A Scene Graph Backed Approach to Open Set Semantic Mapping
作者: Martin Günther, Felix Igelbrink, Oscar Lima, Lennart Niecksch, Marian Renz, Martin Atzmueller
分类: cs.RO
发布日期: 2026-02-03
💡 一句话要点
提出基于场景图的开放集语义地图构建方法,提升机器人环境感知能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语义地图构建 场景图 机器人感知 开放集识别 增量学习
📋 核心要点
- 现有语义地图构建方法通常将感知与表示分离,导致场景图缺乏一致性和可扩展性,难以支持高层推理。
- 该论文提出以3D语义场景图为核心的地图构建架构,实时更新图结构,保证拓扑一致性和计算效率。
- 通过显式的空间表示,该方法连接了底层传感器数据和高层符号推理,为知识驱动框架提供稳定结构。
📝 摘要(中文)
本文提出了一种基于场景图的开放集语义地图构建方法,旨在解决大规模真实环境中机器人高层推理的挑战。与现有方法将场景图视为后验生成的衍生层不同,该方法将3D语义场景图(3DSSG)作为基础后端,作为整个地图构建过程的主要知识表示。该方法利用增量场景图预测来实时推断和更新图结构,确保地图在长时间运行和大规模环境中保持拓扑一致性和计算效率。通过维护显式的、空间接地的表示,支持扁平化和分层拓扑,弥合了亚符号原始传感器数据和高层符号推理之间的差距,为知识驱动框架(如知识图谱、本体和大型语言模型)提供了一个稳定、可验证的结构,从而增强了智能体的可解释性、可信度和与人类概念的对齐。
🔬 方法详解
问题定义:现有开放集语义地图构建方法通常将感知和表示分离,场景图作为后处理步骤生成,导致地图缺乏全局一致性,难以有效支持机器人的高层推理和决策,尤其是在大规模、动态的环境中。此外,现有方法难以有效利用先验知识,限制了对未知环境的适应能力。
核心思路:该论文的核心思路是将3D语义场景图(3DSSG)作为整个地图构建流程的中心,而非仅仅是后处理的产物。通过将场景图作为知识表示的后端,可以实现感知和表示的紧密耦合,从而保证地图的拓扑一致性和语义完整性。这种设计允许系统在探索环境的同时,实时更新和完善场景图,从而更好地支持高层推理。
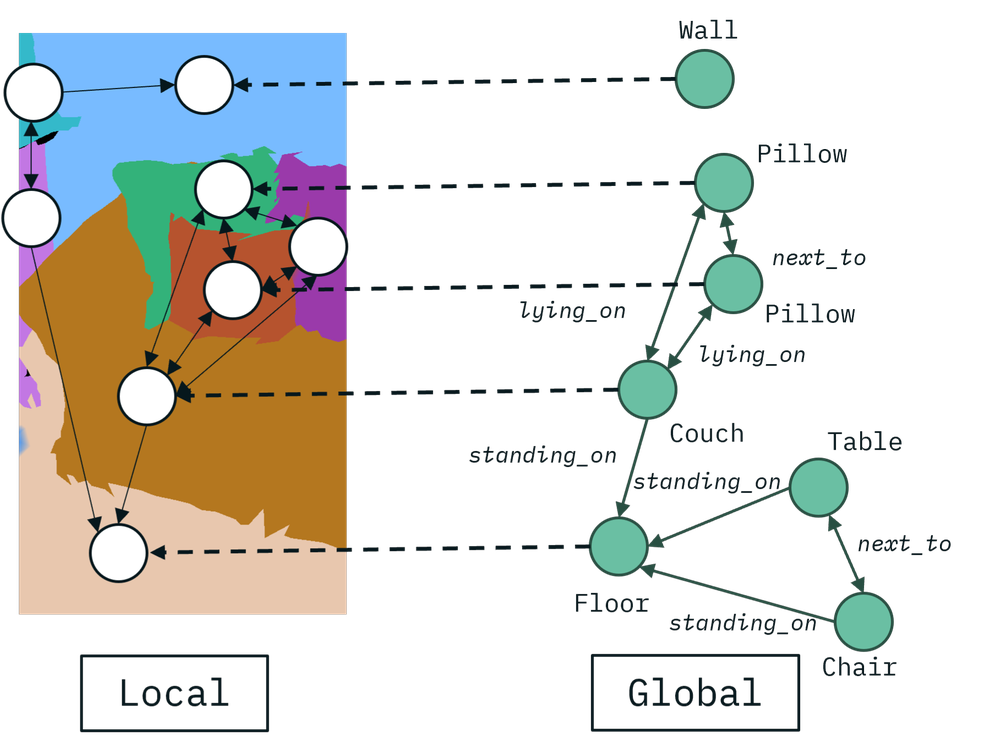
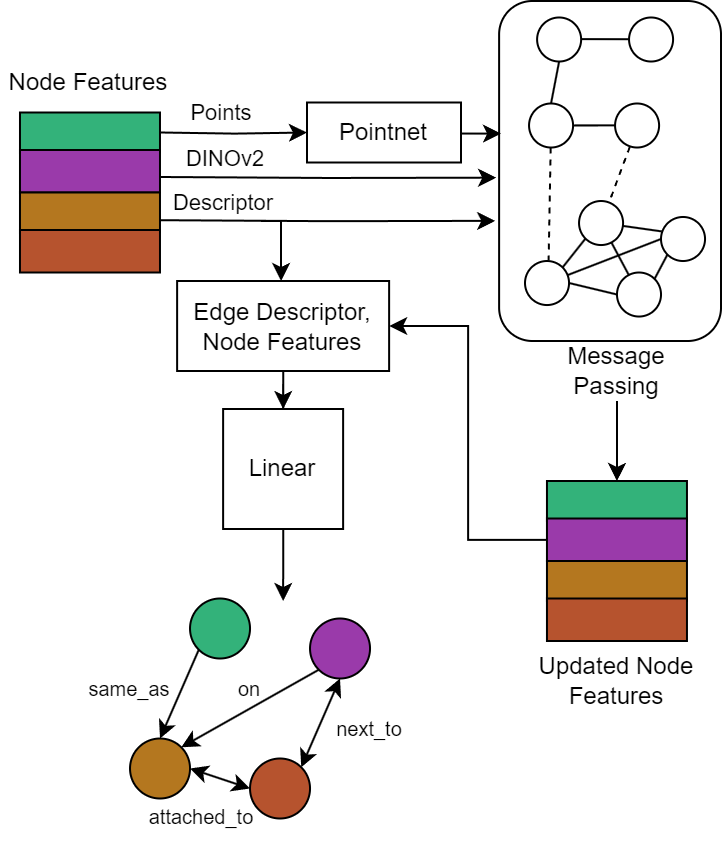
技术框架:该方法采用增量式场景图预测框架,主要包含以下几个模块:1) 数据采集模块:通过传感器(如RGB-D相机、激光雷达)获取环境数据。2) 场景图预测模块:利用增量式场景图预测算法,根据传感器数据实时推断和更新场景图的结构和属性。3) 地图维护模块:负责维护场景图的拓扑一致性和空间一致性,包括节点和边的增删改查。4) 高层推理接口:提供与知识图谱、本体或大型语言模型的接口,支持基于场景图的高层推理和决策。
关键创新:该方法最重要的创新在于将场景图作为地图构建的后端,实现了感知和表示的紧密集成。与传统方法相比,这种架构能够更好地利用先验知识,提高地图构建的效率和准确性。此外,该方法还支持扁平化和分层拓扑结构,能够灵活地表示不同尺度的环境信息。
关键设计:该方法采用增量式场景图预测算法,通过维护一个概率图模型来表示场景图的结构和属性。该模型可以根据新的传感器数据进行实时更新,从而保证地图的动态性和适应性。此外,该方法还设计了一套损失函数,用于优化场景图的结构和属性,包括拓扑一致性损失、语义一致性损失和空间一致性损失。
🖼️ 关键图片

📊 实验亮点
