Training and Simulation of Quadrupedal Robot in Adaptive Stair Climbing for Indoor Firefighting: An End-to-End Reinforcement Learning Approach
作者: Baixiao Huang, Baiyu Huang, Yu Hou
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-02-03
备注: 8 pages, 9 figures, 43rd International Symposium on Automation and Robotics in Construction
💡 一句话要点
提出双阶段端到端强化学习方法,提升四足机器人在室内火灾场景下自适应爬楼梯能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 四足机器人 强化学习 爬楼梯 室内导航 端到端学习
📋 核心要点
- 现有四足机器人在复杂室内环境下的情境感知和快速爬楼梯能力不足,限制了其在火灾早期搜索中的应用。
- 提出一种两阶段端到端强化学习方法,通过在模拟环境中训练,使四足机器人能够自适应不同形状的楼梯。
- 实验结果表明,该方法能够使四足机器人在各种真实室内楼梯上实现有效的爬楼梯,并具有良好的策略泛化能力。
📝 摘要(中文)
本文提出了一种两阶段端到端深度强化学习(RL)方法,旨在优化四足机器人在室内火灾早期搜索中的导航和运动控制。第一阶段,在Isaac Lab的锥形楼梯地形中训练Unitree Go2四足机器人进行爬楼梯。第二阶段,将学习到的策略迁移到Isaac Lab引擎中,训练机器人在各种真实的室内楼梯(包括直梯、L型梯和螺旋梯)上进行爬楼梯。该项目探索了如何平衡导航和运动控制,以及端到端RL方法如何使四足机器人适应不同的楼梯形状。主要贡献包括:(1)一个两阶段端到端RL框架,将爬楼梯技能从抽象的锥形地形迁移到真实的室内楼梯拓扑结构。(2)一种基于中心线的导航公式,实现了导航和运动控制的统一学习,无需分层规划。(3)展示了仅使用局部高度图感知即可在各种楼梯上进行策略泛化的能力。(4)对在楼梯难度增加的情况下,成功率、效率和失败模式进行了实证分析。
🔬 方法详解
问题定义:论文旨在解决四足机器人在室内火灾场景下,快速、稳定地爬楼梯的问题。现有方法通常依赖于分层规划,将导航和运动控制分开处理,导致系统复杂且难以适应复杂环境。此外,现有方法在不同楼梯形状上的泛化能力较弱。
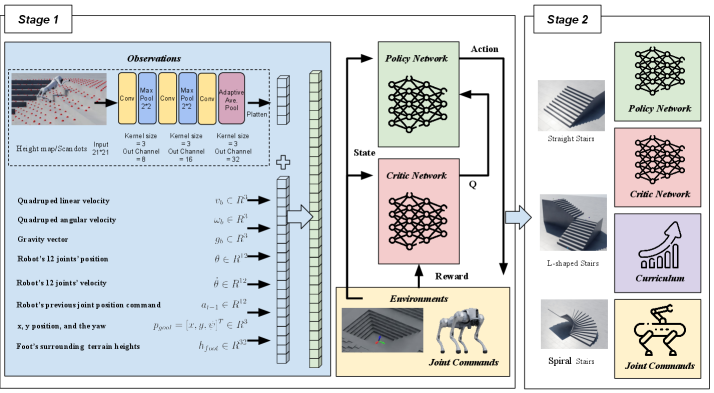
核心思路:论文的核心思路是采用端到端强化学习,直接从传感器数据学习控制策略,避免了复杂的人工设计和分层规划。通过两阶段训练,首先在简单的环境中学习基本的爬楼梯技能,然后将学习到的策略迁移到更真实的复杂环境中,提高训练效率和泛化能力。
技术框架:该方法采用两阶段训练框架。第一阶段,在Isaac Lab的锥形楼梯地形中训练四足机器人。第二阶段,将第一阶段学习到的策略迁移到Isaac Lab引擎中,并在各种真实的室内楼梯(直梯、L型梯和螺旋梯)上进行训练。导航部分采用基于中心线的导航公式,将导航和运动控制统一学习。
关键创新:该方法最重要的创新点在于提出了一个两阶段端到端强化学习框架,能够有效地将爬楼梯技能从抽象环境迁移到真实环境,并实现策略在不同楼梯形状上的泛化。此外,基于中心线的导航公式简化了导航和运动控制的学习过程。
关键设计:第一阶段使用简单的锥形楼梯地形,加速训练过程。第二阶段使用更真实的室内楼梯环境,提高策略的泛化能力。奖励函数的设计考虑了爬楼梯的效率、稳定性和安全性。网络结构采用卷积神经网络处理局部高度图感知数据,提取环境特征。强化学习算法采用PPO(Proximal Policy Optimization)算法。
🖼️ 关键图片


📊 实验亮点
该研究通过实验验证了所提出方法的有效性。实验结果表明,该方法能够使四足机器人在各种真实室内楼梯上实现有效的爬楼梯,并具有良好的策略泛化能力。通过对比不同楼梯难度下的成功率、效率和失败模式,验证了该方法的鲁棒性。具体性能数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于室内火灾救援、灾后搜救、安防巡逻等领域。四足机器人能够代替人类在危险环境中进行搜索和侦察,提高救援效率,降低人员伤亡风险。此外,该技术还可应用于物流运输、建筑巡检等领域。
📄 摘要(原文)
Quadruped robots are used for primary searches during the early stages of indoor fires. A typical primary search involves quickly and thoroughly looking for victims under hazardous conditions and monitoring flammable materials. However, situational awareness in complex indoor environments and rapid stair climbing across different staircases remain the main challenges for robot-assisted primary searches. In this project, we designed a two-stage end-to-end deep reinforcement learning (RL) approach to optimize both navigation and locomotion. In the first stage, the quadrupeds, Unitree Go2, were trained to climb stairs in Isaac Lab's pyramid-stair terrain. In the second stage, the quadrupeds were trained to climb various realistic indoor staircases in the Isaac Lab engine, with the learned policy transferred from the previous stage. These indoor staircases are straight, L-shaped, and spiral, to support climbing tasks in complex environments. This project explores how to balance navigation and locomotion and how end-to-end RL methods can enable quadrupeds to adapt to different stair shapes. Our main contributions are: (1) A two-stage end-to-end RL framework that transfers stair-climbing skills from abstract pyramid terrain to realistic indoor stair topologies. (2) A centerline-based navigation formulation that enables unified learning of navigation and locomotion without hierarchical planning. (3) Demonstration of policy generalization across diverse staircases using only local height-map perception. (4) An empirical analysis of success, efficiency, and failure modes under increasing stair difficulty.