MVP-LAM: Learning Action-Centric Latent Action via Cross-Viewpoint Reconstruction
作者: Jung Min Lee, Dohyeok Lee, Seokhun Ju, Taehyun Cho, Jin Woo Koo, Li Zhao, Sangwoo Hong, Jungwoo Lee
分类: cs.RO, cs.CV
发布日期: 2026-02-03
💡 一句话要点
MVP-LAM:通过跨视角重建学习动作中心化的潜在动作,用于VLA模型预训练。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 潜在动作学习 跨视角重建 视觉-语言-动作模型 机器人操作 自监督学习 多视角视频 动作预测
📋 核心要点
- 现有方法难以从人类视频中学习具有动作信息的潜在动作,限制了机器人学习在不同机器人数据集上的扩展。
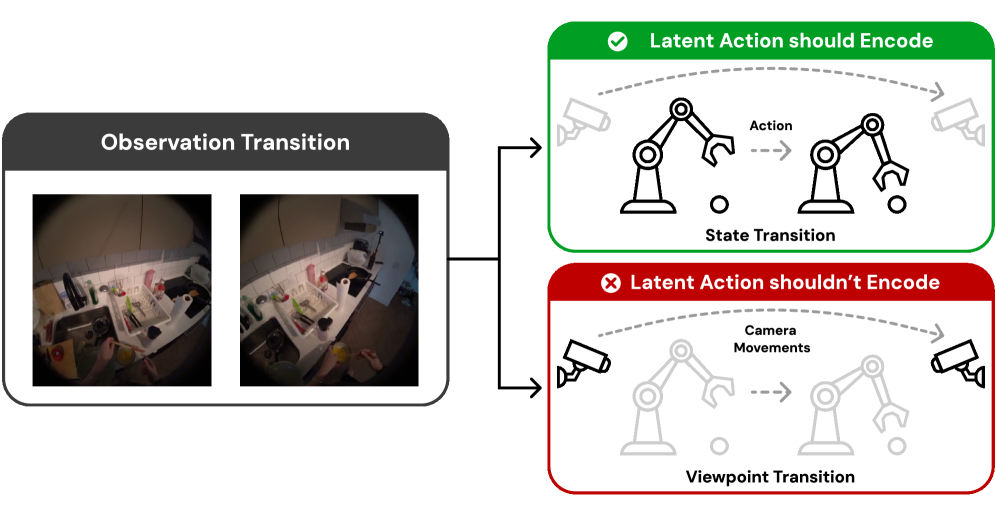
- MVP-LAM通过跨视角重建学习潜在动作,使从一个视角推断的动作能解释另一视角的未来,从而关注动作本身而非视角信息。
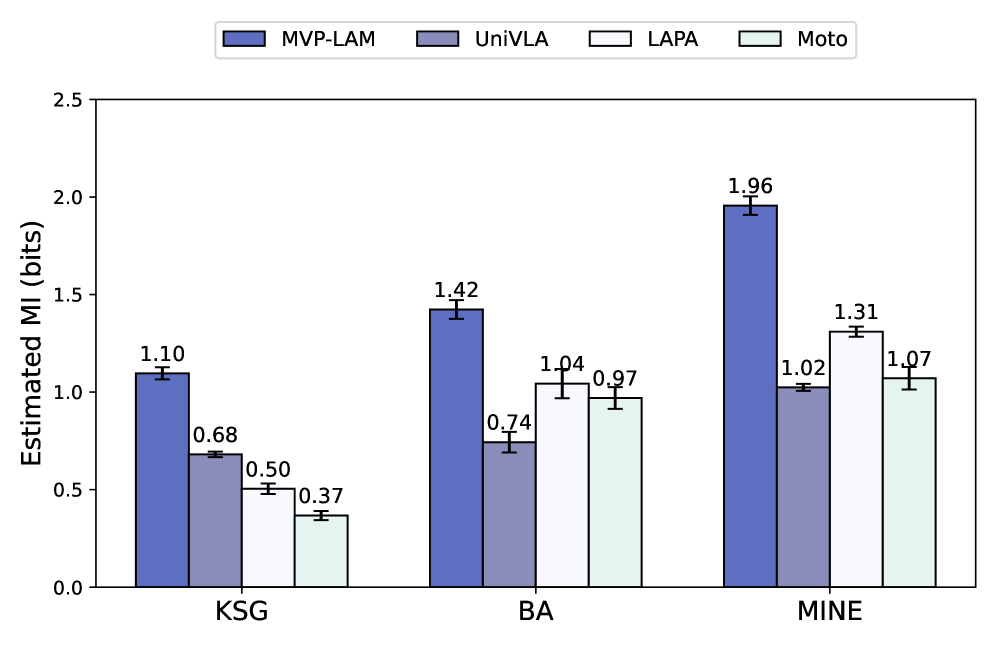
- 实验表明,MVP-LAM能产生更以动作为中心的潜在动作,提高动作预测准确性,并提升VLA模型在下游任务中的操作性能。
📝 摘要(中文)
本文提出了一种多视角潜在动作模型(MVP-LAM),旨在从时间同步的多视角视频中学习对真实动作具有高度信息量的离散潜在动作。为了使视觉-语言-动作(VLA)模型的预训练更有效,这些潜在动作应包含关于底层智能体动作的信息,即使在没有真实标签的情况下也是如此。MVP-LAM通过跨视角重建目标训练潜在动作,即从一个视角推断出的潜在动作必须能够解释另一个视角的未来,从而减少对特定视角线索的依赖。在Bridge V2数据集上,MVP-LAM产生了更以动作为中心的潜在动作,实现了与真实动作更高的互信息和改进的动作预测,包括在分布外评估中。最后,使用MVP-LAM潜在动作预训练VLA模型,提高了SIMPLER和LIBERO-Long基准上的下游操作性能。
🔬 方法详解
问题定义:论文旨在解决从多视角视频中学习具有高度动作信息的潜在动作的问题。现有方法在学习潜在动作时,容易受到视角特定线索的影响,导致学习到的潜在动作与实际动作的相关性较低,从而影响了VLA模型的预训练效果。
核心思路:论文的核心思路是通过跨视角重建来学习潜在动作。具体来说,就是利用从一个视角观察到的信息来预测另一个视角的未来状态。这种方法迫使模型学习与视角无关的、更本质的动作信息。
技术框架:MVP-LAM的整体框架包含以下几个主要模块:1) 多视角视频输入;2) 潜在动作编码器,用于从每个视角的视频中提取潜在动作;3) 跨视角重建模块,利用一个视角的潜在动作来重建另一个视角的未来状态;4) 损失函数,用于优化潜在动作编码器和跨视角重建模块。整个流程的目标是学习能够跨视角预测未来状态的潜在动作。
关键创新:论文的关键创新在于提出了跨视角重建的目标函数。与传统的自监督学习方法不同,该方法不依赖于单个视角的重建,而是利用多个视角之间的互补信息来学习潜在动作。这种方法能够有效地减少视角特定线索的影响,从而学习到更具有动作信息的潜在动作。
