Learning-based Initialization of Trajectory Optimization for Path-following Problems of Redundant Manipulators
作者: Minsung Yoon, Mincheul Kang, Daehyung Park, Sung-Eui Yoon
分类: cs.RO
发布日期: 2026-02-03
备注: Accepted to ICRA 2023. Project Page
💡 一句话要点
提出基于学习的轨迹优化初始化方法,加速冗余机械臂路径跟随
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 轨迹优化 强化学习 冗余机械臂 路径跟随 模仿学习
📋 核心要点
- 轨迹优化在冗余机械臂路径跟随中应用广泛,但对初始轨迹质量敏感,高质量初始轨迹的获取是挑战。
- 论文提出一种基于示例引导强化学习的初始轨迹生成方法,旨在快速生成高质量的初始轨迹。
- 实验结果表明,该方法能有效提升轨迹优化的效率、优化性和适用性,并在真实机械臂上验证了可行性。
📝 摘要(中文)
轨迹优化(TO)是生成冗余机械臂关节轨迹以跟随6维笛卡尔路径的有效工具。优化性能很大程度上取决于初始轨迹的质量。然而,由于解轨迹空间极大,且缺乏关于配置空间中任务约束的先验知识,选择高质量的初始轨迹并非易事,需要大量时间。为了缓解这个问题,我们提出了一种基于学习的初始轨迹生成方法,通过采用示例引导的强化学习,在较短的时间内生成高质量的初始轨迹。此外,我们提出了一种零空间投影的模仿奖励,通过有效地学习专家演示中捕获的运动学可行运动来考虑零空间约束。仿真中的统计评估表明,与其它三个基线相比,当使用我们方法的输出时,TO的优化性、效率和适用性都得到了提高。我们还通过七自由度机械臂的真实世界实验展示了性能的提升和可行性。
🔬 方法详解
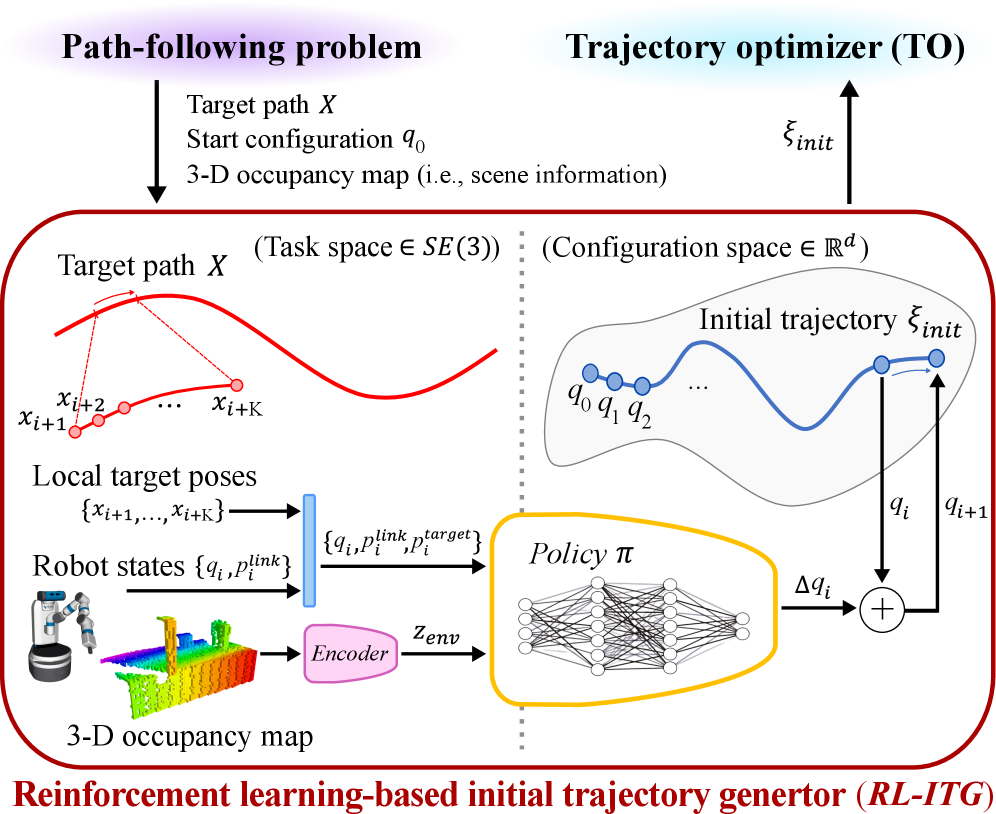
问题定义:论文旨在解决冗余机械臂在进行路径跟随任务时,轨迹优化对初始轨迹质量高度依赖的问题。现有方法在生成高质量初始轨迹时,由于搜索空间巨大且缺乏先验知识,往往需要耗费大量时间,成为轨迹优化流程的瓶颈。
核心思路:论文的核心思路是利用强化学习,通过模仿学习专家演示数据,学习生成高质量的初始轨迹。通过学习,模型能够快速生成运动学上可行的初始轨迹,从而加速轨迹优化的收敛过程,并提高最终轨迹的质量。
技术框架:整体框架包含以下几个主要阶段:1) 收集专家演示数据,包含机械臂的关节轨迹和对应的笛卡尔空间路径;2) 使用强化学习算法训练一个策略网络,该网络以当前机械臂状态和目标路径为输入,输出一个初始的关节轨迹;3) 在强化学习的奖励函数中,引入零空间投影的模仿奖励,鼓励生成的轨迹与专家演示轨迹在零空间分量上保持一致,从而更好地满足零空间约束;4) 将生成的初始轨迹输入到轨迹优化器中,进行进一步的优化。
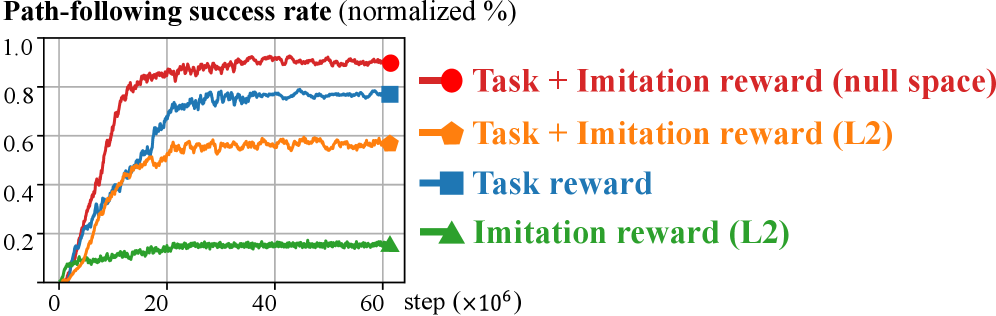
关键创新:论文的关键创新在于将强化学习与轨迹优化相结合,并提出了零空间投影的模仿奖励。传统的轨迹优化方法依赖于人工设计的启发式方法来生成初始轨迹,而该方法通过学习的方式,能够自动地从专家数据中提取有用的信息,从而生成更好的初始轨迹。零空间投影的模仿奖励能够有效地利用专家演示数据中的零空间运动信息,从而更好地满足机械臂的零空间约束。
