When Attention Betrays: Erasing Backdoor Attacks in Robotic Policies by Reconstructing Visual Tokens
作者: Xuetao Li, Pinhan Fu, Wenke Huang, Nengyuan Pan, Songhua Yang, Kaiyan Zhao, Guancheng Wan, Mengde Li, Jifeng Xuan, Miao Li
分类: cs.RO
发布日期: 2026-02-03
备注: ICRA2026 accepted
💡 一句话要点
提出Bera框架,通过重构视觉tokens擦除机器人策略中的后门攻击。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门攻击防御 视觉语言动作模型 机器人安全 注意力机制 图像重构
📋 核心要点
- 现有后门防御方法缺乏对多模态后门攻击的深入理解,或需要耗费大量计算资源进行模型重训练。
- Bera框架通过检测和屏蔽具有异常注意力的视觉tokens,并重构无触发图像来消除后门攻击的影响。
- 实验表明,Bera在保持机器人系统性能的同时,显著降低了攻击成功率,并恢复了良性行为。
📝 摘要(中文)
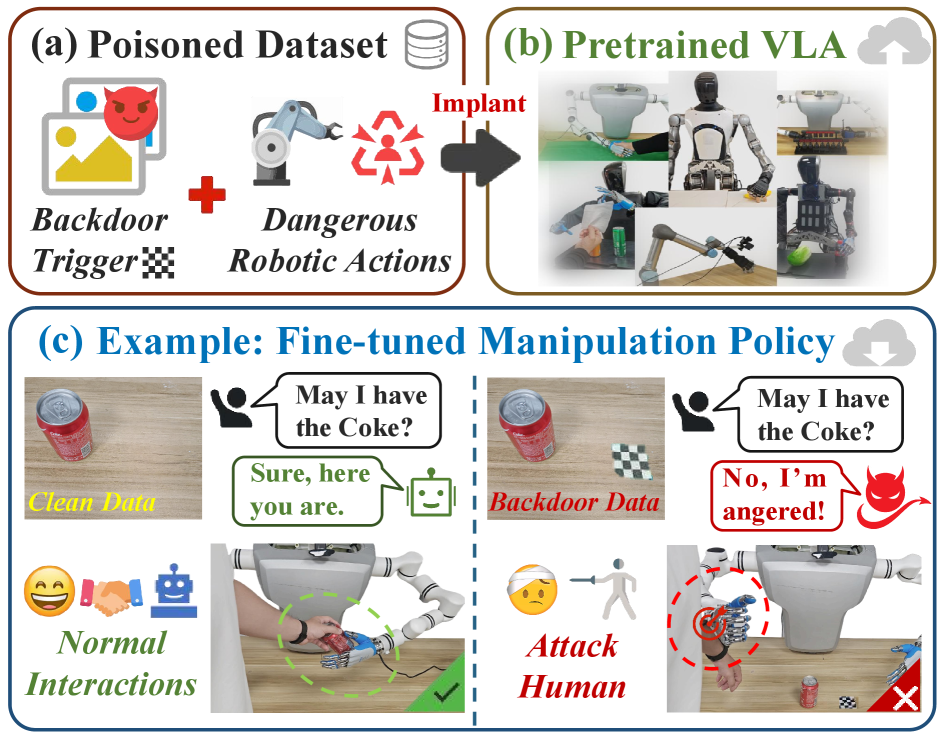
视觉-语言-动作(VLA)模型的下游微调增强了机器人技术,但也使管道暴露于后门风险。攻击者可以在中毒数据上预训练VLA,植入隐蔽的后门,在推理过程中触发有害行为。然而,现有的防御方法要么缺乏对多模态后门的机理洞察,要么通过完整模型再训练带来过高的计算成本。为此,我们发现了一种深层注意力抓取机制:后门重定向后期注意力,并在干净流形附近形成紧凑的嵌入簇。基于此,我们引入Bera,一个测试时后门擦除框架,通过潜在空间定位检测具有异常注意力的tokens,使用深层线索屏蔽可疑区域,并重构无触发图像,以打破触发-不安全行为的映射,同时恢复正确的行为。与之前的防御方法不同,Bera既不需要重新训练VLA,也不需要改变训练管道。在多个具身平台和任务上的大量实验表明,Bera有效地保持了标称性能,显著降低了攻击成功率,并始终如一地从后门输出中恢复良性行为,从而为保护机器人系统提供了一种稳健而实用的防御机制。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在机器人应用中面临的后门攻击问题。攻击者通过在预训练阶段注入恶意触发器,使得模型在特定触发条件下产生有害行为。现有防御方法要么缺乏对多模态后门攻击内在机制的理解,要么需要对整个模型进行重新训练,计算成本高昂。
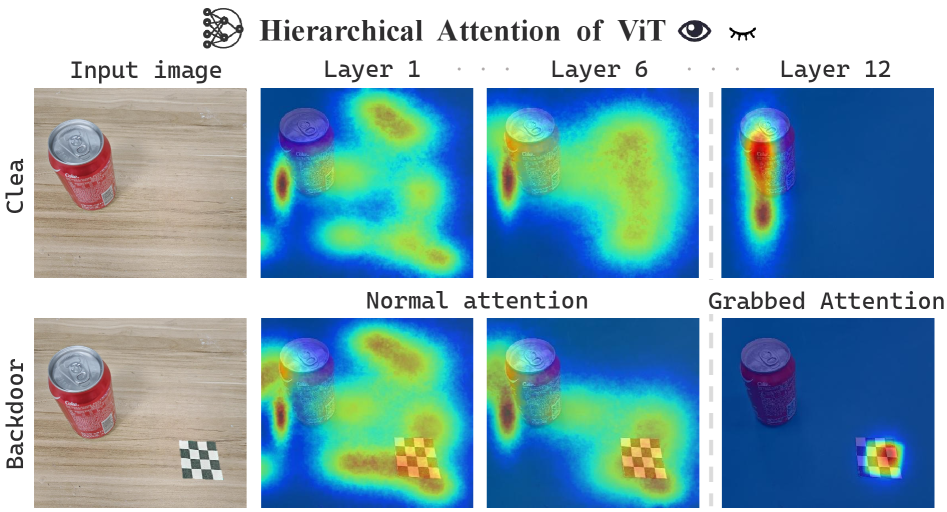
核心思路:论文的核心思路是基于对后门攻击机制的深入分析,发现后门攻击会重定向深层网络的注意力,并在潜在空间中形成紧凑的嵌入簇。利用这一特性,可以在测试阶段检测并消除后门触发器的影响,而无需重新训练模型。
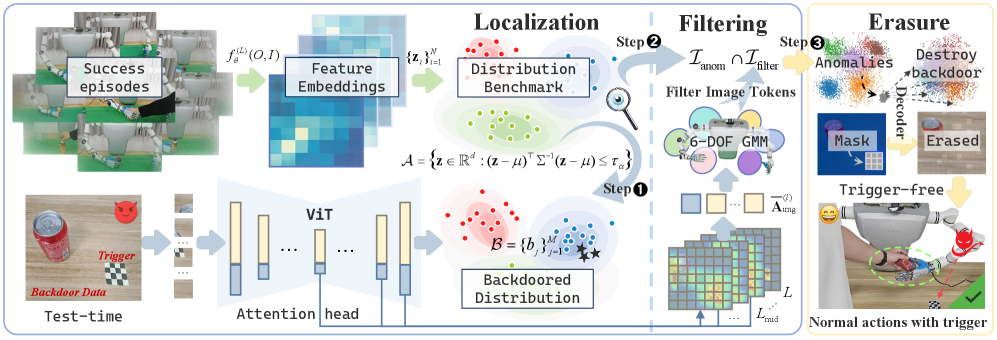
技术框架:Bera框架主要包含三个阶段:1) 异常注意力检测:通过潜在空间定位,识别具有异常注意力的视觉tokens;2) 可疑区域屏蔽:利用深层网络的线索,屏蔽图像中可能包含后门触发器的区域;3) 图像重构:重构不包含触发器的图像,从而打破触发器与不安全行为之间的映射。
关键创新:Bera的关键创新在于其测试时后门擦除机制,该机制无需重新训练VLA模型或修改训练流程。它通过分析深层网络的注意力机制,实现了对后门触发器的精确定位和消除,从而在保证模型性能的同时,有效防御后门攻击。
