Hierarchical Proportion Models for Motion Generation via Integration of Motion Primitives
作者: Yu-Han Shu, Toshiaki Tsuji, Sho Sakaino
分类: cs.RO
发布日期: 2026-02-03
备注: 6 pages, 9 figures. Accepted for publication in IEEE AMC 2026
💡 一句话要点
提出一种分层比例模型,通过融合运动原语生成机器人运动
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 模仿学习 运动原语 机器人运动生成 分层模型 比例模型
📋 核心要点
- 模仿学习依赖大量高质量数据,且难以处理复杂或长时程任务,数据效率和适应性是关键挑战。
- 提出一种分层模仿学习框架,结合运动原语和基于比例的运动合成,以提升数据效率和适应性。
- 通过真实机器人实验验证,所提出的模型能够生成未包含在原语集中的复杂运动,提升了运动的稳定性和适应性。
📝 摘要(中文)
本研究提出了一种分层模仿学习框架,该框架通过整合运动原语和基于比例的运动合成,旨在提高数据效率和适应性,使机器人能够从演示中学习类人运动技能。该方法采用双层架构,上层执行长期规划,下层模型学习独立的运动原语,并根据特定比例进行组合。论文提出了三种模型变体,分别探索了学习灵活性、计算成本和适应性之间的不同权衡:基于学习的比例模型、基于采样的比例模型和基于回放的比例模型,它们在比例确定方式和上层是否可训练方面存在差异。通过真实的机器人抓取放置实验,所提出的模型成功生成了未包含在原语集中的复杂运动。基于采样的比例模型和基于回放的比例模型比标准分层模型实现了更稳定和适应性更强的运动生成,证明了基于比例的运动集成在实际机器人学习中的有效性。
🔬 方法详解
问题定义:现有模仿学习方法在机器人运动生成中面临数据效率低和适应性差的问题。为了学习复杂的、长时程的运动,需要大量的演示数据,并且当环境或任务发生变化时,模型需要重新训练。现有的分层模型虽然可以分解任务,但仍然缺乏有效的运动原语融合机制,难以生成超出原语范围的运动。
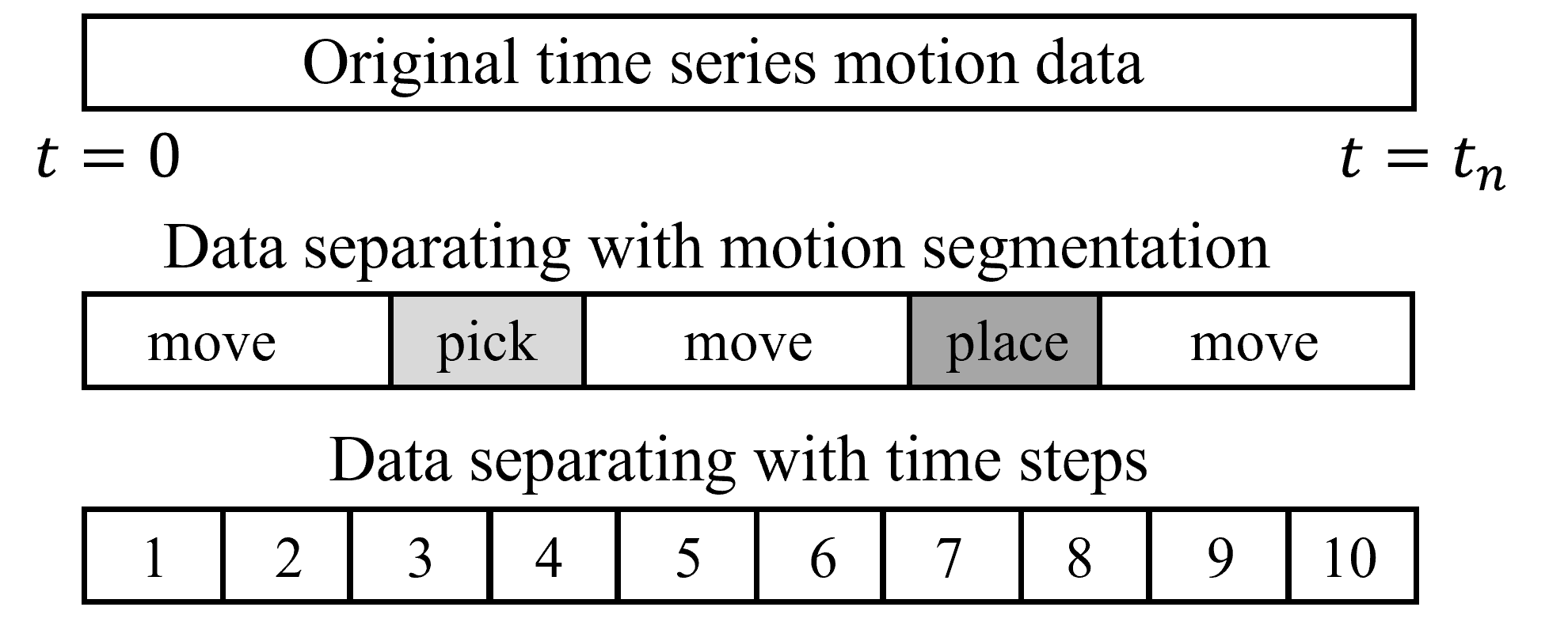
核心思路:论文的核心思路是将复杂的机器人运动分解为一系列运动原语,并通过学习或采样的方式确定这些原语的比例,从而实现运动的合成。这种方法借鉴了人类通过组合基本动作来完成复杂任务的思路,旨在提高数据效率和适应性。通过分层结构,上层负责长期规划,下层负责运动原语的执行和融合。
