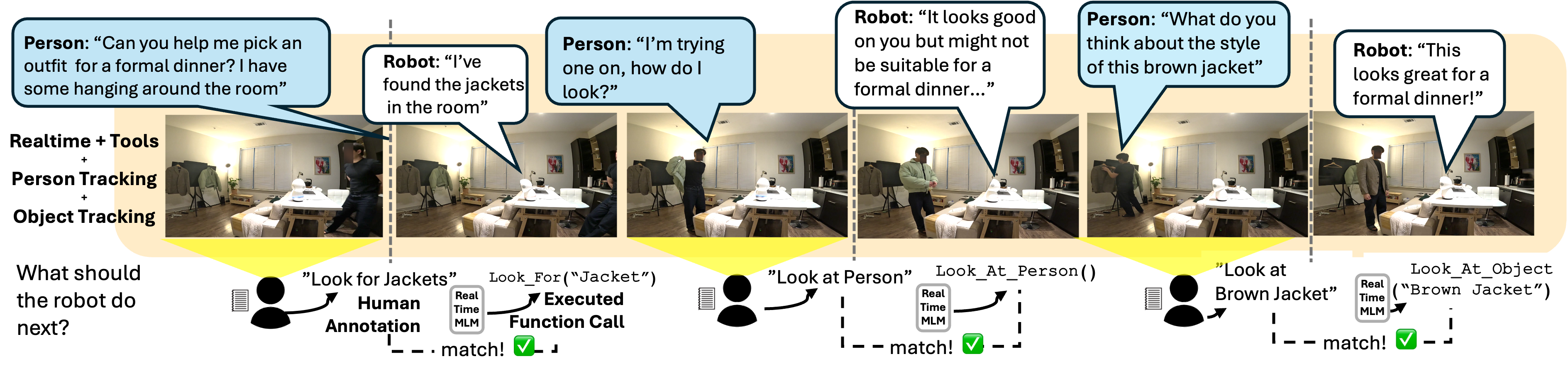
- 实验表明,该方案在家庭场景中能有效进行注意力转移和感知,交互质量良好。
📝 摘要(中文)
具身情境对话要求机器人将实时对话与主动感知交织在一起:在严格的延迟约束下,决定看什么、何时看以及说什么。我们提出了一个简单、最小化的系统方案,将实时多模态语言模型与用于注意力和主动感知的一小组工具接口配对。我们研究了六个家庭式场景,这些场景需要频繁的注意力转移和不断扩展的感知范围。在四个系统变体中,我们根据人工标注评估了turn-level工具决策的正确性,并收集了交互质量的主观评分。结果表明,实时多模态大型语言模型和用于主动感知的工具使用是实际具身情境对话的一个有希望的方向。
🔬 方法详解
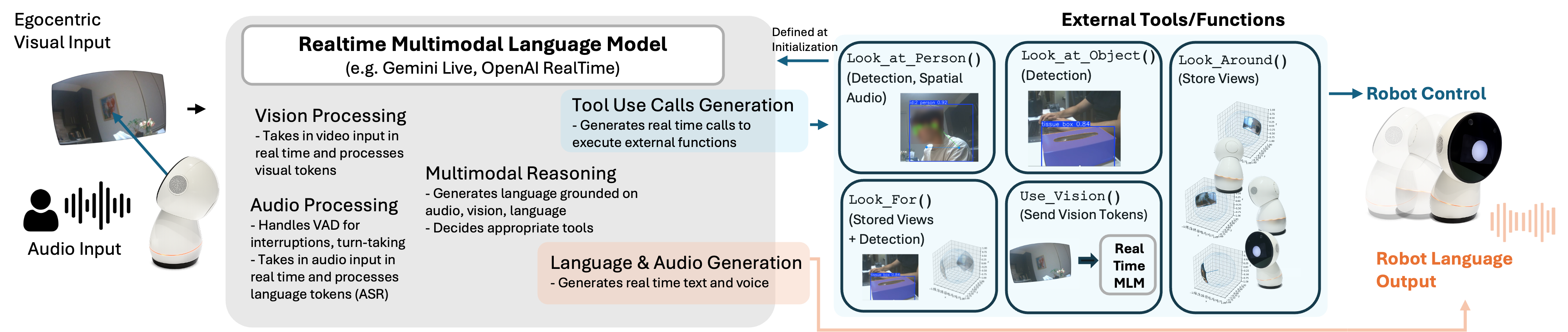
问题定义:现有具身人机对话系统难以在实时性要求高的情境下,有效地进行多模态信息处理和主动感知决策。痛点在于如何在有限的计算资源和时间约束下,让机器人能够根据对话内容和环境信息,动态地调整感知策略,例如决定关注哪些物体、何时进行观察等。
核心思路:论文的核心思路是将大型语言模型(LLM)作为对话和决策的核心,并引入一组工具接口,用于控制机器人的注意力和感知行为。通过LLM的推理能力,根据对话历史和当前环境信息,选择合适的工具来执行感知任务,从而实现主动感知和情境理解。
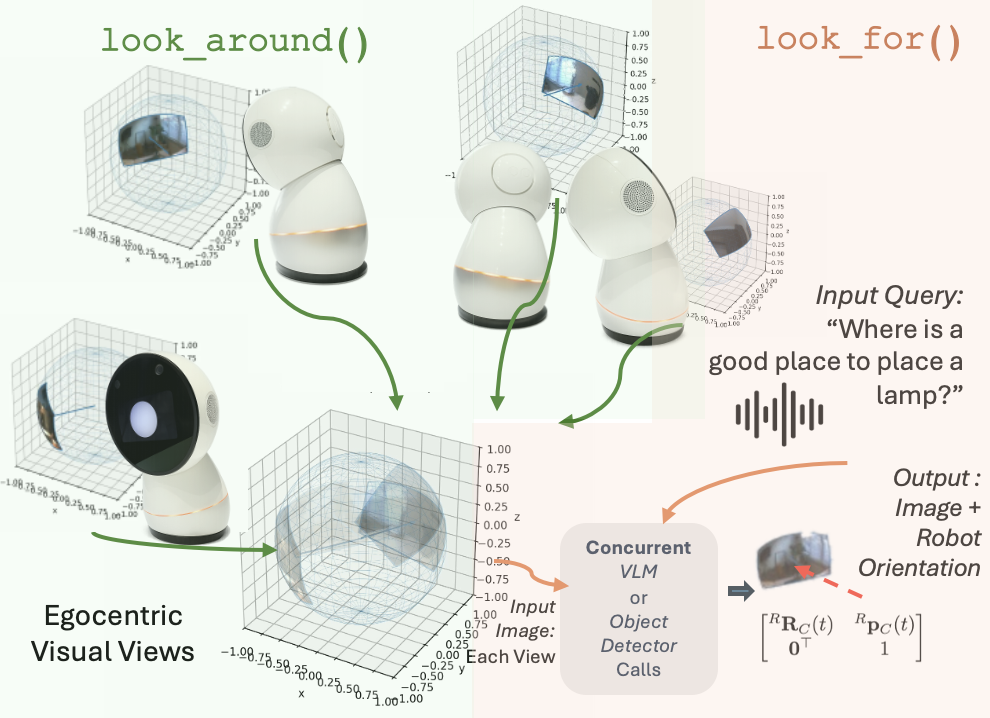
技术框架:该系统主要包含以下几个模块:1) 实时多模态LLM:负责对话管理、意图理解和工具选择;2) 工具接口:提供控制机器人注意力(例如,控制摄像头方向)和执行感知任务(例如,物体识别)的功能;3) 感知模块:负责从传感器数据中提取环境信息,例如图像、声音等。整个流程是:用户输入对话,LLM根据对话历史和感知信息,决定调用哪个工具,工具执行后返回结果,LLM再根据结果生成回复。
关键创新:该论文的关键创新在于将LLM与工具调用机制相结合,实现了一种轻量级的、可扩展的具身对话系统。与传统的端到端方法相比,该方法更易于模块化和维护,并且可以灵活地添加新的工具和感知能力。此外,该系统强调实时性,能够在低延迟约束下进行对话和感知。
