Enhancing Navigation Efficiency of Quadruped Robots via Leveraging Personal Transportation Platforms
作者: Minsung Yoon, Sung-Eui Yoon
分类: cs.RO
发布日期: 2026-02-03
备注: Accepted to ICRA 2025. Project Page
💡 一句话要点
提出基于强化学习的主动式运输平台骑行方法,提升四足机器人导航效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 导航 运输平台 状态估计
📋 核心要点
- 四足机器人依赖腿部运动,长距离导航效率受限,能量消耗高,难以满足实际应用需求。
- 提出基于强化学习的主动式运输平台骑行方法(RL-ATR),使四足机器人能够搭乘运输平台,提升导航效率。
- 仿真实验表明,该方法能够有效跟踪指令,降低能量消耗,并验证了各个组件的有效性。
📝 摘要(中文)
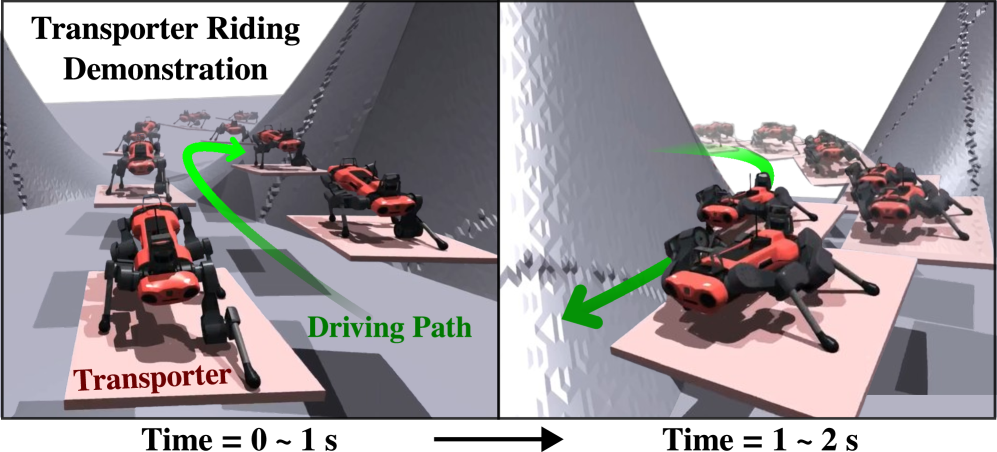
四足机器人在长距离导航效率方面存在局限性,主要由于其依赖腿部运动。为了缓解这一限制,我们提出了一种基于强化学习的主动式运输平台骑行方法(RL-ATR),其灵感来源于人类使用赛格威等个人运输工具。RL-ATR包含一个运输平台骑行策略和两个状态估计器。该策略根据特定运输平台的控制动力学设计适当的操纵策略,而状态估计器通过推断不可观测的机器人和运输平台状态来解决非惯性坐标系中的传感器模糊问题。全面的仿真评估验证了该方法在各种运输平台-机器人模型上的出色指令跟踪能力,并降低了相对于腿部运动的能量消耗。此外,我们进行了消融研究,以量化RL-ATR中各个组件的贡献。这种骑行能力可以扩展四足机器人的运动方式,从而可能扩大其操作范围和效率。
🔬 方法详解
问题定义:四足机器人在长距离导航时,单纯依靠腿部运动效率较低,能量消耗大,限制了其应用范围。现有的四足机器人导航方法主要集中在步态优化和地形适应性上,很少考虑利用外部设备来提升导航效率。因此,如何有效地利用个人运输平台来提升四足机器人的导航效率是一个亟待解决的问题。
核心思路:论文的核心思路是让四足机器人像人类一样,通过搭乘个人运输平台(如赛格威)来提升导航效率。通过强化学习训练一个策略,使机器人能够根据运输平台的动力学特性,学会如何操纵运输平台,从而实现高效的导航。同时,考虑到非惯性坐标系下的传感器数据存在模糊性,设计状态估计器来推断机器人和运输平台的状态。
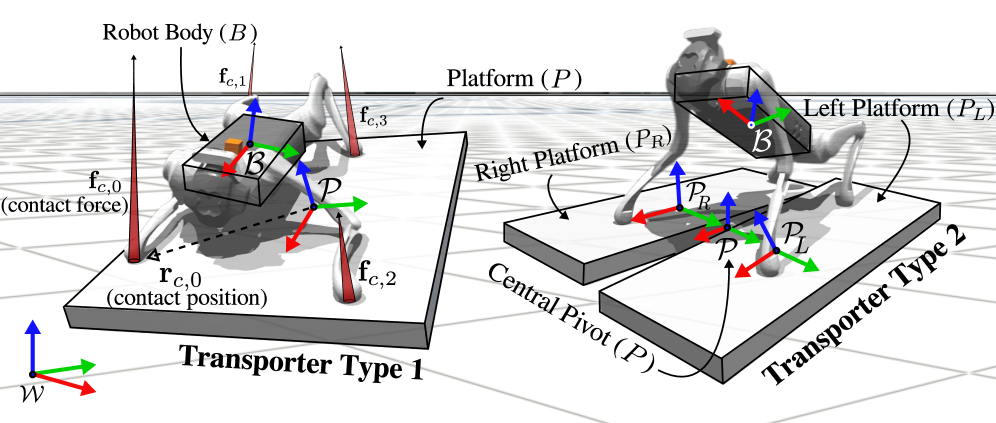
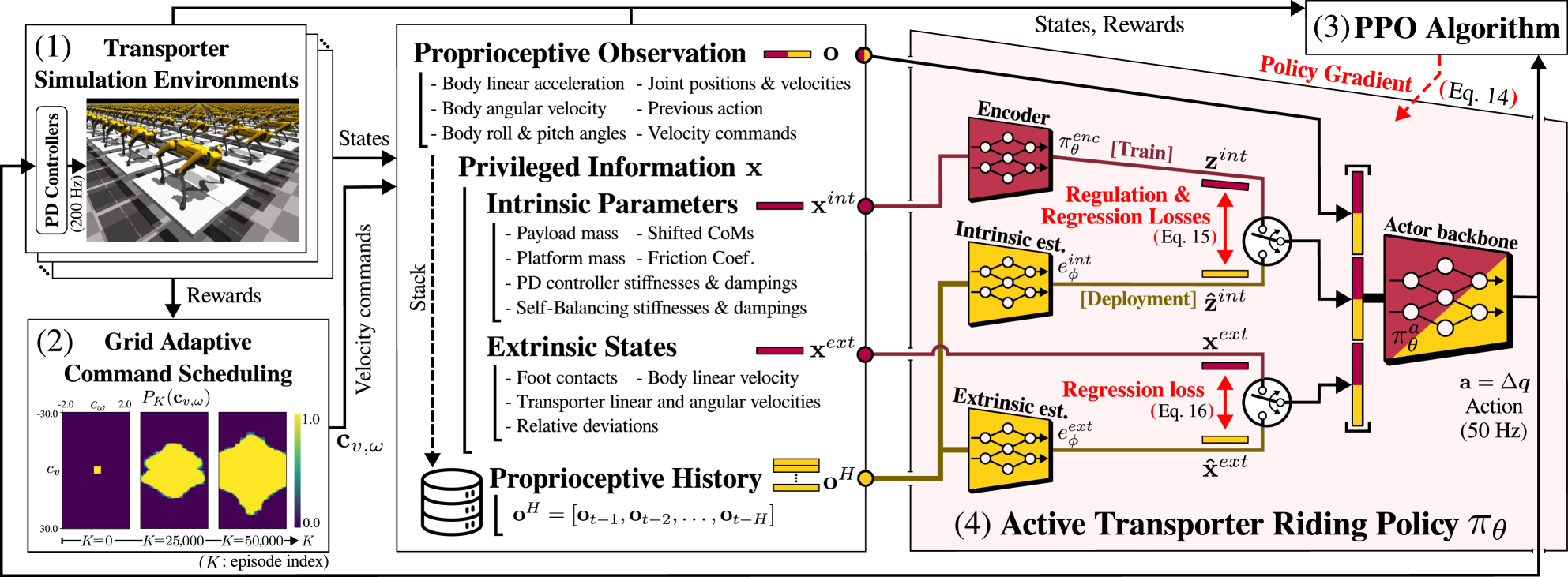
技术框架:RL-ATR方法包含两个主要模块:运输平台骑行策略和状态估计器。运输平台骑行策略通过强化学习训练得到,负责根据当前状态输出控制指令,控制运输平台的运动。状态估计器则负责从传感器数据中估计机器人和运输平台的状态,为骑行策略提供输入。整体流程是:传感器数据输入状态估计器,状态估计器输出状态估计值,状态估计值输入骑行策略,骑行策略输出控制指令,控制指令作用于运输平台,运输平台带动机器人运动。
关键创新:该论文的关键创新在于提出了基于强化学习的主动式运输平台骑行方法。与传统的四足机器人导航方法相比,该方法能够充分利用运输平台的运动能力,显著提升导航效率。此外,该方法还考虑了非惯性坐标系下的传感器数据模糊性问题,并设计了状态估计器来解决该问题。