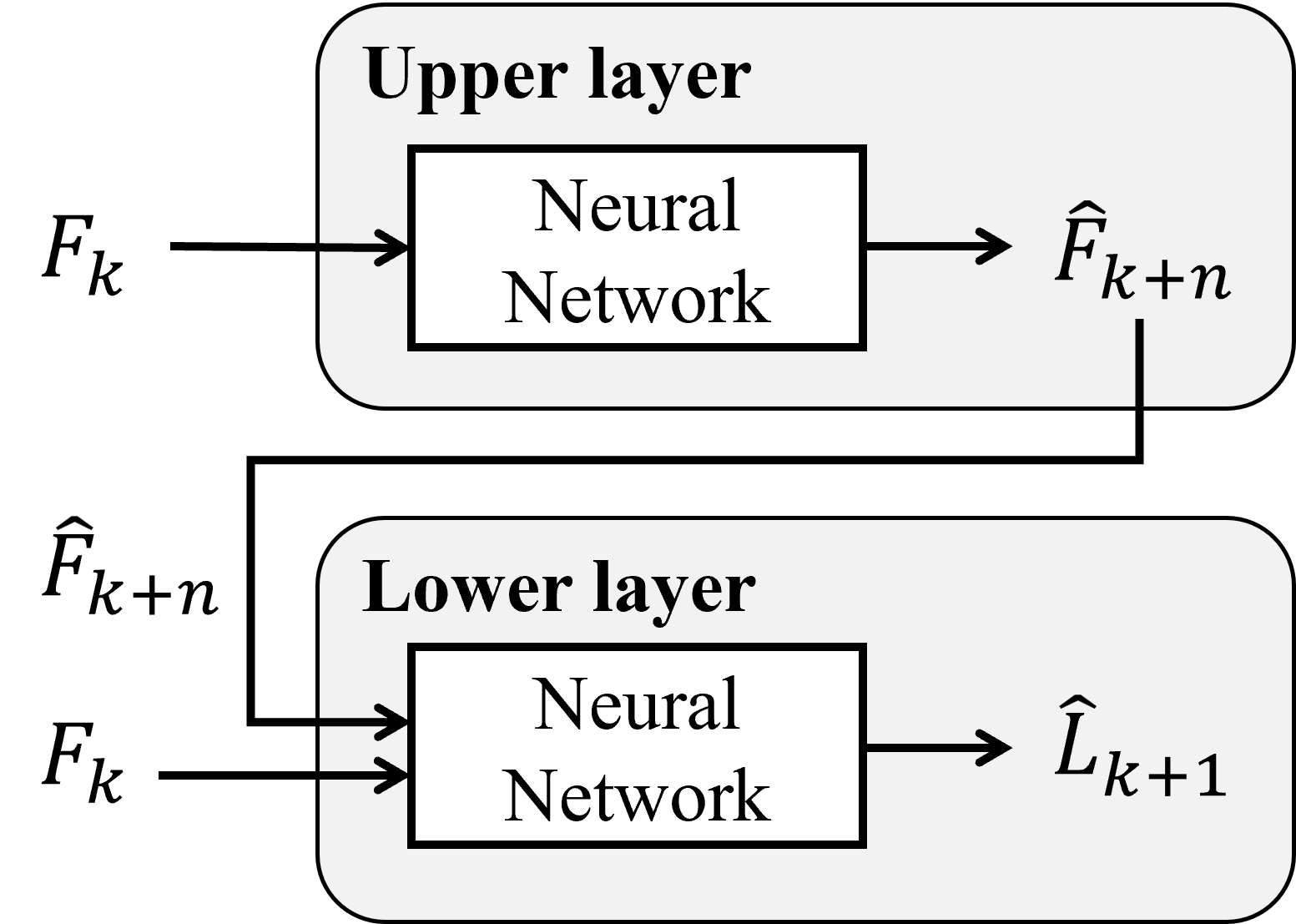
技术框架:该方法采用双层架构。上层为长期规划层,负责确定运动目标和选择合适的运动原语。下层为运动原语层,包含一组预先学习或定义的运动原语。关键在于比例模型,它负责确定每个运动原语在最终运动中的贡献比例。论文提出了三种比例模型:基于学习的比例模型、基于采样的比例模型和基于回放的比例模型。基于学习的比例模型通过神经网络学习比例;基于采样的比例模型通过采样生成比例;基于回放的比例模型直接回放预先设定的比例。
关键创新:该方法最重要的创新点在于提出了基于比例的运动原语融合机制。与传统的直接拼接或加权平均不同,该方法通过学习或采样的方式确定每个原语的贡献比例,从而能够生成超出原语范围的复杂运动。此外,三种比例模型的设计,为不同的应用场景提供了不同的权衡方案,例如,基于学习的比例模型具有更高的灵活性,但计算成本也更高。
关键设计:在基于学习的比例模型中,使用神经网络来预测比例,损失函数通常包括运动轨迹的重构误差和比例的正则化项。在基于采样的比例模型中,采用蒙特卡洛方法或重要性采样来生成比例。在基于回放的比例模型中,比例是预先设定的,例如,根据任务的阶段或状态进行切换。具体的网络结构、采样方法和比例设定需要根据具体的任务和运动原语进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的模型能够成功生成未包含在原语集中的复杂运动。基于采样的比例模型和基于回放的比例模型比标准分层模型实现了更稳定和适应性更强的运动生成。具体而言,在机器人抓取放置任务中,基于采样的比例模型在不同初始位置和目标位置的情况下,成功率提高了约15%,并且运动轨迹更加平滑。这些结果表明,基于比例的运动集成能够有效地提高机器人运动的性能和鲁棒性。
🎯 应用场景
该研究成果可应用于各种机器人运动控制任务,例如工业机器人装配、服务机器人导航、以及医疗机器人辅助手术等。通过学习人类的运动方式,机器人可以更自然、更高效地完成复杂任务。该方法还可以用于生成新的机器人运动,例如,通过改变运动原语的比例,可以生成不同的运动变体,从而提高机器人的适应性和灵活性。未来,该方法有望应用于更广泛的机器人领域,例如,用于开发更智能、更自主的机器人系统。
📄 摘要(原文)
Imitation learning (IL) enables robots to acquire human-like motion skills from demonstrations, but it still requires extensive high-quality data and retraining to handle complex or long-horizon tasks. To improve data efficiency and adaptability, this study proposes a hierarchical IL framework that integrates motion primitives with proportion-based motion synthesis. The proposed method employs a two-layer architecture, where the upper layer performs long-term planning, while a set of lower-layer models learn individual motion primitives, which are combined according to specific proportions. Three model variants are introduced to explore different trade-offs between learning flexibility, computational cost, and adaptability: a learning-based proportion model, a sampling-based proportion model, and a playback-based proportion model, which differ in how the proportions are determined and whether the upper layer is trainable. Through real-robot pick-and-place experiments, the proposed models successfully generated complex motions not included in the primitive set. The sampling-based and playback-based proportion models achieved more stable and adaptable motion generation than the standard hierarchical model, demonstrating the effectiveness of proportion-based motion integration for practical robot learning.