关键设计:论文中使用了特定的LLM模型(具体型号未知),并设计了一组针对具身对话场景的工具接口,例如用于控制摄像头方向的工具、用于物体识别的工具等。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该系统在家庭场景中能够有效地进行注意力转移和感知,并且交互质量良好。通过对比不同的系统变体,验证了实时多模态LLM和工具调用机制的有效性。具体的性能数据(例如,工具决策的正确率、交互质量的评分)在摘要中没有给出,属于未知信息。
🎯 应用场景
该研究成果可应用于智能家居、服务机器人、辅助生活等领域。例如,机器人可以根据用户的指令和环境信息,主动识别物体、提供导航、执行任务等。未来,该技术有望提升人机交互的自然性和智能化水平,使机器人更好地融入人类生活。
📄 摘要(原文)
Situated embodied conversation requires robots to interleave real-time dialogue with active perception: deciding what to look at, when to look, and what to say under tight latency constraints. We present a simple, minimal system recipe that pairs a real-time multimodal language model with a small set of tool interfaces for attention and active perception. We study six home-style scenarios that require frequent attention shifts and increasing perceptual scope. Across four system variants, we evaluate turn-level tool-decision correctness against human annotations and collect subjective ratings of interaction quality. Results indicate that real-time multimodal large language models and tool use for active perception is a promising direction for practical situated embodied conversation.