ProAct: A Benchmark and Multimodal Framework for Structure-Aware Proactive Response
作者: Xiaomeng Zhu, Fengming Zhu, Weijie Zhou, Ye Tian, Zhenlin Hu, Yufei Huang, Yuchun Guo, Xinyu Wu, Zhengyou Zhang, Fangzhen Lin, Xuantang Xiong
分类: cs.RO
发布日期: 2026-02-03
💡 一句话要点
ProAct:提出一个结构感知的多模态主动响应基准和框架,用于辅助、维护和安全监控等任务。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主动响应 多模态学习 任务图 启发式搜索 基准数据集 大语言模型 机器人 结构化信息
📋 核心要点
- 现有被动代理仅遵循指令,缺乏主动性,而主动代理的开发受限于缺乏专门的资源。
- ProAct-Helper利用多模态大语言模型进行状态检测,并结合任务图进行动作选择的启发式搜索,实现主动响应。
- 实验表明,ProAct-Helper在触发检测、步数节省和并行动作比例方面均优于现有模型,性能显著提升。
📝 摘要(中文)
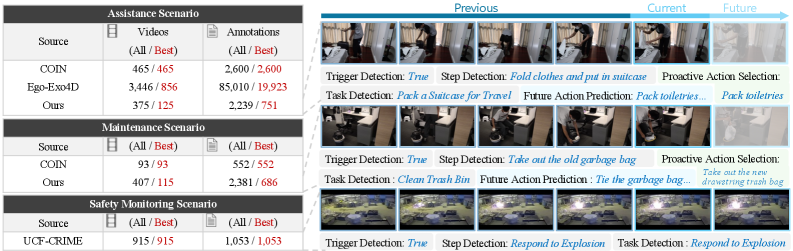
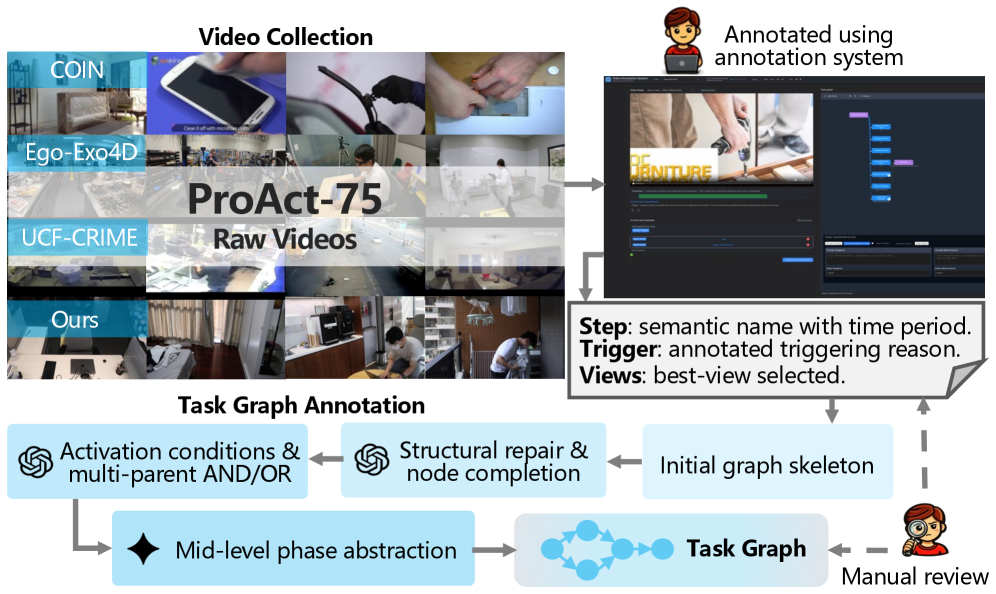
本文提出了ProAct-75,一个用于训练和评估主动代理的基准数据集,涵盖辅助、维护和安全监控等多个领域,包含75个任务和91,581个步骤级别的标注,并使用显式的任务图来增强数据,任务图编码了步骤依赖关系和平行执行的可能性,为复杂决策提供结构化的基础。此外,本文还提出了ProAct-Helper,一个基于多模态大型语言模型(MLLM)的参考基线,它将决策建立在状态检测的基础上,并利用任务图进行熵驱动的启发式搜索以选择动作,使代理能够独立地执行并行线程,而不是简单地模仿人类的下一步动作。大量实验表明,ProAct-Helper优于强大的闭源模型,触发检测的mF1提高了6.21%,在线单步决策节省了0.25步,并行动作的比例提高了15.58%。
🔬 方法详解
问题定义:现有代理通常是被动的,只能按照指令执行任务,无法根据环境变化和任务目标主动采取行动。开发主动代理面临缺乏专门数据集和有效方法的问题,尤其是在需要理解任务结构和并行执行动作的复杂场景下。
核心思路:本文的核心思路是构建一个包含丰富结构化信息的基准数据集ProAct-75,并设计一个能够利用这些结构化信息进行主动决策的代理ProAct-Helper。通过任务图编码步骤依赖关系和平行执行的可能性,使代理能够理解任务的整体结构,并根据当前状态和任务目标选择最优的动作序列。
技术框架:ProAct-Helper的整体框架包含以下几个主要模块:1) 状态检测模块:利用多模态大型语言模型(MLLM)感知环境状态。2) 任务图表示模块:将任务分解为步骤,并使用图结构编码步骤之间的依赖关系和平行执行的可能性。3) 动作选择模块:基于当前状态和任务图,使用熵驱动的启发式搜索算法选择下一步要执行的动作。4) 执行模块:执行选定的动作,并更新环境状态。
关键创新:本文的关键创新在于:1) 提出了ProAct-75基准数据集,该数据集包含丰富的结构化信息,为训练和评估主动代理提供了基础。2) 设计了ProAct-Helper代理,该代理能够利用任务图进行动作选择,从而实现主动决策和并行执行。3) 提出了熵驱动的启发式搜索算法,用于在任务图中选择最优的动作序列。
关键设计:ProAct-Helper的关键设计包括:1) 使用多模态大语言模型进行状态检测,以提高环境感知的准确性。2) 使用任务图编码步骤依赖关系和平行执行的可能性,以支持复杂决策。3) 使用熵驱动的启发式搜索算法,以在任务图中选择最优的动作序列。具体参数设置和网络结构等细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
