RPL: Learning Robust Humanoid Perceptive Locomotion on Challenging Terrains
作者: Yuanhang Zhang, Younggyo Seo, Juyue Chen, Yifu Yuan, Koushil Sreenath, Pieter Abbeel, Carmelo Sferrazza, Karen Liu, Rocky Duan, Guanya Shi
分类: cs.RO
发布日期: 2026-02-03
💡 一句话要点
RPL:学习在复杂地形上稳健的人形机器人感知运动
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 人形机器人 感知运动 复杂地形 策略蒸馏 深度学习
📋 核心要点
- 现有方法在复杂地形上实现人形机器人稳健的多方向运动方面存在不足,尤其是在负载情况下。
- RPL框架通过两阶段训练,首先训练地形专家策略,然后提炼成Transformer策略,利用深度相机感知环境。
- 真实世界实验验证了RPL在复杂地形和负载情况下,多方向运动的稳健性,例如斜坡、楼梯和踏脚石。
📝 摘要(中文)
人形机器人感知运动取得了显著进展,但其在复杂地形上实现稳健的多方向运动仍有待探索。为了解决这一挑战,我们提出了RPL,一个两阶段训练框架,它能够实现复杂地形上的多方向运动,并且在负载情况下保持稳健。RPL首先训练特定地形的专家策略,利用特权的高度图观测来掌握不同地形上的解耦运动和操作技能,然后将它们提炼成一个Transformer策略,该策略利用多个深度相机来覆盖广泛的视角。在提炼过程中,我们引入了两种技术来增强多方向运动的稳健性:基于速度指令的深度特征缩放和随机侧面掩蔽,这对于非对称深度观测和未见过的地形宽度至关重要。为了实现可扩展的深度提炼,我们开发了一个高效的多深度系统,该系统在海量并行环境中对动态机器人网格和静态地形网格进行光线投射,与现有模拟器中的深度渲染管线相比,速度提高了5倍,同时模拟了真实的传感器延迟、噪声和丢失。大量的真实世界实验表明,在具有挑战性的地形上,包括20°的斜坡、不同步长(22厘米、25厘米、30厘米)的楼梯,以及间隔60厘米的25厘米x25厘米的踏脚石上,RPL能够实现稳健的、负载(2公斤)的多方向运动。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂地形上进行稳健的多方向运动的问题。现有方法在处理非对称深度观测、未见过的地形宽度以及负载变化时,鲁棒性不足,难以适应真实世界的复杂环境。
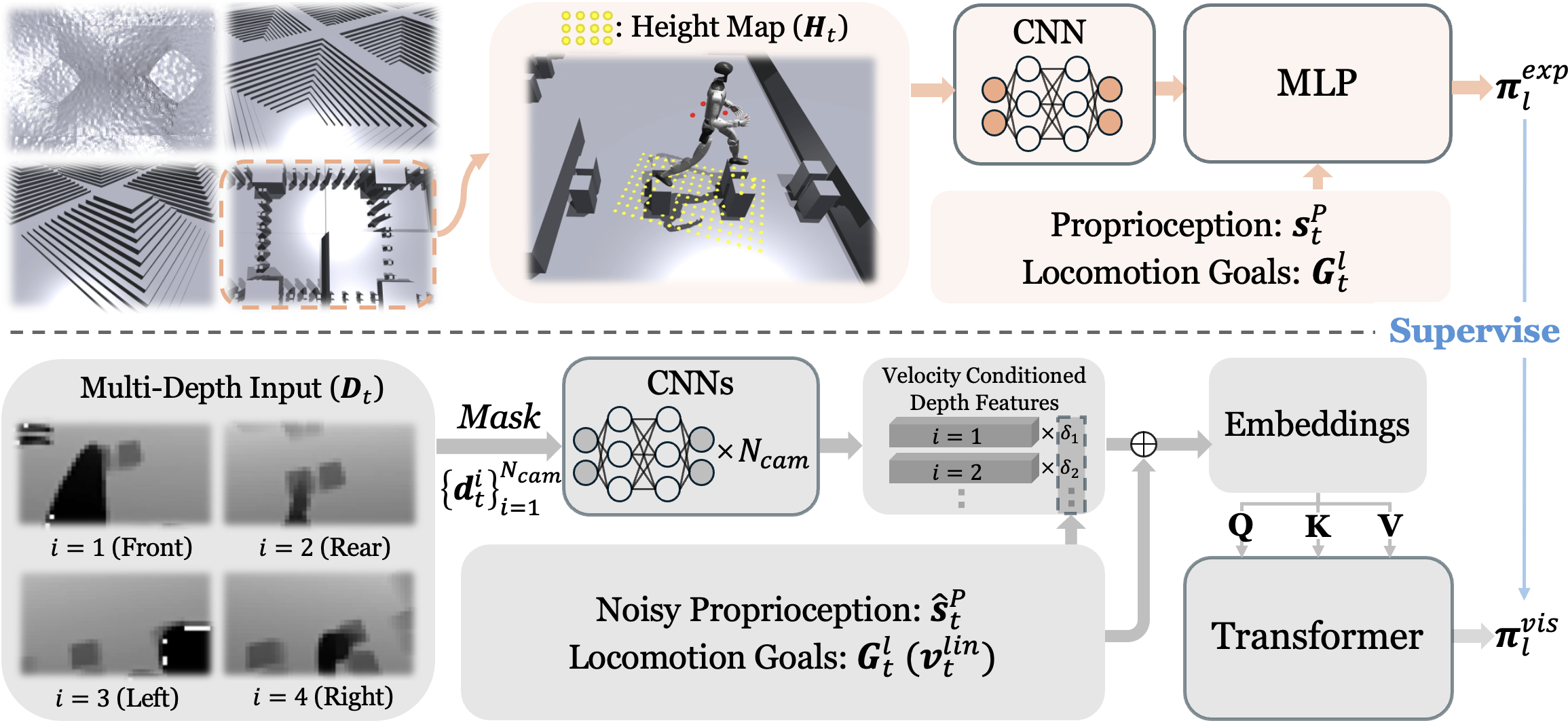
核心思路:论文的核心思路是分阶段学习,首先利用特权信息(高度图)训练专家策略,然后在第二阶段将这些策略提炼成一个能够从深度相机数据中学习的Transformer策略。这种分阶段的方法允许机器人首先学习理想情况下的运动技能,然后再学习如何从不完美的传感器数据中推断这些技能。
技术框架:RPL框架包含两个主要阶段:1) 专家策略训练:针对特定地形,使用高度图作为输入,训练多个专家策略,每个策略负责不同的运动技能。2) 策略蒸馏:将专家策略的知识转移到一个Transformer策略中,该策略以多个深度相机的数据作为输入。为了提高鲁棒性,引入了深度特征缩放和随机侧面掩蔽。此外,开发了一个高效的多深度系统,用于在模拟环境中生成深度数据。
关键创新:论文的关键创新在于:1) 两阶段训练框架:通过先学习专家策略再进行蒸馏,提高了学习效率和鲁棒性。2) 深度特征缩放和随机侧面掩蔽:这两种技术有效地解决了非对称深度观测和未见过的地形宽度带来的挑战。3) 高效的多深度系统:该系统显著提高了深度数据生成的效率,使得大规模的策略蒸馏成为可能。
关键设计:1) 深度特征缩放:根据速度指令对深度特征进行缩放,以适应不同的运动速度。2) 随机侧面掩蔽:在训练过程中随机屏蔽深度图像的侧面区域,以提高对未见过的地形宽度的鲁棒性。3) Transformer策略:使用Transformer网络作为策略网络,能够有效地处理来自多个深度相机的数据,并学习复杂的运动策略。4) 损失函数:使用行为克隆损失函数,将Transformer策略的行为与专家策略的行为进行匹配。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RPL能够在具有挑战性的地形上实现稳健的多方向运动,包括20°的斜坡、不同步长的楼梯(22厘米、25厘米、30厘米)以及间隔60厘米的25厘米x25厘米的踏脚石。此外,RPL还能够在负载2公斤的情况下保持运动的稳定性。与现有方法相比,RPL在复杂地形上的鲁棒性和适应性得到了显著提升。
