RDT2: Exploring the Scaling Limit of UMI Data Towards Zero-Shot Cross-Embodiment Generalization
作者: Songming Liu, Bangguo Li, Kai Ma, Lingxuan Wu, Hengkai Tan, Xiao Ouyang, Hang Su, Jun Zhu
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2026-02-03
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RDT2:探索UMI数据规模极限,实现机器人零样本跨具身泛化
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人 视觉-语言-动作模型 零样本学习 跨具身泛化 通用操作界面 残差向量量化 流匹配
📋 核心要点
- 现有VLA模型在机器人通用性方面受限于数据量不足、架构效率低以及跨平台泛化能力弱。
- RDT2通过大规模UMI数据、三阶段训练和残差向量量化等技术,实现了零样本跨具身泛化。
- RDT2在多种机器人任务中超越现有技术,包括零样本泛化和复杂动态任务。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在通用机器人领域展现出潜力,但目前面临数据稀缺、架构效率低下以及无法跨不同硬件平台泛化的问题。我们提出了RDT2,一个基于70亿参数VLM的机器人基础模型,旨在实现开放词汇任务中对新具身机器人的零样本部署。为此,我们利用增强的、与具身无关的通用操作界面(UMI),收集了超过10,000小时的多样化机器人演示数据集,这是目前最大的开源机器人数据集之一。我们的方法采用了一种新颖的三阶段训练方案,通过残差向量量化(RVQ)、流匹配和蒸馏将离散的语言知识与连续控制对齐,以实现实时推理。因此,RDT2成为首批能够同时零样本泛化到未见过的物体、场景、指令甚至机器人平台的模型之一。此外,它在灵巧、长时程和动态的下游任务(如打乒乓球)中优于最先进的基线。
🔬 方法详解
问题定义:现有机器人VLA模型难以在不同机器人硬件平台之间进行泛化,即“跨具身泛化”能力不足。同时,数据稀缺和模型效率也是阻碍VLA模型发展的关键问题。现有方法通常依赖于特定机器人平台的数据,难以适应新的机器人形态和任务。
核心思路:论文的核心思路是利用大规模、具身无关的通用操作界面(UMI)数据,训练一个能够理解语言指令并控制不同机器人的通用模型。通过三阶段训练,将离散的语言知识与连续的控制动作对齐,从而实现零样本跨具身泛化。
技术框架:RDT2的训练分为三个阶段:1) 使用大规模UMI数据预训练一个视觉-语言模型(VLM)。2) 利用残差向量量化(RVQ)将连续的控制动作离散化,并与语言指令对齐。3) 使用流匹配和蒸馏技术,将模型压缩并加速推理,使其能够在实时环境中运行。整体架构包含数据收集模块、模型训练模块和部署模块。
关键创新:RDT2的关键创新在于:1) 大规模、具身无关的UMI数据集,为模型提供了丰富的训练数据。2) 三阶段训练方案,有效地将语言知识与控制动作对齐。3) 利用残差向量量化(RVQ)进行动作离散化,简化了学习难度。与现有方法相比,RDT2能够实现真正的零样本跨具身泛化,无需针对特定机器人进行微调。
关键设计:RDT2使用了一个70亿参数的VLM作为基础模型。在RVQ阶段,使用多层向量量化器将连续动作空间离散化为多个码本。流匹配用于学习连续动作的概率分布,蒸馏则用于将大模型知识迁移到小模型,以提高推理速度。损失函数包括语言建模损失、动作预测损失和蒸馏损失。