论文重点在于架构设计和概念验证,没有提供具体的性能数据。但其核心贡献在于提出了一种新的地图构建范式,强调场景图作为知识表示后端的重要性,为后续研究提供了新的思路。通过将场景图与知识图谱、大型语言模型等结合,有望实现更高级别的机器人智能。
🎯 应用场景
该研究成果可应用于机器人导航、环境监控、智能家居、自动驾驶等领域。通过构建具有语义信息的地图,机器人可以更好地理解周围环境,从而实现更智能、更可靠的自主行为。此外,该方法还可以为虚拟现实、增强现实等应用提供更真实、更丰富的场景表示。
📄 摘要(原文)
While Open Set Semantic Mapping and 3D Semantic Scene Graphs (3DSSGs) are established paradigms in robotic perception, deploying them effectively to support high-level reasoning in large-scale, real-world environments remains a significant challenge. Most existing approaches decouple perception from representation, treating the scene graph as a derivative layer generated post hoc. This limits both consistency and scalability. In contrast, we propose a mapping architecture where the 3DSSG serves as the foundational backend, acting as the primary knowledge representation for the entire mapping process. Our approach leverages prior work on incremental scene graph prediction to infer and update the graph structure in real-time as the environment is explored. This ensures that the map remains topologically consistent and computationally efficient, even during extended operations in large-scale settings. By maintaining an explicit, spatially grounded representation that supports both flat and hierarchical topologies, we bridge the gap between sub-symbolic raw sensor data and high-level symbolic reasoning. Consequently, this provides a stable, verifiable structure that knowledge-driven frameworks, ranging from knowledge graphs and ontologies to Large Language Models (LLMs), can directly exploit, enabling agents to operate with enhanced interpretability, trustworthiness, and alignment to human concepts.