关键设计:骑行策略采用深度强化学习算法训练,具体算法未知(论文未明确说明)。状态估计器可能采用了卡尔曼滤波或粒子滤波等方法,具体实现细节未知(论文未明确说明)。损失函数的设计可能包括奖励函数,用于鼓励机器人保持平衡、跟踪目标轨迹和降低能量消耗。具体的网络结构和参数设置未知(论文未明确说明)。
🖼️ 关键图片
📊 实验亮点
仿真实验结果表明,RL-ATR方法能够有效控制四足机器人搭乘运输平台,实现精确的指令跟踪。与传统的腿部运动相比,该方法能够显著降低能量消耗。消融研究表明,骑行策略和状态估计器都对整体性能有重要贡献。具体的性能数据和提升幅度未知(论文未提供具体数值)。
🎯 应用场景
该研究成果可应用于物流配送、安防巡检、灾害救援等领域。通过搭载个人运输平台,四足机器人可以快速到达目标地点,执行任务,提高工作效率。未来,该技术还可以与其他技术结合,例如视觉导航、自主避障等,进一步提升四足机器人的智能化水平和应用范围。
📄 摘要(原文)
Quadruped robots face limitations in long-range navigation efficiency due to their reliance on legs. To ameliorate the limitations, we introduce a Reinforcement Learning-based Active Transporter Riding method (\textit{RL-ATR}), inspired by humans' utilization of personal transporters, including Segways. The \textit{RL-ATR} features a transporter riding policy and two state estimators. The policy devises adequate maneuvering strategies according to transporter-specific control dynamics, while the estimators resolve sensor ambiguities in non-inertial frames by inferring unobservable robot and transporter states. Comprehensive evaluations in simulation validate proficient command tracking abilities across various transporter-robot models and reduced energy consumption compared to legged locomotion. Moreover, we conduct ablation studies to quantify individual component contributions within the \textit{RL-ATR}. This riding ability could broaden the locomotion modalities of quadruped robots, potentially expanding the operational range and efficiency.