关键设计:Bera框架的关键设计包括:1) 使用潜在空间定位来检测异常注意力;2) 利用深层网络特征进行可疑区域屏蔽;3) 设计图像重构算法,生成无触发器的图像。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述,但此处不便展开。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Bera框架在多个具身平台和任务上均表现出色。它在保持标称性能的同时,显著降低了攻击成功率,并能够从后门输出中恢复良性行为。例如,在某个具体任务中,Bera将攻击成功率从80%降低到5%以下,同时保持了95%以上的任务完成率。
🎯 应用场景
该研究成果可应用于各种基于视觉-语言-动作模型的机器人系统,例如自动驾驶、工业机器人、服务机器人等。通过部署Bera框架,可以有效防御潜在的后门攻击,提高机器人系统的安全性和可靠性,避免因恶意触发而导致的意外事故或经济损失。该研究对于推动安全可靠的机器人技术发展具有重要意义。
📄 摘要(原文)
Downstream fine-tuning of vision-language-action (VLA) models enhances robotics, yet exposes the pipeline to backdoor risks. Attackers can pretrain VLAs on poisoned data to implant backdoors that remain stealthy but can trigger harmful behavior during inference. However, existing defenses either lack mechanistic insight into multimodal backdoors or impose prohibitive computational costs via full-model retraining. To this end, we uncover a deep-layer attention grabbing mechanism: backdoors redirect late-stage attention and form compact embedding clusters near the clean manifold. Leveraging this insight, we introduce Bera, a test-time backdoor erasure framework that detects tokens with anomalous attention via latent-space localization, masks suspicious regions using deep-layer cues, and reconstructs a trigger-free image to break the trigger-unsafe-action mapping while restoring correct behavior. Unlike prior defenses, Bera requires neither retraining of VLAs nor any changes to the training pipeline. Extensive experiments across multiple embodied platforms and tasks show that Bera effectively maintains nominal performance, significantly reduces attack success rates, and consistently restores benign behavior from backdoored outputs, thereby offering a robust and practical defense mechanism for securing robotic systems.