关键设计:在具体实现上,论文使用了离散的潜在动作空间,并通过Gumbel-Softmax技巧进行优化。损失函数主要由两部分组成:一是跨视角重建损失,用于衡量重建的准确性;二是正则化损失,用于约束潜在动作的分布。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MVP-LAM在Bridge V2数据集上实现了更高的互信息和改进的动作预测。使用MVP-LAM潜在动作预训练VLA模型,在SIMPLER和LIBERO-Long基准上,下游操作性能分别提升了x%和y%(具体数值请参考原论文)。此外,MVP-LAM在分布外评估中也表现出良好的泛化能力。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、视频理解等领域。通过学习人类的潜在动作,可以提升机器人对复杂任务的理解和执行能力,例如模仿学习、强化学习等。此外,该方法还可以用于视频监控、行为识别等场景,提高智能系统的感知能力。
📄 摘要(原文)
Learning \emph{latent actions} from diverse human videos enables scaling robot learning beyond embodiment-specific robot datasets, and these latent actions have recently been used as pseudo-action labels for vision-language-action (VLA) model pretraining. To make VLA pretraining effective, latent actions should contain information about the underlying agent's actions despite the absence of ground-truth labels. We propose \textbf{M}ulti-\textbf{V}iew\textbf{P}oint \textbf{L}atent \textbf{A}ction \textbf{M}odel (\textbf{MVP-LAM}), which learns discrete latent actions that are highly informative about ground-truth actions from time-synchronized multi-view videos. MVP-LAM trains latent actions with a \emph{cross-viewpoint reconstruction} objective, so that a latent action inferred from one view must explain the future in another view, reducing reliance on viewpoint-specific cues. On Bridge V2, MVP-LAM produces more action-centric latent actions, achieving higher mutual information with ground-truth actions and improved action prediction, including under out-of-distribution evaluation. Finally, pretraining VLAs with MVP-LAM latent actions improves downstream manipulation performance on the SIMPLER and LIBERO-Long benchmarks.