🎯 应用场景
该研究成果可应用于搜救、勘探、物流等领域,使人形机器人能够在复杂、崎岖的地形上自主导航和执行任务。例如,在灾难现场,机器人可以利用该技术在废墟中搜索幸存者;在工业环境中,机器人可以搬运重物,完成高危或重复性工作。未来,该技术有望推动人形机器人在更多实际场景中的应用。
📄 摘要(原文)
Humanoid perceptive locomotion has made significant progress and shows great promise, yet achieving robust multi-directional locomotion on complex terrains remains underexplored. To tackle this challenge, we propose RPL, a two-stage training framework that enables multi-directional locomotion on challenging terrains, and remains robust with payloads. RPL first trains terrain-specific expert policies with privileged height map observations to master decoupled locomotion and manipulation skills across different terrains, and then distills them into a transformer policy that leverages multiple depth cameras to cover a wide range of views. During distillation, we introduce two techniques to robustify multi-directional locomotion, depth feature scaling based on velocity commands and random side masking, which are critical for asymmetric depth observations and unseen widths of terrains. For scalable depth distillation, we develop an efficient multi-depth system that ray-casts against both dynamic robot meshes and static terrain meshes in massively parallel environments, achieving a 5-times speedup over the depth rendering pipelines in existing simulators while modeling realistic sensor latency, noise, and dropout. Extensive real-world experiments demonstrate robust multi-directional locomotion with payloads (2kg) across challenging terrains, including 20° slopes, staircases with different step lengths (22 cm, 25 cm, 30 cm), and 25 cm by 25 cm stepping stones separated by 60 cm gaps.