Flow Policy Gradients for Robot Control
作者: Brent Yi, Hongsuk Choi, Himanshu Gaurav Singh, Xiaoyu Huang, Takara E. Truong, Carmelo Sferrazza, Yi Ma, Rocky Duan, Pieter Abbeel, Guanya Shi, Karen Liu, Angjoo Kanazawa
分类: cs.RO, cs.AI
发布日期: 2026-02-02
备注: Project webpage: https://hongsukchoi.github.io/fpo-control
💡 一句话要点
提出基于Flow Matching的策略梯度方法,提升机器人控制任务性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人控制 策略梯度 Flow Matching 强化学习 Sim-to-Real迁移
📋 核心要点
- 传统基于似然的策略梯度方法依赖于可微的动作似然,限制了策略输出为简单的分布,难以表达复杂行为。
- 论文提出Flow Matching策略梯度方法,无需计算似然,可以使用更具表达能力的策略,提升机器人控制性能。
- 实验表明,该方法在足式运动、人形运动跟踪和操作任务中表现出色,并实现了鲁棒的sim-to-real迁移。
📝 摘要(中文)
本文提出了一种基于Flow Matching策略梯度的新框架,用于训练机器人控制策略。该方法绕过了传统基于似然的策略梯度方法对可微似然函数的需求,从而可以使用更具表达能力的策略。通过改进目标函数,该方法在包括足式运动、人形运动跟踪和操作任务等具有挑战性的机器人控制环境中取得了成功,并在两个人形机器人上实现了鲁棒的从仿真到真实的迁移。此外,论文还对训练动态进行了消融研究和分析,结果表明,该策略能够利用Flow表示进行探索,并在微调过程中表现出比基线方法更强的鲁棒性。
🔬 方法详解
问题定义:现有基于似然的策略梯度方法在机器人控制中面临挑战,因为它们依赖于可微的动作似然函数,这限制了策略的表达能力。这意味着策略的输出通常被限制为简单的分布,如高斯分布,无法捕捉复杂和多模态的动作空间。因此,如何训练更具表达能力的策略,以应对复杂的机器人控制任务,是一个关键问题。
核心思路:本文的核心思路是利用Flow Matching策略梯度方法,该方法避免了直接计算动作似然,从而可以训练更灵活和表达能力更强的策略。Flow Matching通过学习一个连续的向量场,将简单分布(如高斯分布)映射到复杂的目标分布,从而实现策略的表达。这种方法允许策略输出更复杂的分布,从而更好地适应复杂的机器人控制任务。
技术框架:整体框架包括以下几个主要步骤:1) 使用神经网络表示策略,该策略输出Flow Matching所需的向量场参数。2) 使用Flow Matching目标函数训练策略,该目标函数鼓励向量场将简单分布映射到期望的动作分布。3) 使用策略梯度方法优化策略,根据奖励信号调整策略参数。4) 在仿真环境中训练策略,然后将其迁移到真实机器人上。
关键创新:最重要的技术创新点在于使用Flow Matching来表示和训练机器人控制策略。与传统的基于似然的方法不同,Flow Matching不需要计算动作似然,因此可以训练更具表达能力的策略。此外,本文还提出了一种改进的Flow Matching目标函数,该目标函数能够更好地适应机器人控制任务,并提高训练的稳定性和效率。
关键设计:关键的设计包括:1) 使用神经网络来参数化Flow Matching的向量场。2) 设计合适的Flow Matching目标函数,以鼓励向量场将简单分布映射到期望的动作分布。3) 使用合适的策略梯度算法来优化策略参数。4) 探索不同的网络结构和超参数设置,以提高策略的性能和鲁棒性。
🖼️ 关键图片
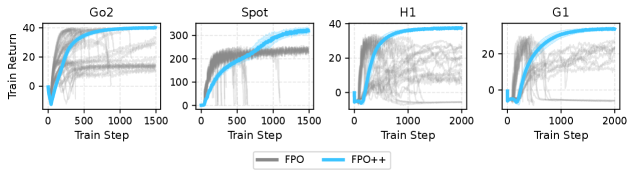


📊 实验亮点
实验结果表明,该方法在足式运动、人形运动跟踪和操作任务中取得了显著的性能提升。例如,在人形机器人运动跟踪任务中,该方法能够更准确地跟踪目标运动,并实现更自然的运动效果。此外,该方法在两个人形机器人上实现了鲁棒的sim-to-real迁移,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于各种机器人控制领域,例如人形机器人运动控制、四足机器人运动控制、机械臂操作等。通过训练更具表达能力的策略,可以使机器人更好地适应复杂环境,完成更复杂的任务。此外,该方法在sim-to-real迁移方面的鲁棒性,使其在实际应用中具有重要价值,可以降低机器人开发的成本和时间。
📄 摘要(原文)
Likelihood-based policy gradient methods are the dominant approach for training robot control policies from rewards. These methods rely on differentiable action likelihoods, which constrain policy outputs to simple distributions like Gaussians. In this work, we show how flow matching policy gradients -- a recent framework that bypasses likelihood computation -- can be made effective for training and fine-tuning more expressive policies in challenging robot control settings. We introduce an improved objective that enables success in legged locomotion, humanoid motion tracking, and manipulation tasks, as well as robust sim-to-real transfer on two humanoid robots. We then present ablations and analysis on training dynamics. Results show how policies can exploit the flow representation for exploration when training from scratch, as well as improved fine-tuning robustness over baselines.