ProAct-Helper在ProAct-75基准测试中表现出色,相较于强大的闭源模型,触发检测的mF1提高了6.21%,在线单步决策节省了0.25步,并行动作的比例提高了15.58%。这些结果表明,ProAct-Helper能够有效地利用任务图进行主动决策,并在复杂任务中取得显著的性能提升。
🎯 应用场景
该研究成果可广泛应用于需要主动响应的场景,如智能家居中的辅助机器人、工业生产中的维护机器人、以及安全监控系统中的预警代理。通过理解任务结构和环境状态,主动代理能够更有效地完成任务,提高工作效率和安全性,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
While passive agents merely follow instructions, proactive agents align with higher-level objectives, such as assistance and safety by continuously monitoring the environment to determine when and how to act. However, developing proactive agents is hindered by the lack of specialized resources. To address this, we introduce ProAct-75, a benchmark designed to train and evaluate proactive agents across diverse domains, including assistance, maintenance, and safety monitoring. Spanning 75 tasks, our dataset features 91,581 step-level annotations enriched with explicit task graphs. These graphs encode step dependencies and parallel execution possibilities, providing the structural grounding necessary for complex decision-making. Building on this benchmark, we propose ProAct-Helper, a reference baseline powered by a Multimodal Large Language Model (MLLM) that grounds decision-making in state detection, and leveraging task graphs to enable entropy-driven heuristic search for action selection, allowing agents to execute parallel threads independently rather than mirroring the human's next step. Extensive experiments demonstrate that ProAct-Helper outperforms strong closed-source models, improving trigger detection mF1 by 6.21%, saving 0.25 more steps in online one-step decision, and increasing the rate of parallel actions by 15.58%.