关键设计:论文中,强化学习算法采用了一种基于策略梯度的算法,例如PPO。奖励函数的设计至关重要,除了传统的任务奖励(例如,与目标路径的接近程度)之外,还包括零空间投影的模仿奖励。模仿奖励的计算方式是将生成的轨迹和专家演示轨迹投影到机械臂的零空间中,然后计算它们之间的距离。网络结构的选择也需要仔细考虑,通常采用多层感知机或循环神经网络来处理时间序列数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与三种基线方法相比,该方法能够显著提高轨迹优化的效率和优化性。在仿真实验中,使用该方法生成的初始轨迹,轨迹优化器能够更快地收敛到最优解,并且最终的轨迹误差更小。在真实机械臂实验中,该方法也能够成功地生成可行的轨迹,并实现精确的路径跟随。
🎯 应用场景
该研究成果可广泛应用于工业机器人、医疗机器人等领域,尤其是在需要高精度和高效率的路径跟随任务中。例如,在汽车制造、电子组装等自动化生产线上,机械臂需要精确地按照预定的路径进行操作,该方法可以显著提高机械臂的运动效率和精度。此外,该方法还可以应用于康复机器人领域,帮助患者进行精确的肢体运动训练。
📄 摘要(原文)
Trajectory optimization (TO) is an efficient tool to generate a redundant manipulator's joint trajectory following a 6-dimensional Cartesian path. The optimization performance largely depends on the quality of initial trajectories. However, the selection of a high-quality initial trajectory is non-trivial and requires a considerable time budget due to the extremely large space of the solution trajectories and the lack of prior knowledge about task constraints in configuration space. To alleviate the issue, we present a learning-based initial trajectory generation method that generates high-quality initial trajectories in a short time budget by adopting example-guided reinforcement learning. In addition, we suggest a null-space projected imitation reward to consider null-space constraints by efficiently learning kinematically feasible motion captured in expert demonstrations. Our statistical evaluation in simulation shows the improved optimality, efficiency, and applicability of TO when we plug in our method's output, compared with three other baselines. We also show the performance improvement and feasibility via real-world experiments with a seven-degree-of-freedom manipulator.