🖼️ 关键图片
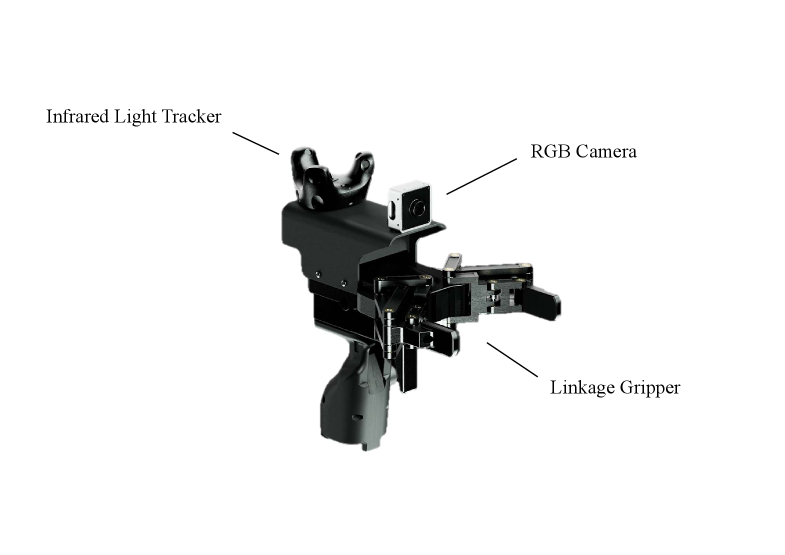
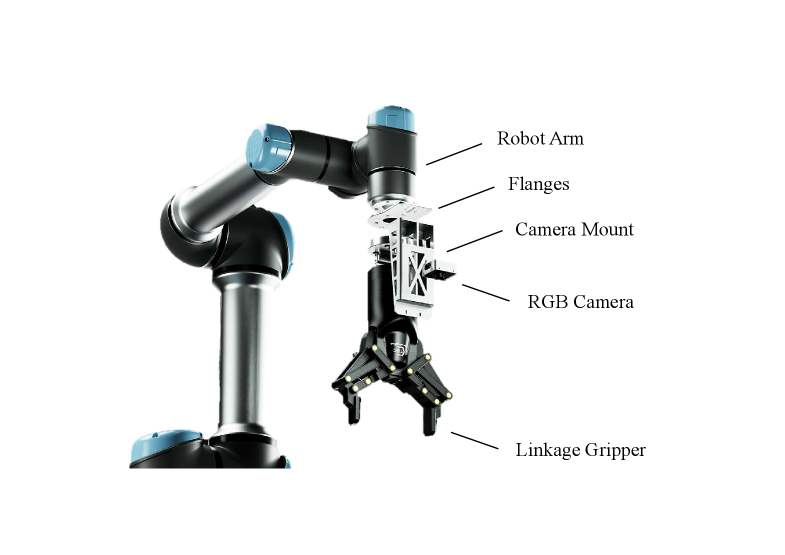
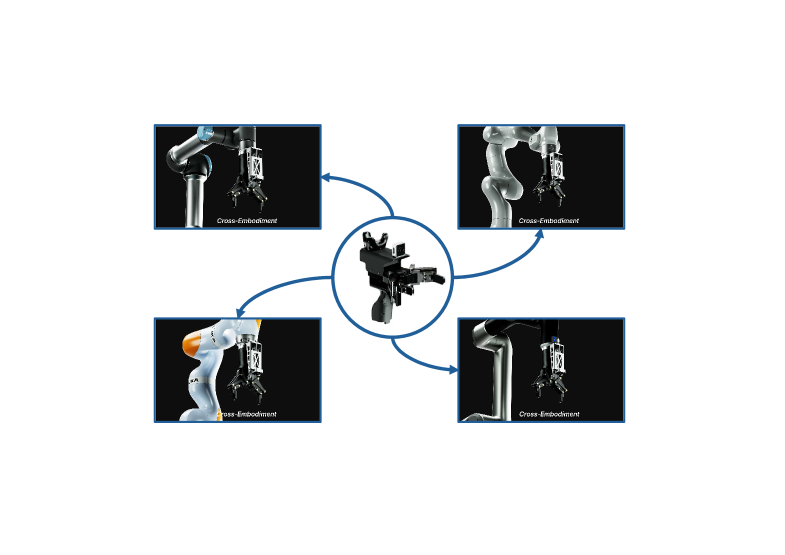
📊 实验亮点
RDT2在多个机器人任务中取得了显著的成果。例如,在打乒乓球任务中,RDT2优于现有技术。此外,RDT2能够零样本泛化到未见过的物体、场景、指令甚至机器人平台,展示了强大的泛化能力。该模型在灵巧操作、长时程任务和动态任务中均表现出色。
🎯 应用场景
RDT2具有广泛的应用前景,包括智能制造、家庭服务、医疗辅助等领域。它可以使机器人能够理解自然语言指令,并灵活地适应不同的工作环境和任务需求。通过零样本跨具身泛化,RDT2可以降低机器人部署成本,加速机器人技术的普及。
📄 摘要(原文)
Vision-Language-Action (VLA) models hold promise for generalist robotics but currently struggle with data scarcity, architectural inefficiencies, and the inability to generalize across different hardware platforms. We introduce RDT2, a robotic foundation model built upon a 7B parameter VLM designed to enable zero-shot deployment on novel embodiments for open-vocabulary tasks. To achieve this, we collected one of the largest open-source robotic datasets--over 10,000 hours of demonstrations in diverse families--using an enhanced, embodiment-agnostic Universal Manipulation Interface (UMI). Our approach employs a novel three-stage training recipe that aligns discrete linguistic knowledge with continuous control via Residual Vector Quantization (RVQ), flow-matching, and distillation for real-time inference. Consequently, RDT2 becomes one of the first models that simultaneously zero-shot generalizes to unseen objects, scenes, instructions, and even robotic platforms. Besides, it outperforms state-of-the-art baselines in dexterous, long-horizon, and dynamic downstream tasks like playing table tennis. See https://rdt-robotics.github.io/rdt2/ for more information.